
Quel type d'appareil photo choisir ?

Avant l'avènement du numérique, c'était simple. Mais ça, c'était avant. Il y avait les appareils photos compacts et les reflex. Les compacts faisaient sourire les possesseurs de reflex, et les propriétaires de petits reflex enviaient les propriétaires de gros reflex, souvent réservés aux professionnels et amateurs éclairés.
L'arrivée du numérique en 1996 a rebattu les cartes. Avec de nouveaux type d'appareils et une révolution qui s'annonce pour ce monde nouveau. Les constructeurs traditionnels que sont Canon, Nikon ou Pentax ont vu leur marché attaqué par de nouveaux acteurs : Panasonic et son Lumix G1 en 2008, Samsung et son hybride NX10 en 2010 ou encore Sony et son hybride NEX-5. Notons l'apparition à cette même époque d'Instagram...une « app » sur smartphone qui fait des photos ! Fujifilm est lui aussi entré sur le marché en 2012 avec ses excellents X-T. Nikon a bien essayé de réagir avec son J1 en 2011, Canon en 2012 avec son premier EOS M, mais ces fabricants traditionnels ont pris bien du retard.
Peut-être trop tard d'ailleurs, car certains pensent que le marché « grand public » des appareils photographiques, numériques ou pas, connectés ou non, est bientôt mort. Mais le pire n'est jamais certain. Les innovations et les nouvelles fonctions déboulent à toute allure dans nos appareils photo et cela peut redonner du peps à ce marché un peu en berne et à tous les amateurs de belles images.
Alors si vous cherchez un appareil photo mais vous sentez un peu perdu, voici un article pour faire le tri.
Les 4 grandes catégories d'appareils photo
Il existe de nos jours quatre grandes catégories d’appareils photo grand public :
-
les compacts
-
les bridges,
-
les reflex,
-
les hybrides
 Les appareils photo compacts sont les modèles les plus petits et les moins onéreux. Ils disposent d’objectifs fixes, c'est à dire qu'il n’est pas possible de remplacer l’objectif par un autre. La plupart du temps, l'objectif est constitué d'un zoom, qui se replie sur lui-même lorsque le compact n’est pas utilisé.
Les appareils photo compacts sont les modèles les plus petits et les moins onéreux. Ils disposent d’objectifs fixes, c'est à dire qu'il n’est pas possible de remplacer l’objectif par un autre. La plupart du temps, l'objectif est constitué d'un zoom, qui se replie sur lui-même lorsque le compact n’est pas utilisé.
Leur principal avantage est leur compacité et leur simplicité. Ils peuvent tenir dans une poche de pantalon et sont facilement transportables. En contrepartie, ils donnent des photos de piètre qualité, surtout en faible lumière et ne sont pas très réactifs. Entre le moment où vous déclenchez et où la photo est prise, il y a un certain temps, voire un temps certain. La mise au point est plus lente (ce qi engendre un risque de flou) et le flash se déclenche souvent de façon automatique avec une nette tendance à produire des photos peu esthétiques.
Il est de plus en plus supplanté par le smartphone, qui a la même taille et fait désormais de bien meilleures photos (surtout l'iPhone X et le Galaxy S8), car bien aidés par leurs logiciels, tout en étant largement plus polyvalents (il leur manque encore la fonction brosse à dent pour être parfait). Bref, si vous achetez aujourd'hui un appareil photo compact, sachez qu'il y a beaucoup mieux, plus polyvalent et mieux connecté, votre smartphone.

Les appareils photo bridge sont entre le compact et le reflex. Ils ont un objectif fixe, comme le compact, mais beaucoup plus performant. Cette performance se fait au détriment de l'encombrement qui les rapproche des réflex. Ils disposent également de fonctions avancées (modes manuels, etc.), comme les réflex. Mais contrairement à ces derniers, ils ont un viseur électronique et non un viseur optique. L'image qui s'affiche dans le viseur est une reproduction 2D de la réalité.
Le nom vient de l'anglais « bridge » qui signifie « pont » en français, car les bridges sont en quelque sorte la jonction entre les compacts et les reflex.
Les bridges ont connus un certain succès, car plus simples et moins chers que les réflex, plus performants que les compacts mais ils sont maintenant largement supplantés par les hybrides, qui sont d'une taille plus petite, plus performants, et qui ont l'avantage d'avoir des optiques interchangeables. Tout cela pour le même prix.
Bref, si vous achetez aujourd'hui un bridge, sachez qu'il y a mieux, mais alors pour le coup vraiment mieux, mais que c'est moins cher. Pour le dire autrement, si vous souhaitez encore acheter aujourd'hui un bridge, il vous faut absolument lire cet article.
 Les appareils photo réflex mono-objectif sont ce qui se fait (ou se faisaient jusqu'à présent ?) de mieux dans la gamme grand public. Ils sont munis d'un capteur numérique de grande taille - voir ci-après pour les détails mais un capteur plus c'est grand mieux c'est -, d'une visée reflex, c'est à dire une visée à travers l'objectif, l'image se réfléchissant dans un penta-prisme - la photo prise correspond donc exactement à ce que l'on voit dans l'objectif -, et ils sont très polyvalents car ils permettent de changer d'objectifs (à condition d'avoir plusieurs objectifs naturellement).
Les appareils photo réflex mono-objectif sont ce qui se fait (ou se faisaient jusqu'à présent ?) de mieux dans la gamme grand public. Ils sont munis d'un capteur numérique de grande taille - voir ci-après pour les détails mais un capteur plus c'est grand mieux c'est -, d'une visée reflex, c'est à dire une visée à travers l'objectif, l'image se réfléchissant dans un penta-prisme - la photo prise correspond donc exactement à ce que l'on voit dans l'objectif -, et ils sont très polyvalents car ils permettent de changer d'objectifs (à condition d'avoir plusieurs objectifs naturellement).
Trois qualités jusque là incontournables qui faisaient presque oublier leurs petits défauts : un encombrement important (pour partie lié au nombre d'objectifs à transporter, et pour partie lié à la taille du boîtier lui-même), un poids non négligeable, et un prix des plus canons (hou le vilain jeu de mot) tant du fait du boîtier lui-même que des multiples objectifs à acheter.
Il va sans sire que les réflex disposent de nombreux modes de prises de vue, allant du tout automatique (pour le débutant) aux réglages complètement manuels autorisant une créativité totale, en passant par la priorité à la vitesse ou à l'ouverture. Ce qui leur confère une grande puissance mais qui les fait apparaître comme complexes à maîtriser, avec d'innombrables boutons dans tous les sens.
 L'appareil photo hybride est le dernier né des appareils photos numériques. Il tient son nom du fait qu'il tient à la fois de l'appareil photo compact (il est petit comme un compact et dispose comme lui d'une visée électronique, assurée par l'écran et/ou par un viseur électronique) et du réflex avec ses objectifs interchangeables. On aurait pu l'appeler Bridge, mais le nom était déjà pris.
L'appareil photo hybride est le dernier né des appareils photos numériques. Il tient son nom du fait qu'il tient à la fois de l'appareil photo compact (il est petit comme un compact et dispose comme lui d'une visée électronique, assurée par l'écran et/ou par un viseur électronique) et du réflex avec ses objectifs interchangeables. On aurait pu l'appeler Bridge, mais le nom était déjà pris.
En fait, un hybride, c'est un peu comme un réflex en modèle réduit. La seule grosse différence technique est la visée, optique pour le réflex, numérique pour l'hybride. Ce dernier n'a pas besoin de ce fameux miroir (on dit mirrorless en anglais) propre au réflex qui permet de rediriger le lumière vers le viseur optique via le penta-prisme. L'hybride affiche lui généralement l'image à travers son écran, et pour certains modèles à travers un viseur numérique. C'est assez proche du viseur optique mais évidemment l'image qui s'affiche n'est qu'une reproduction de la réalité.
Mais l'hybride propose plus que le réflex, englué dans ses certitudes de leader. Il permet de filmer bien mieux qu'un réflex, dispose d'un écran tactile (ce qui le rend facile et rapide d'utilisation dans ses réglages) qui permet notamment de modifier la zone de mise au point AF directement depuis l'écran. Alors que sur un réflex, il faut activer le menu et faire tourner la molette jusqu'à sélectionner la bonne zone de cadrage, la sélectionner et enfin recadrer...Si le sujet n'a pas bougé entre temps, vous pouvez être content !
En conclusion, oubliez les compacts (préférez votre smartphone qui est de plus connecté et automatise les traitements d'images), les bridges (les hybrides sont au même prix et bien meilleurs) et faites votre choix entre les réflex et les hybrides. Même si la vérité m'oblige à le dire, l'hybride devrait gagner la bataille face au réflex. Souvent plus petit, tout aussi polyvalent, et (enfin) de même qualité, il offre des fonctions plus avancées tel que le tactile, la vidéo 4K et les traitements de l'image. Même si le réflex garde pour lui l'avantage de la visée optique (ce qui n'est pas rien) et sa réputation de matériel de professionnel (ce qui est encore quelque chose).
Bon, nous venons de faire un 50/50, mais comment faire notre choix entre un réflex ou un hybride ?
Les critères de choix
Aujourd'hui, ce n'est plus le triptyque « taille du capteur, visée réflex, optiques » qui compte, mais plutôt celui de « taille du capteur, optiques, logiciel de traitement d'images ». Ce n'est d'ailleurs pas toujours sur ces points que les fabricants communiquent, et c'est dommage ; mais il faut dire que c'est parfois un peu difficile à expliquer. Alors que communiquer sur un nombre de pixels, c'est bien plus facile. Regardons donc de plus près de quoi il retourne.
-
Le viseur, optique ou électronique
-
Les optiques (objectifs)
Au temps de l'argentique, on utilisait une pellicule photo, le plus souvent au format 135. Ce qui pouvait donner des images d'une taille de 24 × 36 mm ou plus rarement de 18 × 24 mm. Le format 24 x 36 est donc resté le format de référence, même quand les appareils photos sont passés au numérique. Et c'est ce format qui est utilisé comme étalon de nos capteurs numériques. On peut donc avoir des capteurs plus grands (le moyen format), plus petit (APS-C, 4/3, etc.) ou au plein format (full frame). Mais pourquoi la taille du capteur importe t-elle ?
Il faut savoir que :
-
Plus le capteur est grand, plus la profondeur de champ diminue : un appareil à grand capteur permet donc d’isoler un sujet par la création d’un flou d’arrière plan. Un grand capteur, c'est donc mieux pour faire des portraits (mais pas que). Nos smartphones ont de tout petits capteurs. Et ils font ainsi des photos nettes de zéro à l'infini. Impossible de créer de flou d'arrière plan.
-
Plus le capteur est grand, plus l’effet de flou est réussi. L’effet de flou, que l’on appelle également l’effet Bokeh (boke signifiant flou en Japonais) est créé par la transition entre les zones nettes et floues dans l’image. Elle sera plus douce et plus progressive sur un appareil plein format (en 24×36 mm donc) que sur un capteur plus petit.
-
Plus le capteur est grand, plus sa dynamique et sa sensibilité ISO augmentent. La dynamique d’un capteur est sa capacité à enregistrer une scène dont le contraste est fort (c’est à dire la différence entre les zones les plus claires et les plus foncées). Avec une faible dynamique, vous devrez choisir entre boucher les ombres ou cramer les blancs. La dynamique et la sensibilité ISO sont liées à la taille des photosites qui composent le capteur (ce sont ces éléments qui transforment la lumière en courant électrique). Sur un petit capteur, les photosites sont plus petits (logique) que sur les grands, et ils captent donc moins de lumière. Le signal électrique qu’ils fournissent doit par conséquent être amplifié. C’est cette amplification qui est à l’origine du bruit numérique (ces petits points colorés qui gâchent la photo) et de la perte de détails que vous pouvez voir sur vos images lorsque vous la regardez en grande taille. Un grand capteur sera donc plus performant sur des zones contrastées (entre ombres et plein lumière) ou en faible lumière (comme la nuit).
-
Plus le capteur est grand, plus il peut contenir de photosites et donc de pixels. Un moyen format peut ainsi avoir de 16 à 100 Mégapixels, alors qu'un plein format ne dépasse pas les 50 Mégapixels (à ce jour). Notez qu'on peut trouver des capteurs 4/3, APS-C, plein format et moyen format avec le même nombre de pixels. Ce qui veut dire qu'ils ont le même nombre de photosites mais que sur les grands capteurs (plein et moyen formats), les photosites sont beaucoup plus grands et offriront donc une plus petite profondeur de champ, un meilleur flou, une meilleure dynamique...A résolution égale, un grand capteur offre donc de bien meilleures performances qu'un petit. Rien ne sert de comparer le nombre de pixels au final...
Mais
-
plus le capteur est grand, moins on zoome loin. Pour faire des photos animalières, mieux vaut un capteur APS-C, plus petit qu'un plein format, car il permettra de zoomer plus loin. Cet effet de zoom s'explique par la zone d'image du capteur. Sur un APS-C, tel que ci-dessous, on voit que la zone est plus petite. Restituée sur une même taille d'écran, on "zoome".
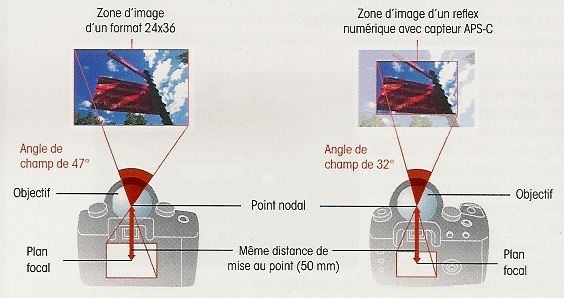
Avec un capteur APS-C, et avec la même longueur de focale optique, on obtient donc une image agrandie. On introduit donc un coefficient de conversion focale entre un capteur plein format et les autres capteurs. Ainsi, un capteur APS-C de chez Nikon aura un coefficient de 1,5. Un objectif de 50 mm sera donc équivalent à un objectif de 75 mm quand il sera couplé à ce capteur. -
plus le capteur est grand, plus il est cher. Pour baisser les prix et rendre les APN abordables, les fabricants ont donc simplement réduit la taille des capteurs.
-
plus le capteur est grand, plus les optiques sont grosses et pesantes. Pour voyager, mieux vaut un petit format qu'un grand...
Le tableau ci-dessous liste les principales tailles de capteurs, leur dimension, et leur coefficient de conversion focale.
| Taille du capteur appellation |
Dimensions (en mm) | Superficie mm2 |
Rapport d'image | Coefficient de conversion focale | ||
| hauteur | largeur | diagonale | ||||
| 1/3″ | 3,6 | 4,8 | 6 | 17,3 | 4/3 (1,33) | 7,2 |
| 1/2,5″ | 4,29 | 5,76 | 7,2 | 24,7 | 1,34 | 6 |
| 1/2,3’’ | 4,5 | 6,2 | 7,7 | 27,9 | 1,38 | 5,6 |
| 1/1,7’’ | 5,7 | 7,6 | 9,5 | 43,3 | 4/3 (1,33) | 4,6 |
| 2/3’’ | 6,6 | 8,8 | 11 | 58,1 | 4/3 (1,33) | 3,9 |
| 1’’ | 8,8 | 13,2 | 15,9 | 116,2 | 3/2 (1,5) | 2,7 |
| Micro 4/3 | 13 | 17,3 | 21,6 | 224,9 | 4/3 (1,33) | 2 |
| 1,5’’ | 14 | 18,7 | 23,4 | 261,8 | 1,34 | 1,9 |
| APS-C 1,6x (canon) | 14,9 | 22,3 | 26,8 | 332,3 | 3/2 (1,5) | 1,6 |
| APS-C 1,5x (nikon) | 15,7 | 23,7 | 28,4 | 372,1 | 3/2 (1,5) | 1,5 |
| APS-H | 18,6 | 27,9 | 33,5 | 518,9 | 3/2 (1,5) | 1,3 |
| Plein format (Full Frame) |
24 | 36 | 43,3 | 864 | 3/2 (1,5) | 1 |
| Moyen format |
33 | 44 | 55 | 1452 | 4/3 (1,33) | 0,8 |
| 40,4 | 53,7 | 67,2 | 2169,5 | 4/3 (1,33) | 0,6 | |
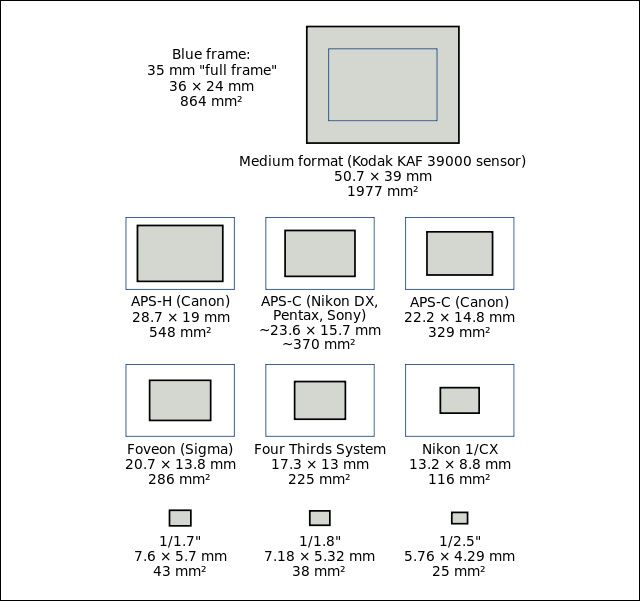
Les tableaux de chiffres n'étant pas très parlant, voici une image qui permet de mieux comprendre le rapport de taille entre capteurs. En trait bleu, l'étalon plein format de 24 x 36 mm, en noir, à l'extérieur ou à l'intérieur du cadre bleu, le format comparé. Vous pouvez constater que les capteurs 1/2,5" et 1/1,8" couramment utilisés dans les smartphones sont ridiculement petits par rapport au plein format.
Le tableau ci-après vous donne justement dans quel type d'appareil on trouve généralement ces capteurs. Avec quelques exemples qui vous permettront de savoir quel taille de capteur vous avez.
| Taille du capteur appellation |
Utilisation générale | Exemples |
| 1/3″ | APN compacts d’entrée de gamme, smartphones haut de gamme | Nikon COOLPIX S33 Smartphones iPhone 6 et 7 |
| 1/2,5″ | Smartphones Huawei P9, Honor 8, Samsung Galaxy S7, LG G5 (1/2,6″) | |
| 1/2,3’’ | Appareils photo compacts et bridges grand public, smartphones haut de gamme | Compact Canon Ixus 175, 285 HS, Powershot SX420, SX540, SX620 Nikon Coolpix A10, A100, A300, A900, B500, B700 Compact Olympus Tough TG-4, Sony DSC-HX90 Bridge Panasonic FZ200, FZ300 / Compact Panasonic Lumix FZ72, TZ40, TZ57, TZ60, TZ61, TZ70, TZ71, TZ80, TZ81, TZ7 (1/2,33″) Bridge Sony Cyber-Shot DSC-H400, HX400, Compact Sony Cyber-Shot HX60, HX90, WX220, WX350 Smartphone HTC 10, Google Pixel |
| 1/1,7’’ | APN compacts experts de taille réduite | Compact Canon PowerShot S120, N100, Nikon Coolpix P340, Panasonic LF1, Pentax MX-1 |
| 2/3’’ | Fujifilm X30, Fujifilm XQ2 | |
| 1’’ | Appareils photo compacts, bridges experts et hybrides | Compacts Canon G3X G5X, G7X I et II, G9X Hybride Nikon 1 J5 Compact Panasonic TZ100, TZ101, LX15/ Bridge Panasonic Lumix FZ1000, FZ2000 / Compacts Sony RX100 (toute la série) / Bridge Sony RX10 (toute la série) |
| Micro 4/3 | Appareils photo hybrides micro 4/3, compact experts | Hybride Olympus OM-D E-M10 II, E-M5 II, E-M1 E-M1 II, Olympus Pen F, E-PL7 Hybride Panasonic Lumix G6, G7, G70, G80, GM5, GX8, GX80, GH4, GF7 / Compact expert Panasonic Lumix LX100 |
| 1,5’’ | Compacts experts | Compact expert Canon PowerShot G1 X, G1 X Mark II |
| APS-C 1,6x | APN hybrides et reflex Canon | Reflex Canon EOS 7D, 7D Mark II, 60D, 70D, 80D, 100D, 650D, 700D, 750D, 760D, 1100D, 1200D, 1300D… / Hybride Canon EOS M, M3, M5 |
| APS-C 1,5x | Autres hybrides et reflex, compacts experts | Leica T, Ricoh GR II Reflex Nikon D300S, D3200, D3300, D3400, D5200, D5300, D5500, D7000, D7100, D7200, D500 Pentax K-S2, K-50, K-70, K-3 II Fujifilm X-E2s, XT-1, XT-2, XT-10, X-Pro2 Hybride Sony Alpha 5000, 6000 / Hybride Fuji X-A3, Compact X70, X100T / Sony Alpha 58, 68, 77, 77 II, 6300 Sigma dp (dp0, 1, 2 et 3), sd1, sd quattro |
| APS-H | Format actuellement délaissé | Reflex Canon EOS 1D Mark IV |
| Plein format (Full Frame) |
Reflex, hybrides et certains compacts | Canon 6D, 5D (toute la série), 5Ds, 1DX, 1DX Mark II Leica SL, Q Nikon D3, D4, D5, D600, D610, D700, D750, Df, D800, D810 Pentax K-1 Sony Alpha 7, 7R, 7S, 7 II, 7R II, 7S II, 99, 99 II, compact Sony RX1R II |
| Moyen format |
Appareils photo moyen format | Fujifilm GFX (32,9 x 43,8mm), Hasselblad H5D-50c, H6D-50c, X1D-50c (32,9 x 43,8mm), Leica S type 007 (30×45 mm) Pentax 645Z, PhaseOne IQ3 50MP, IQ1 50MP |
| Hasselblad H6D-100c (40 x 53,4mm) PhaseOne IQ3 100MP, IQ3 80MP, IQ1 100MP, IQ1 80MP, IQ2 60MP Acromatic |
Les capteurs plein format ont été réservés un temps aux réflex professionnels mais on trouve désormais des capteurs plein format dans chaque catégorie d'appareils grand public, réflex et hybride. On ne peut donc départager ces deux catégories sur ce critère, mais gardez à l'esprit les avantages de chacun, cela vous permettra d'orienter vos choix vers les plus grands capteurs qui restent quand même bien meilleurs que les petits.
Le viseur, optique ou numérique
Comme je vous l'ai dit, la visée réflex n'est plus vraiment un critère de choix. Mais je vous explique quand même rapidement pourquoi elle le fût et pourquoi elle n'est plus aussi déterminante.
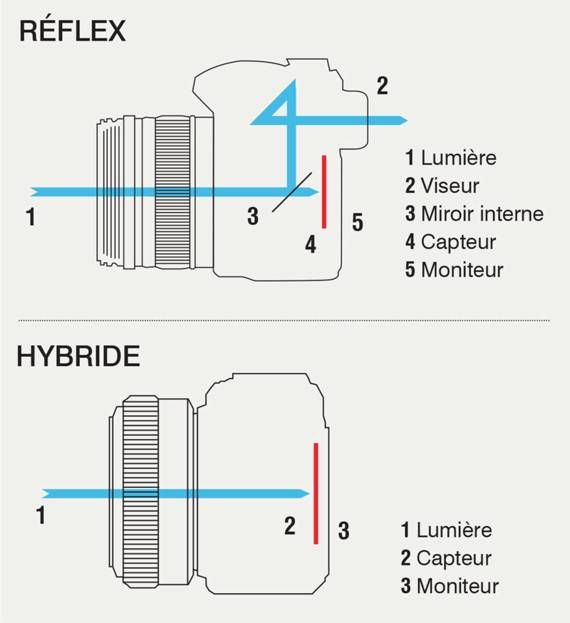
Avec une visée optique, la lumière passe dans l'objectif, se réfléchit dans le miroir, rebondit dans le penta-prisme avant de ressortir dans le viseur. Elle ne sera traitée par le capteur que lors du déclenchement, après que le miroir s'est relevé. Et on pourra visualiser la photo à l'écran. Avec une visée électronique, la lumière passe dans l'objectif, est interceptée par le capteur qui la transmet au processeur pour traitement et affichage sur l'écran ou dans le viseur électronique. C'est simple. Il suffit d'appuyer pour que le capteur mémorise l'image. Examinons les principaux avantages et inconvénients de ces 2 technologies.
Avantages du viseur optique
-
Il est très réactif : en fait, il n’y a pas de délai à l’affichage (car pas de traitement) comme avec certains viseurs électroniques et pas de fluctuation de l’image non plus. C'est notamment important si vous aimez faire des photos de sport ou d'actions.
-
Avec un viseur optique vous voyez la scène comme au travers d’une vitre, en 3D, et non comme sur un écran de télévision, en 2D.
-
On peut visualiser la scène sans avoir besoin d'allumer l'appareil, ce qui permet d'avoir des batteries qui tiennent beaucoup plus longtemps que pour les hybrides (plusieurs jours versus plusieurs heures).
Inconvénients du viseur optique
-
Ce que vous voyez dans le viseur n’est pas nécessairement ce que vous aurez sur la photo. Si vous disposez d’un viseur couvrant 100% de la scène photographiée, alors ce que vous voyez est bien identique à ce que vous aurez sur la photo. Si le viseur a une couverture inférieure (par exemple 90% à 98%) comme c'est le cas de la plupart des viseurs optiques, alors ce que vous voyez est une zone plus réduite que ce que vous aurez sur la photo.
-
Par ailleurs on ne voit pas la photo telle qu'elle sera mais telle qu'elle serait avec le diaphragme ouvert au maximum (sauf si vous avez un bouton pour tester la profondeur de champ et que vous pensez à vous en servir)
-
Le contrôle de l'exposition est difficile car on ne peut afficher l'histogramme en surimpression comme sur un écran électronique (voir ci-après).
-
Le viseur optique est quasi inutilisable pour la vidéo : lorsque l’on enregistre, le miroir reste ouvert tout le temps. Il faut alors viser à l’aide de l’écran LCD, ce qui n’est pas toujours l’idéal, surtout en plein soleil
Avantages du viseur électronique
-
Le viseur électronique est moins complexe que le viseur optique et offre donc des gains de place et de poids évidents (pas de miroir réfléchissant qui bascule ni de penta-prisme).
-
Avec un viseur électronique, l’image affichée correspond exactement au résultat que vous obtiendrez lorsque vous déclencherez. Le viseur couvre en effet 100% de la scène photographiée et le processeur a déjà traité l'image. Si vous avez décidé de faire une photo en noir et blanc, l'image s'affichera à l'écran en noir et blanc. Avant même que vous n'ayez déclenché. Cela permet notamment de juger directement des contrastes. De même, si vous corrigez l'exposition ou la balance des blancs manuellement, l'image affichée reflètera la correction.
-
Vous pouvez visualiser tous les réglages appliqués à la prise de vue en cours, en surimpression sur l'écran ou dans le viseur (mise au point, balance des blancs, exposition, cadrage, histogramme, etc.). Et, cerise sur la gâteau, il est possible de changer rapidement un paramètre, sans quitter l'oeil du viseur, contrairement à un viseur optique L'un des points les plus discriminants est l'histogramme, car aucun viseur optique ne saura l'afficher. L'histogramme vous permet de contrôler finement la bonne exposition de votre photo. Un histogramme ressemble à çà :
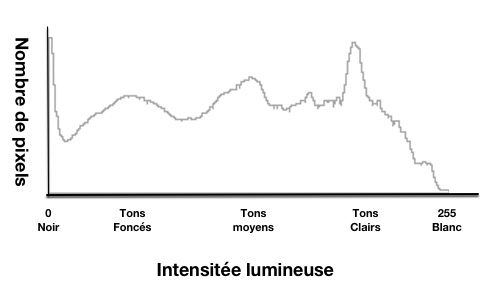
L’axe des abscisses (horizontal) représente la répartition des tons, allant du noir à gauche jusqu’au blanc tout à droite.
L'axe des ordonnées (vertical) représente la quantité de pixels pour chaque ton. Autrement dit, plus un ton possède une valeur importante, plus il est présent sur la photo.
L’histogramme d’une photo correctement exposée doit former une courbe gaussienne, des tons noirs aux tons blancs. Si la courbe est collée à gauche, c'est qu'elle est probablement sous-exposée (trop de pixels dans le noir) et si elle est collée à droite, elle est probablement surexposée (trop de pixel blancs). A moins que ce ne soit évidemment un effet voulu et recherché. De la même façon, si la courbe plafonne vers le haut, cela signifie que vous avez perdu des informations, car il manque des pixels pour représenter vos tonalités. D'une manière générale, la courbe doit tenir dans le cadre sans le toucher, à droite comme à gauche comme en haut.
-
Il existe bien d'autres fonctions très sympathiques d'enrichissement de l'image dans le viseur : le viseur électronique permet d’effectuer une mise au point très précise grâce à la fonction "focus peaking" qui surligne les zones nettes de l’image ainsi que la possibilité de définir la zone d'auto-focus via l'écran tactile.
-
Le viseur numérique reste utilisable pour la vidéo : le viseur électronique (s'il y en a un, en plus de l'écran) affiche la scène même lorsque le capteur enregistre. Il est ainsi possible de filmer en cadrant à l’aide du viseur. Et l'écran est généralement pivotant, ce qui peut vous aider à cadrer.
Inconvénients du viseur électronique
-
La visée électronique est souvent moins réactive que la visée optique. L’écran a toujours un léger temps de retard par rapport au viseur optique, la mise au point est plus lente, vous avez donc un risque plus grand de rater vos photos. Surtout s'il s'agit de photos de sport ou d'actions, où la vitesse compte. Mais ce manque de fluidité a tendance à devenir imperceptible dans les viseurs haut de gamme.
-
Comme il faut afficher l'image sur l'écran, l’appareil doit obligatoirement être allumé pour que la visée fonctionne. Et un écran, cela consomme de la batterie. L’autonomie d’un appareil photo avec viseur électronique ne dépasse donc que rarement les 280 à 400 images (contre 1 200 pour un réflex). Il vaut mieux acheter une seconde batterie, voire ne 3ème pour être sûr de ne jamais tomber en panne sèche. Conservez-en 2 sur vous, la troisième se rechargeant...
Comme on vient de le voir, le viseur numérique est bourré d'avantages. Son seul inconvénient majeur étant le manque de réactivité qui peut éventuellement le disqualifier pour la photographie sportive. Rien ne vaut dans ce cas un bon viseur optique. Ce dernier est encore l'apanage des réflex, même si certains hybrides haut de gamme commencent à s'aventurer dans ce domaine. Si la visée optique reste un facteur important pour vous, il faut alors choisir un réflex plutôt qu'un hybride. Sinon vous avez encore le droit d'hésiter.
La densité minimum des points imprimés pour obtenir une très bonne image vue de près est de 300 dpi (dots per inch, c'est-à-dire « points par pouce ») en admettant qu'un point imprimé est égal à un pixel. Voici ce que cela donne approximativement pour quelques formats classiques :
-
10x15 cm = 2,10 millions de pixels (la taille de papier photo standard);
-
13x18 cm = 3,264 millions pixels ;
-
18x24 cm = 6 millions de pixels ;
-
20x30 cm = 9,5 millions de pixels (la taille d'une feuille A4)
Il est donc évident que le nombre de pixels des capteurs modernes (16, 24, 42 mégapixels...) excède très largement les besoins réels de la majorité des utilisateurs et du grand public. Mais le nombre de pixels fait vendre, car on a l'impression que plus on en a, mieux c'est. Alors qu'il vaut mieux dépenser son argent dans un grand capteur que dans un tas de pixels jamais exploité.
Les reflex existant depuis plusieurs décennies, ils bénéficient donc d'un parc optique particulièrement pléthorique. Focales fixes ou zooms, téléobjectifs ou grand-angle voire fisheye, optiques macro, stabilisées, à grande ouverture... on peut se perdre dans les catalogues des objectifs pour réflex. Alors que ceux destinés aux hybrides ne demandent qu'à s'étoffer. Ils se développent néanmoins rapidement ; En vous concentrant sur l'essentiel, vous trouverez forcement objectif à votre hybride.
A noter que Panasonic, un des leaders de l'hybride, bénéficie de la conception des objectifs Leica, dont la qualité n'est plus à démontrer.

Les appareils hybrides disposent tous d'un processeur qui interprète et affine les données d’images avec des algorithmes complexes qui contrôlent les zones texturées, le traitement des bords et la reproduction tonale...bref, qui vous corrige l'image avant même que vous n'y pensiez.
Chaque constructeur y va d'ailleurs de son innovation pour tenter de se démarquer sur un marché encore très concurrentiel. Citons par exemple :
-
Olympus, qui propose sur sa série OMD, une fonction live composite. Cette fonction permet de superposer les unes sur les autres les différentes prises de vue. Là où il fallait un logiciel de traitement d'images puissant, votre hybride suffit désormais.
-
Olympus propose, comme la plupart de ses concurrents, une stabilisation mécanique de ses optiques sur 5 axes. Mais il peut aussi ajouter à cette stabilisation un traitement logiciel.
-
Panasonic propose quant à lui un mode photo 4K en rafale. On ne parle pas ici de vidéo 4K : l'appareil prend une série de photos qui composent une courte vidéo 4K, dont on peut extraire une image, celle que l’on préfère. C’est assez pratique pour les sujets en mouvement...
-
Dans la même série, Panasonic propose également des fonctions de “Timelapse” et “hyperlapse”. L'appareil crée des séquence prises sur la durée qui donnent un effet de vidéo accélérée. Pas besoin de post-traitement, le processeur se charge de créer l’animation en fin de séquence, dans un format en 4K Ultra HD.
-
Fujifilm propose quant à lui de reproduire les effets de ses films agentiques dans des préréglages, un peu à la mode des filtres d'Instagram. On n'est pas loin de l'app !
Ces fonctions, vous aurez du mal à les trouver dans un appareil photo réflex grand public. Même si avec le logiciel Magic Lantern, la communauté OpenSource fait des miracles sur les réflex Canon. Comme quoi il s'agit bien d'un problème de logiciel et non de matériel. Et ce virage logiciel, imposés par les smartphones et les hybrides, il semblerait que les grands constructeurs de réflex l'aient raté.
En conclusion
Un appareil photo hybride comparé à un réflex met aujourd'hui la référence KO. L'hybride propose les mêmes avantages qu'un réflex : un grand capteur plein format ou APS-C, une grande gamme d'optiques qui s'enrichit tous les mois, un viseur électronique qui offre beaucoup d'avantages sur le viseur optique, même s'il pêche encore par son manque de réactivité, et surtout de nombreuses fonctions de traitement de l'image. Enfin, les prises vidéos, HD ou 4K, sont bien plus pratiques avec un hybrides qu'un réflex.
L'hybride combine tout cela avec un encombrement et un poids réduits. Autant dire que ce n'est que du bonheur. Ses seuls défauts restent le manque d'autonomie, lié à l'usage systématique de l'écran comme viseur optique, et à l'absence - mais pour combien de temps - d'un vrai viseur optique, pour les amateurs de photos sportives et autres photographes de mode (mais on ne parle pas là de grand public).
S'il faut choisir aujourd'hui, et à moins que la réactivité d'un viseur optique ne vous soit indispensable, il faut donc retenir l'appareil photo hybride. Les leaders du marché sont Panasonic (avec son excellente gamme Lumix), Olympus (avec sa non moins excellente gamme OM-D) et Fujifilm (avec sa toute aussi bonne gamme X-T). Il ne vous reste plus qu'à choisir parmi ces 3 (ou d'autres, à vous de les proposer) l'appareil du moment qui vous conviendra le mieux.
La Gestion des Données de Test, le DevOps et le RGPD

Je vous ai parlé, il y a quelques temps déjà, de la façon dont on construit un pipeline DevOps. Et comment on pouvait ainsi automatiser sa chaîne de développement logiciel. Avec une étape cruciale qui est le "continuous testing" et des outils populaires comme Junit, SoapUI, Selenium ou encore HP UFT. Mais ce dont je ne vous ai pas parlé, c'est des données de tests. Car pour tester une fonction, il faut souvent des données. Et quand on automatise ses tests, c'est encore plus important. Car une seule donnée de test vous manque et tout votre pipeline est planté, comme disait la Martine.
Cela parait tellement évident qu'on oublie souvent de le dire. Et on passe donc trop rapidement sur un pan essentiel du DevOps qui est la gestion des données de test, ou le Test Data Management (TDM) comme diraient les anglo-saxons. Et pour citer le Gartner (2017),
« L’impact financier moyen de données de qualité médiocre sur les organisations est de 8,2 M$ par an »
Il est vrai qu'l s'agit surtout pour le Gartner de problème de qualité de données de production avant tout, mais ce coût inclut également ceux de test, n'en doutons pas. Voilà donc un article qui vous permettra de poser les bases d'une bonne gestion de vos données de tests, des bonnes pratiques aux outils.
Pourquoi gérer des données de test
Les données de tests servent avant tout aux tests fonctionnels. La gestion des données de test facilite la vie des testeurs, améliore leur productivité mais aussi la qualité de leurs tests. S'ils peuvent disposer de données de test pertinentes, représentatives et cohérentes, de manière simple et automatisée, les testeurs passeront moins de temps à générer, extraire ou charger leurs données et plus de temps sur leurs cas de test. Surtout qu'avec les environnements distribués que nous connaissons aujourd'hui, il devient souvent nécessaire d'émuler un service ou de bouchonner une partie des flux, et donc de disposer des données correspondantes rapidement.
Mais les données de test facilitent aussi la vie des développeurs. Surtout ceux qui sont en charge de la maintenance de l'application. Car pour reproduire une anomalie détectée en production et la corriger, il faut souvent pouvoir disposer des données à l'origine de l'anomalie. Il faut donc être capable de les mettre à disposition des développeurs rapidement. Mais encore faut-il s'assurer que vous respectez le récent Règlement Général sur la Protection des Données (RGPD) qui veut que vous protégiez les données personnelles de vos clients. Or des données qui sortent de la production sont fatalement plus exposées, les environnements de développement étant généralement moins sécurisés. La gestion des données de test peut répondre au problème en anonymisant ou masquant les données sensibles ou personnelles.
Enfin, les données peuvent aussi servir aux tests de performance. Pour vérifier la stabilité, la tenue à la charge ou déterminer le point de rupture d'une application, les tests de performances nécessitent des milliers voire des millions d'enregistrements. Ceci afin d'exécuter des tests sur plusieurs heures. Pas facile de disposer d'une telle volumétrie dans des environnements de non production. Le plus simple reste encore de charger l'image de la base de production sur votre banc de test. Tout en respectant encore une fois le RGPD.
Données de production ou données synthétiques
Maintenant que vous êtes convaincu qu'il est nécessaire de disposer de données pour vos tests, la première question à se poser est de savoir de quelles données vous avez besoin.
-
Vous partez de zéro et vous développez une nouvelle application ? Vous ne disposez donc évidemment pas de données réelles issues de la production. Il vous faut donc fabriquer des données de toutes pièces, des données synthétiques. Générer de la donnée synthétique, c'est assez facile. Il suffit généralement de la saisir au travers des écrans transactionnels de votre application. Cela a l'avantage de respecter l'intégrité fonctionnelle de la base de données, contrairement à un chargement direct en base de données. Sauf que la saisie est longue et fastidieuse. Oui mais...vous disposez d'un automate de test comme Selenium, HP UFT ou Tricentis Tosca. Il vous suffit alors de faire exécuter cette saisie par ces automates pour générer en masse des données artificielles avec lesquelles vous pourrez jouer ensuite vos scénarios de test. Il existe aussi des outils spécialisés, comme CA Test Data Manager, qui ont l'avantage d'offrir d'autres fonctions (que nous allons voir ci-après).
Pour faire simple, pour générer des données de test et exécuter vos scénarios, vous n'avez besoin que d'un automate type Selenium ou HP UFT. Un seul outil pour tout faire (ou presque). Le rêve ! -
Vous disposez d'un certain existant voire d'un existant certain. Comme des référentiels clients ou des applications tierces (une application de comptabilité générale par exemple) avec lesquelles votre application en cours de développement ou d'évolution doit communiquer. Et dans ce cas, rien ne vaut de bonnes données de production. Car créer des données synthétiques cohérentes sur l'ensemble des applications impliquées dans les tests peut s'avérer une vraie gageur. Alors que vos données de production sont naturellement cohérentes et tellement plus riches. Il suffit donc de capturer ces données de production pour constituer son jeu de test. Mais c'est là que les choses se corsent. Extraire manuellement les données de production de plusieurs systèmes différents hébergées sur des plates-formes hétérogènes peut vite devenir un vrai casse-tête. Il vous faut donc un outil pour gérer toute la complexité que cela peut représenter.
En conclusion, un outil de gestion des données de test s'avère vite indispensable dès que l'on dispose d'un existant et d'un patrimoine applicatif important. Cet outil aura l'avantage d'automatiser la capture des données de production, tout en gérant tout le cycle de vie de ces données.
Mais avant de passer en revue les meilleurs outils du moment, je vous propose de nous pencher avant sur la façon dont on met en œuvre une gestion des données de test. Dans la suite de ce billet, je me placerai dans le cas le plus fréquent, celui d'une application interconnectée à de nombreux autres systèmes applicatifs, impliquant une vraie gestion des données.
Commet mettre en œuvre une gestion des données de test
La mise en œuvre de la gestion des données de tests se décompose en 7 grandes étapes :
|
1 - Cartographier ses données 3 - Masquer les données sensibles 4 - Charger des sous-ensembles 5 - Contrôler automatiquement les résultats |
1 - Découvrir et cartographier les données de test
 Les données de production sont souvent réparties entre plusieurs applications, stockées dans différents formats et hébergées sur des plates-formes hétérogènes (Windows, Unix, Z/OS, OS/400, etc.). Ce ne serait pas drôle sinon. Mais pour capturer des données et à les mettre à disposition des testeurs, encore faut-il savoir où elles sont stockées et à quels systèmes elles sont liées.
Les données de production sont souvent réparties entre plusieurs applications, stockées dans différents formats et hébergées sur des plates-formes hétérogènes (Windows, Unix, Z/OS, OS/400, etc.). Ce ne serait pas drôle sinon. Mais pour capturer des données et à les mettre à disposition des testeurs, encore faut-il savoir où elles sont stockées et à quels systèmes elles sont liées.
Pour cela, il faut donc cartographier vos données, c'est à dire disposer d'un plan répertoriant vos données et leur localisation. Ce plan peut être établi manuellement mais cela est souvent fastidieux. L'outil de gestion des données de test vous aidera en découvrant automatiquement la façon dont vos données sont organisées. Comment ? Simplement grâce aux intégrités référentielles de vos bases de données. Évidemment, cela ne vous permettra pas de répertorier 100% de vos données, car certaines relations peuvent s'étendre sur plusieurs bases de données. Ces dernières peuvent d'ailleurs être hétérogènes (une base de type Oracle, une base MySQL et une base SQL Server) et stocker les données dans des formats différents. Mais cela servira de base de départ. Et cela n'est déjà pas si mal. Il vous faudra ainsi saisir à la main les relations fédérées entre bases de données.
2 - Extraire un sous-ensemble de données de production à partir de plusieurs sources de données Afin de constituer un jeu de données de test impliquant plusieurs applications, on pourrait simplement se contenter de "cloner" l'ensemble des bases de données de production. Mais les volumes que cela implique (et donc l'espace de stockage), les temps de traitement et les coûts que cela représente rendent vite cette solution inenvisageable.
Afin de constituer un jeu de données de test impliquant plusieurs applications, on pourrait simplement se contenter de "cloner" l'ensemble des bases de données de production. Mais les volumes que cela implique (et donc l'espace de stockage), les temps de traitement et les coûts que cela représente rendent vite cette solution inenvisageable.
L'extraction d'un sous-ensemble de données est donc sans doute la meilleure méthode pour vous constituer des jeux de données de test réalistes, représentatifs et cohérents. Il vous faudra sans doute procéder à quelques itérations pour trouver le bon sous-ensemble. Pas trop grand pour que vos tests soient faciles à exécuter, mais pas trop petits, sinon vos données ne seraient pas assez variées et vos tests pas ou peu représentatifs. Vous l'aurez compris, la difficulté de l'exercice consiste surtout à trouver les données de production qui remplissent les conditions de vos cas de test. Cela demande un peu de recherche, ce qui est souvent plus facile quand vous disposez d'un infocentre ou datamart. Vous pouvez aussi modifier légèrement vos données pour mieux les faire correspondre à vos cas de test.
Mais l'extraction n'est pas la seule méthode. Vous pouvez aussi cloner et virtualiser vos bases de données. Le clonage est une bonne vieille technique, bien maîtrisée par les administrateurs de base de données. Mais elle avait l'inconvénient de répliquer la totalité des volumes de production. Combinée à la virtualisation des bases de données, elle offre désormais des possibilités plus qu'intéressantes : un seul clone peut être virtualisé plusieurs fois de manière instantanée (comprenez par là que les données ne sont répliquées physiquement mais qu'elles existent pourtant) et donc servir plusieurs projets différents sans que les volumes s'en retrouvent multipliés.
Pour autant, le clonage et la virtualisation ne vous épargnera sans doute pas la préparation de sous-ensembles pour vos tests. Car il faut que ces derniers puissent être exécuter simplement et facilement. Il est bien plus facile de sélectionner un item (et toujours le même) parmi trois que parmi 10 000. Et de lancer un traitement sur 100 lignes que 1 millions.
3 - Masquer, pseudonymiser ou anonymiser les données sensibles ou personnelles Le récent Règlement Général sur la Protection des Données (RGPD ou en bon anglais General Data Protection Regulation - GDPR) impose aux sociétés de protéger les données de leurs clients. Et d'informer le régulateur si ces données venaient à être compromises. Les pénalités en cas de non-respect peuvent s'élever à 4% du chiffre d'affaire mondial de la société épinglée, même si cette dernière n'est qu'une petite filiale du bout du monde. Autant dire que vous avez intérêt à renforcer la sécurité de vos systèmes et de vos applications si ces derniers sont exposés ou vulnérables. Mais si la sécurité des environnements de production a toujours été stricte, celle des environnements de développements et de tests l'est généralement moins. Notamment en ce qui concerne l'authentification des utilisateurs. Les équipes de développement se font et se défont trop rapidement pour que les habilitations suivent dans les systèmes. Les développeurs ont donc pris l'habitude de se partager les login de test ou de désactiver simplement le système d'authentification.
Le récent Règlement Général sur la Protection des Données (RGPD ou en bon anglais General Data Protection Regulation - GDPR) impose aux sociétés de protéger les données de leurs clients. Et d'informer le régulateur si ces données venaient à être compromises. Les pénalités en cas de non-respect peuvent s'élever à 4% du chiffre d'affaire mondial de la société épinglée, même si cette dernière n'est qu'une petite filiale du bout du monde. Autant dire que vous avez intérêt à renforcer la sécurité de vos systèmes et de vos applications si ces derniers sont exposés ou vulnérables. Mais si la sécurité des environnements de production a toujours été stricte, celle des environnements de développements et de tests l'est généralement moins. Notamment en ce qui concerne l'authentification des utilisateurs. Les équipes de développement se font et se défont trop rapidement pour que les habilitations suivent dans les systèmes. Les développeurs ont donc pris l'habitude de se partager les login de test ou de désactiver simplement le système d'authentification.
Les données de test sont donc facilement accessibles et s'échangent souvent entre équipes, parfois délocalisées en Inde ou ailleurs. Autant dire que même avec un bon contrat et des clauses de confidentialité béton, vous n'êtes sûr de rien. Pour éviter tout risque de compromission, on a donc tendance à masquer ou anonymiser les données, ce qui rend leur valeur nulle pour un cyber-attaquant. Sans rentrer dans les détails, voici 3 techniques possibles :
-
Le masquage des données. Il suffit de remplacer une donnée par une autre non significative. Vous pouvez ainsi changer le numéro de téléphone de vos clients par une série de 0. C'est le plus simple à réaliser mais c'est aussi le plus intrusif. Car si votre test utilise cette donnée, il risque d'échouer lamentablement. Il existe bien sût plusieurs techniques de masquage, allant de la substitution de valeur fixe à la génération de valeurs en passant par la substitution de sources de données.
-
L'anonymisation des données. Cette technique a pour but de rendre toute identification impossible. En remplaçant le nom de votre client "Jean Chambard" par "John Doe", il devient théoriquement impossible de l'identifier. Mais ce n'est pas aussi simple que cela. Car avec le nom vient aussi souvent l'adresse, le numéro de téléphone, le n° d'INSEE, le n° de carte bleue, etc. Il est donc facile de remonter à la véritable identité de la personne si vous n'y prenez pas garde. Et par le jeu des recoupements, on peut obtenir des résultats surprenants. C'est pourquoi on a introduit la notion de pseudonymisation, dont parle tant le RGPD.
-
La pseudonymisation des données ressemble comme 2 gouttes d'eau à l'anonymisation. Sauf que si l'anonymisation n'autorise aucune faille dans l'identification, la pseudonymisation si. Identifier une personne via des données ne doit pas être possible, mais le fait de recouper plusieurs données distinctes reste autorisé. Charge à l'entreprise de bien protéger les données complémentaires qui permettraient cette identification.
Tout cela n'est pas forcément simple. Heureusement, la plupart des outils propose des mécanismes d'anonymisation ou de masquage. Comme des algorithmes permettant de générer des numéros de cartes bancaires conformes, des noms et prénoms, des numéros IBAN, etc.
A noter que puisque la plupart des outils savent manipuler les données dans tous les sens, ils savent aussi faire vieillir les données de test. Ce qui peut être intéressant lorsque votre campagne de test doit exécuter un test qui normalement se déroule sur plusieurs semaines dans la vraie vie.
4 - Charger le sous-ensemble de données dans les environnementsI cibles
Une fois votre jeu de données constitué puis anonymisé, il vous faut le charger dans l'environnement cible. Généralement, il s'agit de l'environnement de recette, mais cela peut aussi être un simple environnement d'intégration ou de maintenance. Tout dépend de ce que vous voulez faire (reproduire une anomalie de production, valider une nouvelle fonction, tester les non-régressions, etc.).
Le chargement des données de test est un traitement qui demande du temps (d'où la nécessité de constituer un sous-ensemble), sauf si vous utilisez une méthode de virtualisation des bases de données. Dans ce dernier cas, la création et mise à disposition des données de test peut être quasi immédiat.
Une fois vos données chargées, vous pourrez exécuter votre batterie de tests. Si cette dernière n'est pas concluante, il vous faudra corriger puis relancer vos cas de test. Mais pour cela, il vous faudra remettre vos données dans leur état initial. Il vaut donc mieux disposer d'une sauvegarde de votre jeu de données ou d'une photographie (snapshot) dans le cas de bases de données virtuelles. Cela parait évident mais il vaut mieux y penser avant qu'après. Ceci introduit une notion de contrôle de version des jeux de donnés, fonction que proposent certains outils.
5 - Contrôler automatiquement les résultats avant et après
Lorsque vous jouez des tests de non-régression (à tout hasard), vous connaissez déjà les résultats attendus. Et peut-être avez-vous déjà fait une sauvegarde de ces résultats ? Dans ce cas-là, tant mieux, car certains outils vous proposent de comparer les résultats des différentes campagnes de tests avec des données de référence. Et de mettre en exergue les différences, histoire d'identifier plus rapidement les régressions.
6 - Rafraichir ses données de test
 Une fois la campagne de test terminée et vos développements validés, votre environnement de recette se trouve dans un état incertain. Du moins en ce qui concerne les données, qui ont subi tout un tas de modifications et d'essais dans tous les sens. Et c'est pourquoi il est nécessaire de restaurer une certaine cohérence dans tout cela. Il faut donc procéder à intervalle régulier à une réinitialisation des environnements (on efface tout et on recommence, certains appellent cela un rafraichissement total) ou tout au moins à un rafraîchissement (partiel) des données. Cela consiste à mettre à jour un sous-ensemble des données de test (elles-mêmes déjà un sous-ensemble des données de production) avec les dernières valeurs des données de production.
Une fois la campagne de test terminée et vos développements validés, votre environnement de recette se trouve dans un état incertain. Du moins en ce qui concerne les données, qui ont subi tout un tas de modifications et d'essais dans tous les sens. Et c'est pourquoi il est nécessaire de restaurer une certaine cohérence dans tout cela. Il faut donc procéder à intervalle régulier à une réinitialisation des environnements (on efface tout et on recommence, certains appellent cela un rafraichissement total) ou tout au moins à un rafraîchissement (partiel) des données. Cela consiste à mettre à jour un sous-ensemble des données de test (elles-mêmes déjà un sous-ensemble des données de production) avec les dernières valeurs des données de production.
Certains testeurs protesteront car ce rafraichissement partiel ou total peut casser leurs tests. On peut alors procéder à un rafraichissement incrémental, consistant à ajouter à nos données de tests existantes de nouvelles données qui n'écraseront pas les anciennes. Pratique mais dangereux car votre environnement de test sera de plus en plus pollué par une redondance importante des données, dont une bonne partie dans un état incertain.
7 - Offrir les données en self-service et en automatique
 Enfin, pour gagner en agilité (nous sommes partis de notre pipeline DevOps rappelez-vous), il faut pouvoir automatiser l'alimentation des données de tests lors de l'exécution des TNR, eux-même pilotés par notre plate-forme d'intégration continue et notre automate de tests fonctionnels ; ou pouvoir déclencher l'extraction des données à la demande, au travers d'une interface en self-service, de manière à rendre les testeurs le plus autonomes possible.
Enfin, pour gagner en agilité (nous sommes partis de notre pipeline DevOps rappelez-vous), il faut pouvoir automatiser l'alimentation des données de tests lors de l'exécution des TNR, eux-même pilotés par notre plate-forme d'intégration continue et notre automate de tests fonctionnels ; ou pouvoir déclencher l'extraction des données à la demande, au travers d'une interface en self-service, de manière à rendre les testeurs le plus autonomes possible.
Certains outils disposent nativement de ces interfaces (un plugin avec Jenkin, un portail utilisateur en self-service). Mais pour certains, il faut développer une surcouche et se brancher sur les API de l'outil.
Voila nos grandes étapes de la gestion des données de test. Passons maintenant à la revue des meilleurs produits du moment (qui ne vaut que pour cette année 2018 donc).
Les meilleurs outils de gestion des données de test
Je liste ici les outils par ordre alphabétique et non par ordre de préférence, chacun aura sans doute son classement préféré, fonction de ses besoins et contraintes.
-
CA Test Data Manager : un des leaders du marché.
-
Compuware’s File-AID Data Management, combiné avec Test Data Privacy pour l'anonymisation des données
-
Delphix Test Data Management, une solution complète de virtualisation des bases de données
-
Doble Test Data Management
-
Ekobit BizDataX (une société croate)
-
Grid-Tools (pour référence, acquis par CA Technologies en 2015)
-
IBM InfoSphere Optim Test Data Management : un incontournable.
-
Informatica Test Data Management tool : un des leaders du marché avec IBM et CA.
-
Oracle Enterprise Manager : Oracle fournit des fonctions de Test Data Management avec son outil d'administration de ses bases de données (Modélisation, Création de sous-ensembles et anonymisation des données). Compte-tenu des parts de marché d'Oracle, c'est un incontournable...mais est-ce vraiment encore le cas ?
-
Original software Test Data Management
-
Solix EDMS Test Data Management
-
SAP Test Data Migration Server (un outil dédié aux solutions SAP, mais qui fait son job)
Les leaders du marché sont clairement Informatica, IBM et CA Technologies, suivi de Delphix qui possède une technologie innovante de virtualisation de bases de données et Compuware qui est un des rares avec IBM à couvrir à la fois les plates-formes Z/OS et Open (Windows, Unix, Linux). Mais le choix reste votre. N'hésitez pas à laisser vos commentaires sur ces produits ou sur la démarche de gestion des données de test en elle-même.
D'ici là, faites de bons tests...

Le clavier visuel de Windows

Le clavier 101 touches
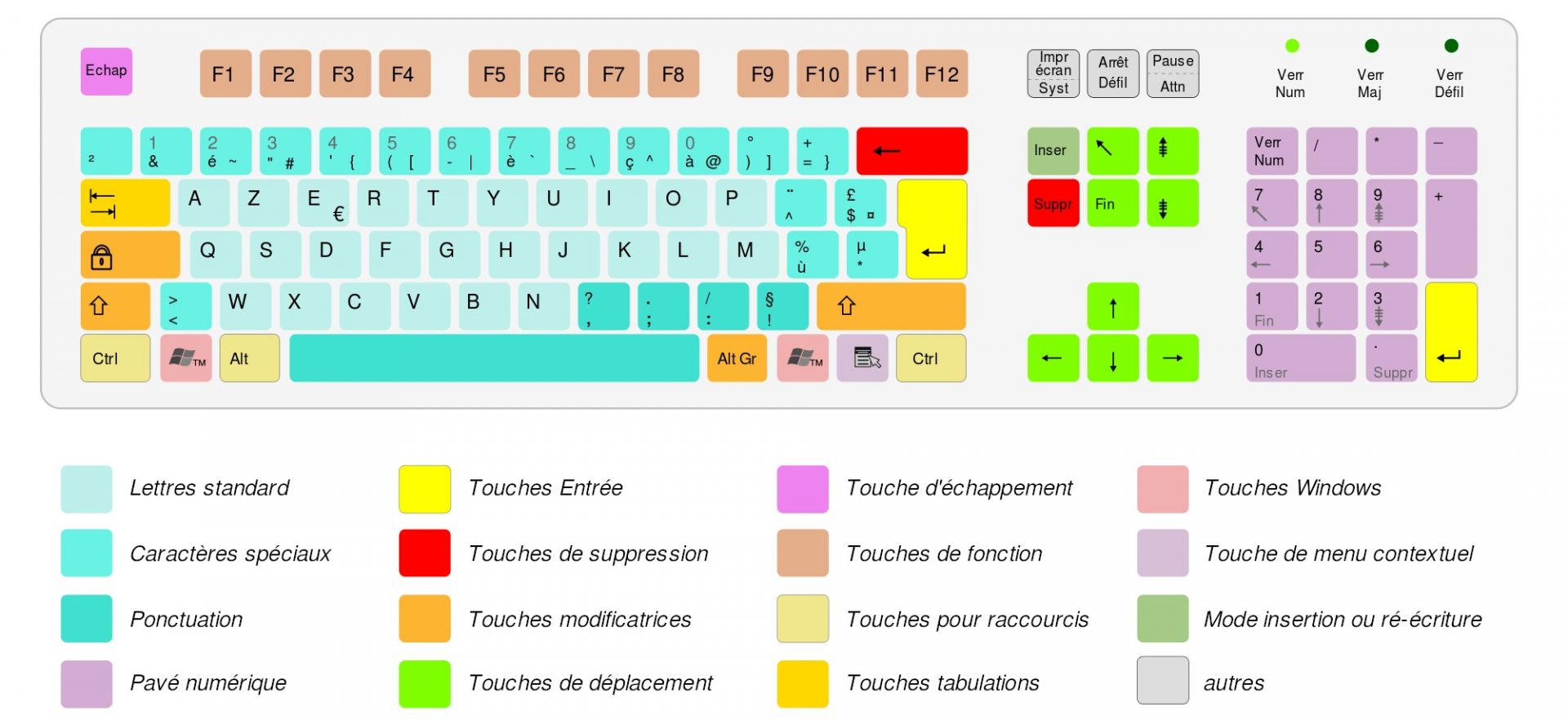
Le saviez-vous ? Les claviers standards des ordinateurs modernes ont entre 101 et 106 touches. 101 pour les américains, 102 pour les européens, 103 touches pour les coréens et 106 touches pour les japonais.
Microsoft a rajouté 3 autres touches avec Windows 95 : deux touches "Démarrer" (équivalent au clic sur le bouton démarrer de Windows) et une touche "menu" qui permet de déclencher le menu contextuel de l'application dans laquelle vous êtes (équivalent au clic droit). On dispose donc désormais de 104 à 109 touches. Un clavier comme celui représenté ci-dessous.
Le clavier compact à 83 touches
Les claviers à 105 touches c'est bien mais c'est encombrant. Et comme la plupart des ordinateurs sont aujourd'hui des portables (ou plutôt des ultrabook) de 13 ou 14 pouces, il est impossible de caser ces 105 touches dans la largeur du châssis. Et c'est pour cela qu'on dispose de claviers compacts à 83 touches (voire plus ou moins). Comme celui du célèbre Thinkpad d'IBM (depuis revendu à Lenovo).

Le problème avec ces claviers compacts, c'est qu'il manque certaines touches. Comme "Pause" ou "Arrêt défil" par exemple. Or cette touche si peu utilisée a pour effet de bloquer le défilement sous Excel par exemple. Et quand vous avez bloqué votre logiciel dans ce mode, il est difficile d'en sortir sans un vrai clavier. Ce qui amène souvent à des crises fatales à votre PC qui finit en petits morceaux...
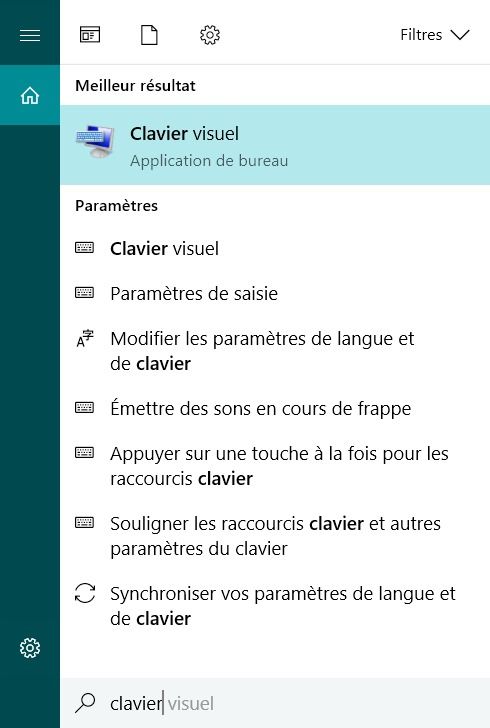 Mais il existe une solution ! le clavier visuel de Windows. Il suffit de cliquer sur le bouton "démarrer" de Windows, de chercher "clavier" dans le champs de recherche et de cliquer sur "Clavier visuel".
Mais il existe une solution ! le clavier visuel de Windows. Il suffit de cliquer sur le bouton "démarrer" de Windows, de chercher "clavier" dans le champs de recherche et de cliquer sur "Clavier visuel".
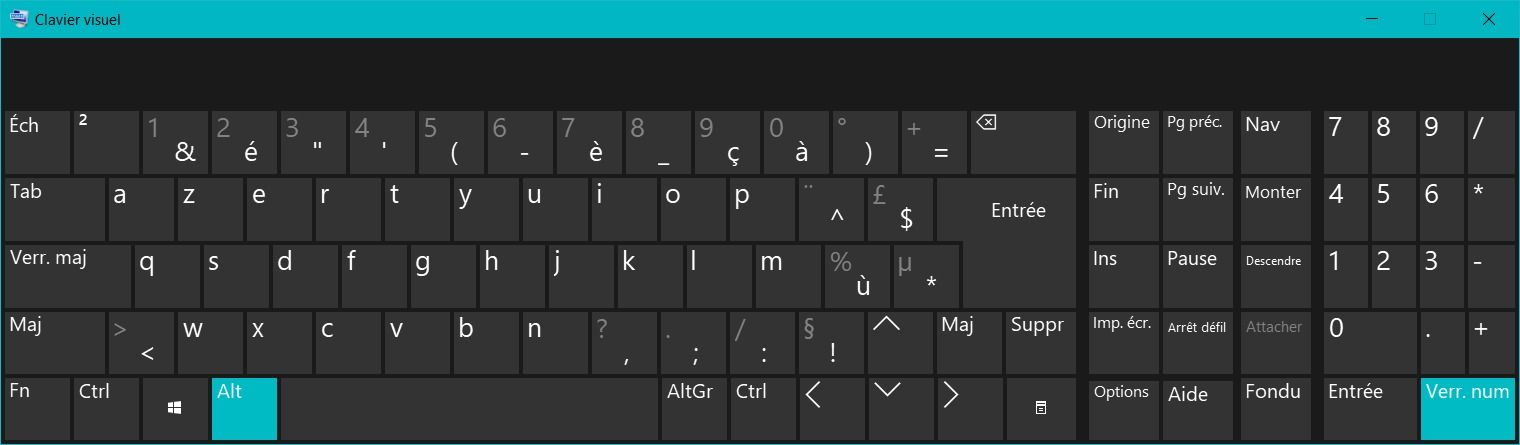
Et vous voilà avec un clavier complet sur lequel il est facile de retrouver sa touche manquante. Pratique non ?
Attention, le clavier visuel prend le pas sur le clavier physique, cela peut donc être assez perturbant quand on ne s'est pas entraîné à utiliser ce clavier. Personnellement, je ne m'en sert qu'en cas de dépannage sur mon ultrabook, quand je veux utiliser une touche qui n'existe pas sur son clavier compact.
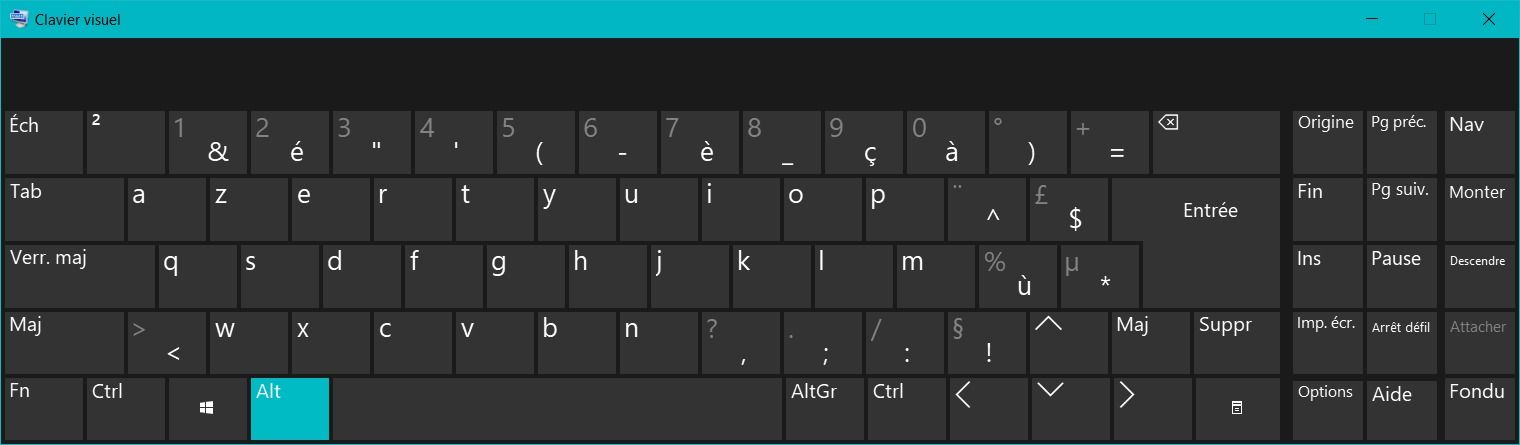
Vous remarquerez qu'il ne s'agit pas tout à fait d'un vrai clavier. Les touches principales sont disposées traditionnellement mais les touches comme "Imprime Ecran" ou "Arrêt Défil" sont reportées sur la droite.
Il y a aussi une touche assez trompeuse, dénommée "Options". En cliquant sur cette touche, vous accédez aux options du clavier visuels. Vous pouvez ainsi activer le pavé numérique.
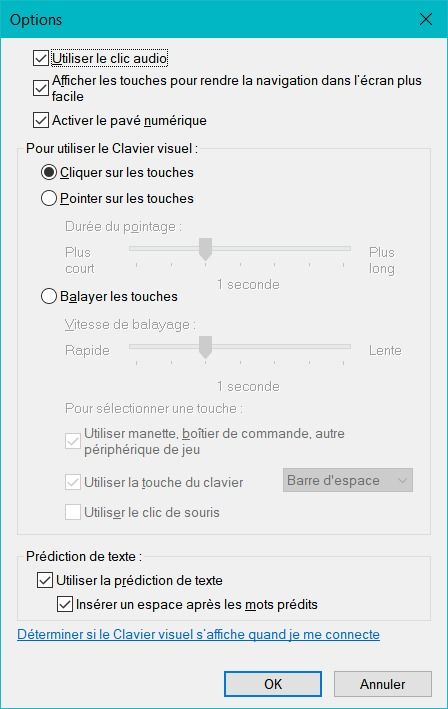
Contruire un pipeline DevOps
Tous les spécialistes vous le diront, le DevOps, c'est une histoire de culture d'entreprise d'abord. Car il s'agit avant tout de faire collaborer des ingénieurs du développement logiciel avec des ingénieurs de la production informatique. Deux mondes qui ne partagent pas forcément les mêmes objectifs. Les premiers font des projets qui induisent fatalement des changements, tandis que les seconds sont les garants du bon fonctionnement du SI, et appréhendent par là-même tout changement qui pourrait mettre cette fiabilité en péril.
C'est ce qu'on appelle communément le mur de la confusion, mur qui se dresse entre Dév et Ops et qui les empêchent de collaborer. Difficile de travailler de concert quand on a des objectifs opposés et irréconciliables. Et ce ne sont pas les outils qui font collaborer les gens. Non, c'est la culture de la collaboration. En cela, les puristes ont raison.
La qualité au centre de tout
 Irréconciliables, les Devs et les Ops ne le sont qu'en apparence. Car les Dév ne jettent pas toujours leur code en production en priant pour qu'il marche et sans se soucier des conséquences. Et les Ops ne sont pas systématiquement opposés aux changements, pourvu que ces derniers n'entrainent pas d'incidents ou d'instabilité. Devs et Ops se retrouvent et se réconcilient sur le terrain de la qualité.
Irréconciliables, les Devs et les Ops ne le sont qu'en apparence. Car les Dév ne jettent pas toujours leur code en production en priant pour qu'il marche et sans se soucier des conséquences. Et les Ops ne sont pas systématiquement opposés aux changements, pourvu que ces derniers n'entrainent pas d'incidents ou d'instabilité. Devs et Ops se retrouvent et se réconcilient sur le terrain de la qualité.
Facile à dire mais pas facile à faire. La qualité a souvent été sacrifiée sur l'autel du respect du coût et des délais, quand elle n'était pas assassinée avant par l'incompétence ou les mauvaises pratiques de développement. Avant de se faire définitivement enterrée par une infrastructure inadéquate et deux ou trois erreurs de déploiement en production.
La solution existe pourtant et est connue depuis longtemps. Il faut auditer et surtout tester le code intensivement. Mais cela coûte cher et prend du temps, me direz-vous. A moins que vous n'automatisiez tout cela. Du développement au déploiement en production. Grâce à des outils. Alors si la culture de la coopération entre Devs et Ops constitue les fondations du DevOps, l'automatisation et la mesure en sont assurément les réacteurs.
La démarche DevOps, qui vise à réconcilier ces deux grands métiers de l'Informatique, en étendant les principes des méthodes agiles aux équipes de production, ne peut donc vivre sans un "pipeline" automatisé (et vice-versa). Nous allons donc nous intéresser ici à la façon de construire un pipeline DevOps.
Le pipeline (ou chaîne d'outils)
La première erreur du débutant est de confondre méthode agile et absence de méthode. C'est d'autant plus vrai avec nous français. Il ne faut pas confondre le "Quick and dirty" et l'agilité. Les deux approches ont en commun la rapidité, mais la première vous donnera un résultat approximatif, tandis que la seconde vous garantira la qualité en sus. Et pour éviter les travers, rien ne vaut un bon rail, qui vous guide du développement jusqu'à la production. Et ce rail, c'est le pipeline.
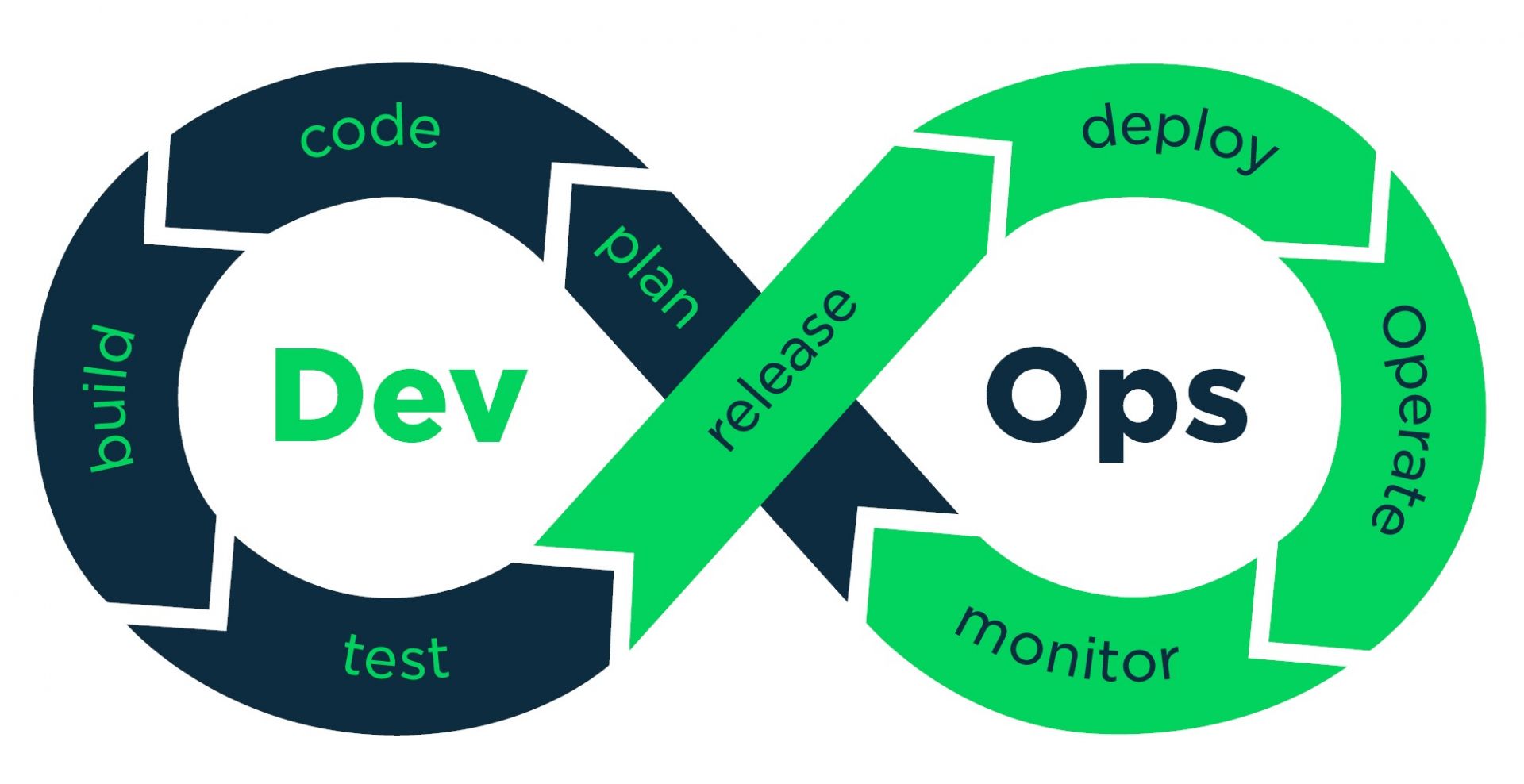
Sur le papier, rien ne ressemble plus à un pipeline DevOps qu'un pipeline de développement logiciel classique. Il faut planifier, coder, compiler et packager son logiciel, le tester, le livrer en recette avant de le déployer en production. Une fois en production, il faut le maintenir en condition opérationnelle et donc le superviser en permanence. La seule différence, c'est que ce cycle se déroule sur une période courte et fixe, et qu'on peut réitérer ainsi à l'infini (et au-delà). D'où le ruban de Moebius en symbole de ce cycle.
Afin d'automatiser ce cycle, il est nécessaire de mettre en oeuvre et d'intégrer de nombreux outils. Cela est souvent synonyme de coûts de licences et de maintenance éditeur et de coûts de mise en oeuvre et de maintien en conditions opérationnelles. La bonne nouvelle, c'est qu'il existe sur le marché de nombreux outils OpenSource, avec des versions de base gratuites et des versions payantes pour ceux qui ont besoin de fonctions avancées. La mauvaise nouvelle, c'est que l'OpenSource bascule rapidement d'un fork à l'autre ou d'un outil à un autre. Il faut donc être capable de suivre.
Vu de manière linéaire, le pipeline, avec ses outils, c'est plutôt çà :
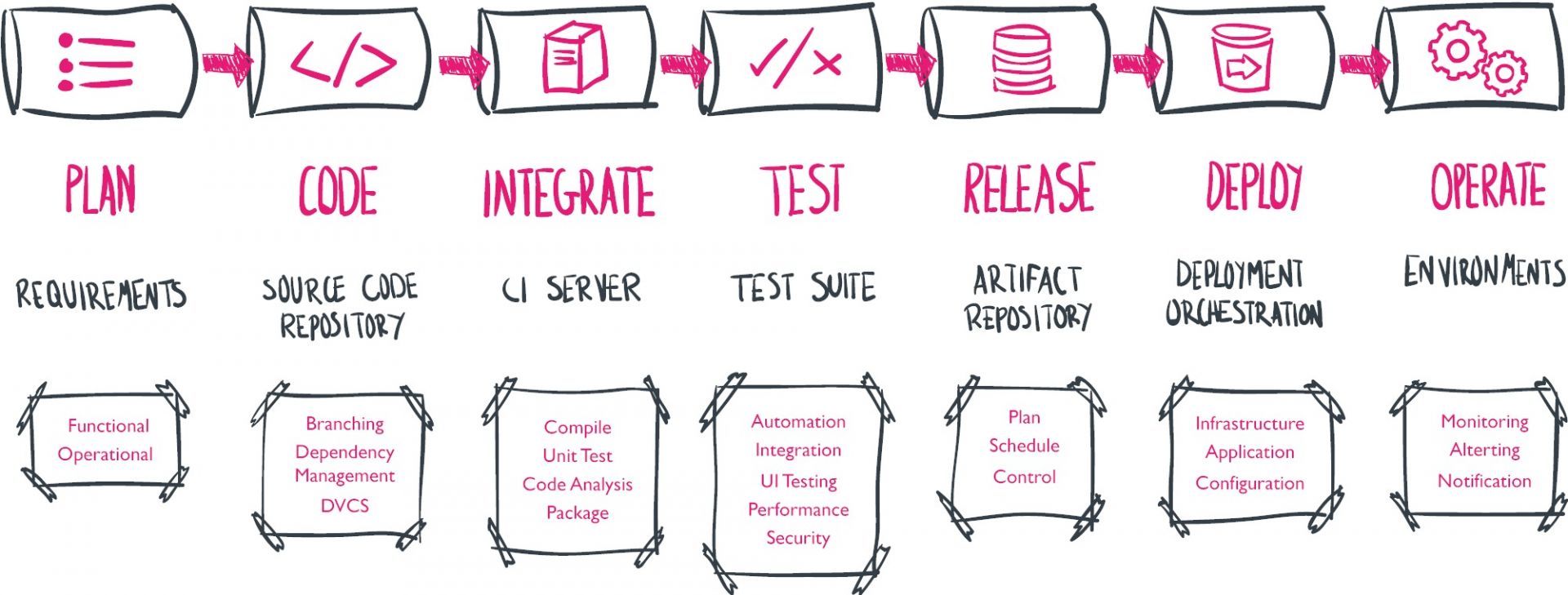
Je vais donc vous présenter ici les principaux outils qui constituent le pipeline DevOps. Évidemment, cet état de l'art ne vaut que les quelques mois qui viennent, mais c'est toujours intéressant d'avoir une photo du moment (Février 2018). J'aborde les outils du monde Open, car ils constituent la majorité des implémentations. Mais je n'oublie pas que le monde DevOps est aussi valable pour les développeurs Cobol et le mainframe. Cela intéresse certainement moins de personnes et je traiterai donc de ce sujet dans un article séparé.
Pour accéder directement aux différents thèmes ou phases du pipeline, cliquez simplement sur les liens ci-dessous.
| Plan → Code → Build → Test → Release → Deploy → Operate →Monitor |
Plan
 Pour commencer, il vous faut un bon outil de planification, adapté aux ou conçu pour les méthodes agiles. Histoire de pouvoir planifier ses sprints et ses « releases », suivre l'avancée de son backlog, et faciliter la collaboration entre équipes avec des tableau Kanban électroniques. Il existe deux grandes catégories sur le marché. Les outils orientés planification, relativement complexes et pas toujours faciles à maîtriser, et les outils orientés tâches, plus simples de prise en main. Ces derniers peuvent suffire si vous vous lancez dans l'Agile. Vous aurez ensuite la possibilité d'évoluer vers des outils plus complexes. Citons parmi les principaux outils :
Pour commencer, il vous faut un bon outil de planification, adapté aux ou conçu pour les méthodes agiles. Histoire de pouvoir planifier ses sprints et ses « releases », suivre l'avancée de son backlog, et faciliter la collaboration entre équipes avec des tableau Kanban électroniques. Il existe deux grandes catégories sur le marché. Les outils orientés planification, relativement complexes et pas toujours faciles à maîtriser, et les outils orientés tâches, plus simples de prise en main. Ces derniers peuvent suffire si vous vous lancez dans l'Agile. Vous aurez ensuite la possibilité d'évoluer vers des outils plus complexes. Citons parmi les principaux outils :
-
Micro Focus (anciennement HPE) Agile Manager
-
Microsoft Team Fondation Server (TFS)
-
CA Agile Central (anciennement Rally)
-
Atlassian Jira Software (connu pour son outil de bug tracking)
-
Trello (de la société éponyme, spin off de Fog Creek Software) : orienté tâches ;
NB : Trello a été racheté en 2017 par Atlassian mais garde pour le moment son identité. -
CollabNet ScrumWorks
-
Thoughtworks Mingle
-
Wrike (de la société éponyme)
-
Asana ((de la société éponyme) : orienté tâches
NB : un outil de gestion de projet offre notamment un découpage (WBS) et une gestion des tâches, un suivi des temps, du budget, un planning, une gestion des ressources, des outils collaboratifs (messagerie instantanée, wiki, espaces de partages etc.), des fonctions de rapports, de suivi des anomalies, etc.
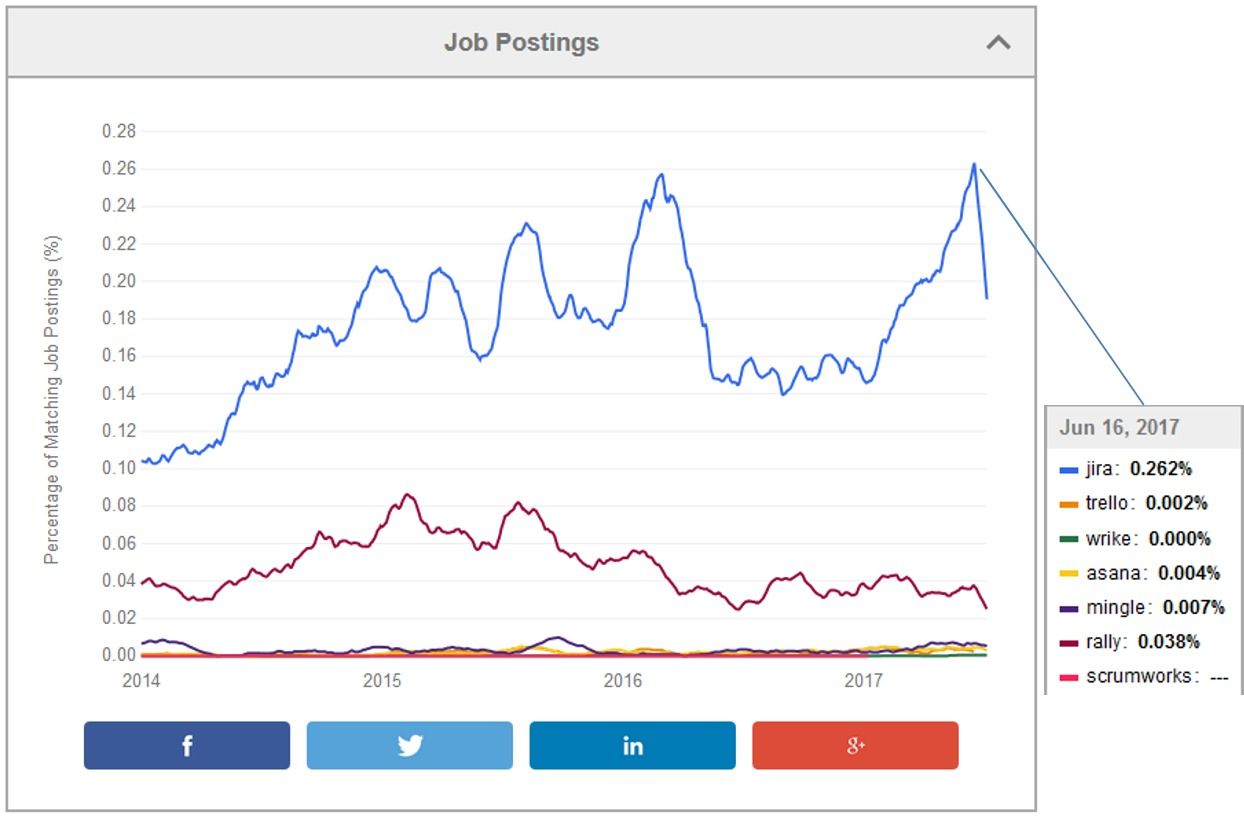
Si on regarde la fréquence des offres d'emplois sur la plate-forme Indeed, on voit que Jira arrive très loin devant ses concurrents. Il faut dire qu'Atlassian bénéficie d'une base installée importante et que son produit phare s'impose donc comme le produit leader. Mais Wrike ou Trello valent aussi l'essai...
Code
 Toute société de développement qui se respecte dispose d'un outil de gestion du code source. Cet outil permet non seulement de conserver le code source, mais de gérer aussi les différentes versions et branches du code. Sur le marché, il existe 2 générations d'outils. La première est centralisée : le code est stocké à un endroit et éventuellement répliqué, mais seule la base centrale fait foi. Ce qui peut être contraignant pour des équipes réparties géographiquement (qui n'a pas des équipes de développement en Inde ?). La seconde génération est décentralisée. Les répliques se synchronisent automatiquement. Parmi les premières générations d'outils, centralisés, on trouve :
Toute société de développement qui se respecte dispose d'un outil de gestion du code source. Cet outil permet non seulement de conserver le code source, mais de gérer aussi les différentes versions et branches du code. Sur le marché, il existe 2 générations d'outils. La première est centralisée : le code est stocké à un endroit et éventuellement répliqué, mais seule la base centrale fait foi. Ce qui peut être contraignant pour des équipes réparties géographiquement (qui n'a pas des équipes de développement en Inde ?). La seconde génération est décentralisée. Les répliques se synchronisent automatiquement. Parmi les premières générations d'outils, centralisés, on trouve :
-
Apache Subversion (SVN)
-
IBM Rational Clearcase
-
Microsoft Team Fondation Version Control (intégré à TFS)
Parmi les secondes générations d'outils, décentralisés, citons :
-
Git (l'outil) ou GitHub (le service) ; Outre le fait d'être décentralisé, Git gère plus facilement les différentes branches de codes et les fusions, surtout avec le produit Bitbucket d'Atalssian (qui peut utiliser Git ou Mercurial).
-
Mercurial Source Version Control (SVC)
-
Canonical Bazaar
-
Fossil Source Version Control
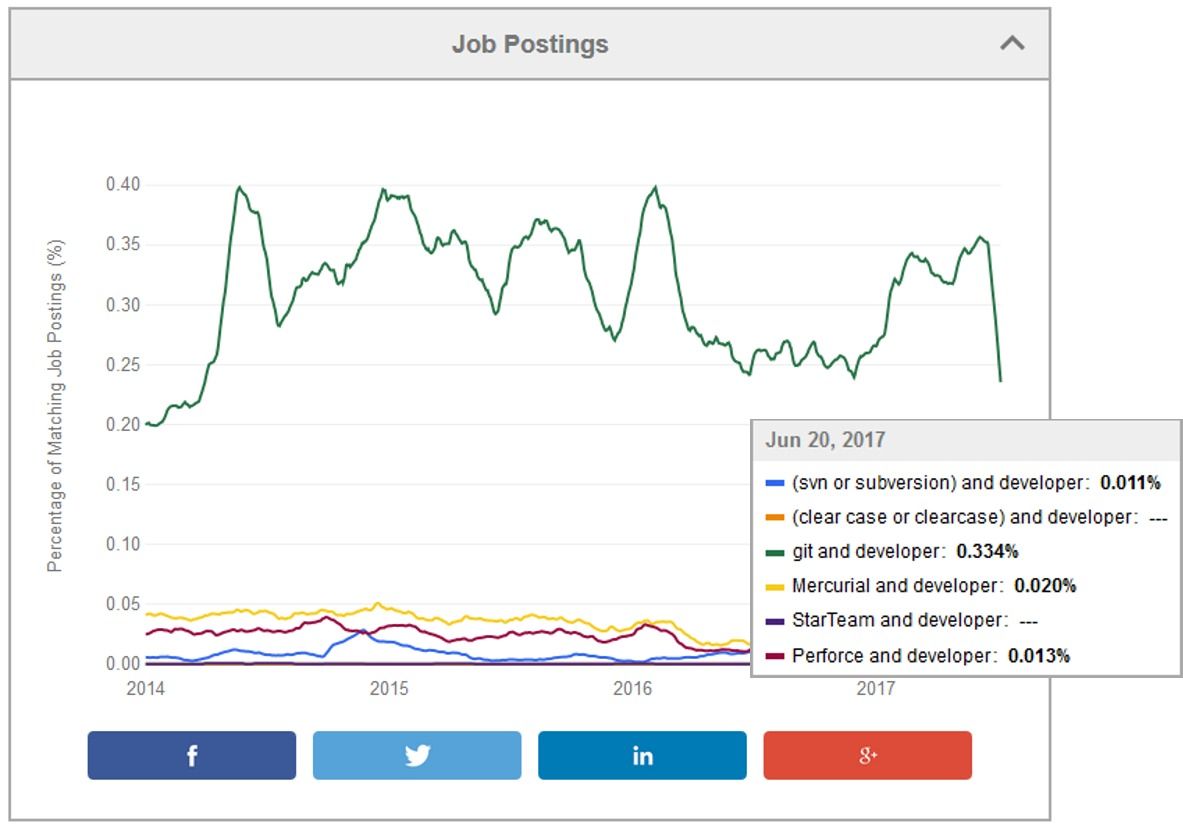
Git est de loin l'outil le plus utilisé, comme on peut le voir sur Indeed.
Build & Package - Integrate
 On appelle aussi la phase de "Build" phase "d'intégration" car c'est à ce moment que le code de chaque développeur est assemblé pour donner le produit final. Techniquement, on compile, on réalise l'édition de lien et on package le tout pour que l'exécutable puisse être déployé dans les différents environnements, y compris de production.
On appelle aussi la phase de "Build" phase "d'intégration" car c'est à ce moment que le code de chaque développeur est assemblé pour donner le produit final. Techniquement, on compile, on réalise l'édition de lien et on package le tout pour que l'exécutable puisse être déployé dans les différents environnements, y compris de production.
Pour intégrer, il faut un serveur d'intégration. Et en méthode agile, on appelle cela un serveur d'intégration continue (Continuous Integration Server ou CIS en anglais). Il y a quelques années encore, la bataille faisait rage entre Hudson et son clone Jenkins. Aujourd'hui, la question ne se pose plus : la plupart des utilisateurs ont basculé sur Jenkins. Il existe bien sûr quelques alternatives, mais c'est plus cher et moins bien :
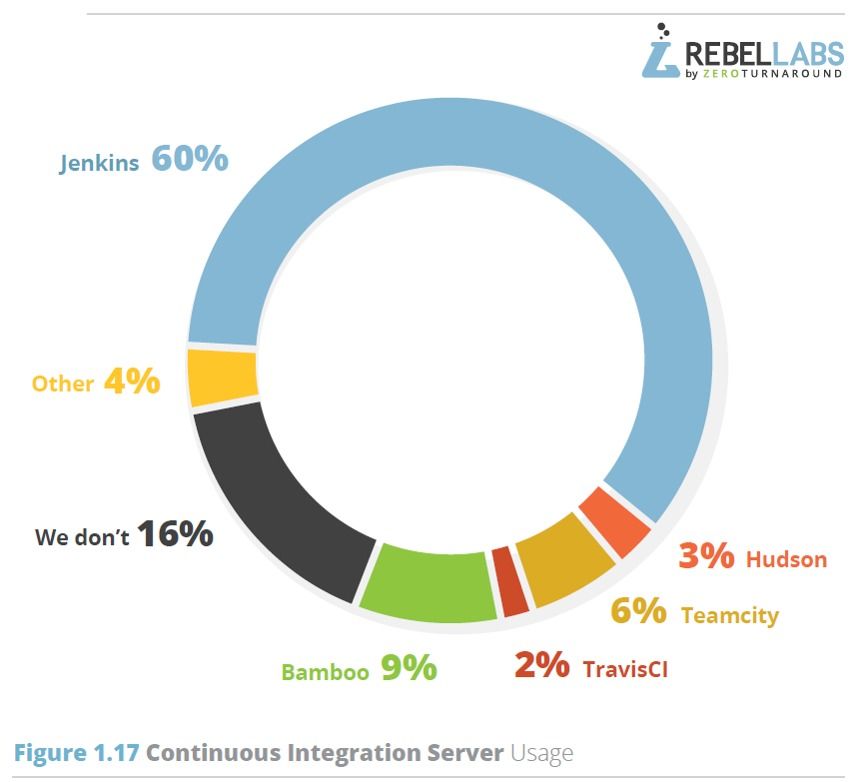
TFS a l'avantage d'être bien intégré à l'environnement de développement phare de Microsoft, Visual Studio, mais les compétences sur cette plate-forme sont assez "rares" sur le marché. Si l'on regarde les résultats de l'enquête de RebelsLabs, Jenkins domine le marché avec 60 % des parts, loin devant Bamboo ou Teamcity
Bien sûr, un logiciel comme Jenkins ne pourra pas répondre à tous les besoins d'une intégration continue. Rappelons que pour faire un bon pipeline, il vous faut être en mesure de compiler et de livrer tous les jours quelque chose de qualité. Cela suppose des retours rapides aux développeurs sur les modifications qu'ils ont apportés. Il vous faut donc intégrer quelques logiciels complémentaires, en sus des outils traditionnels de compilation, pour mesurer automatiquement la qualimétrie du code, détecter les failles (évidentes) de sécurité, ou encore tester de manière unitaire les différents modules.
Il faut donc veiller à ce que votre serveur d'intégration continue possède bien les bons plugins (ou interfaces) avec ses outils.
Dans la catégorie compilation
En sus de ces outils, si vous utilisez un système de container comme Docker en production, il vous faudra aussi bien sûr intégrer Docker dans votre processus de build. Coup de pot, graddle intègre justement un plugin pour Docker.
Dans la catégorie Analyse de code
-
SonarQube, capable d'analyser plus de 20 langages différents, du Java au Cobol en passant par le C et C++. Il y a aussi CAST bien sûr, mais ce dernier est incapable de sortir une analyse journalière du code. Autant dire que la philosophie de CAST ne colle pas du tout avec celle du DevOps et de l'Agile.
-
Checkmarx, outil permettant de scanner le code à la recherche de failles de sécurité. Cirons aussi dans les scanners sécurité Micro Fous Fortify et CA Veracode (module Developer Sandbox).
Dans la catégorie Tests unitaires, citons
-
JUnit, le plus populaire des xUnit, pour tester le code Java.
-
Jmockit et PowerMock, pour tester son code sans dépendre de connexion vers les composants tiers comme les bases de données par exemple.
-
SoapUI, qui permet de tester les API comme les Web Services. Il permet aussi bien d'autres choses au passage.
Enfin, dans la catégorie "référentiels de composants", qui vous permettent de stocker et gérer le résultat de votre compilation/édition de lien, citons :
-
Sonatype Nexus, qui peut résoudre des dépendances externes en "cachant" pour vous les composants externes à votre projet. Il fait aussi office de proxy Internet permettant de récupérer les composants disponibles sur Internet.
-
Apache Archiva
-
JFrog Artifactory
Chaque outil dispose généralement d'une barrière de qualité (quality gate). Si votre score Qualité/Sécurité est trop faible, votre code est recalé et ne sera pas déployé. En revanche, si votre score est suffisamment élevé, alors votre code sera compilé et poussé vers la prochaine étape. Généralement celle des "Tests fonctionnels".
Test
 L'étape la plus importante dans la vie d'un logiciel est la phase de tests. Et des tests, il y en a. A croire qu'on ne teste jamais assez...ce qui n'est pas faux. La qualité du code est directement corrélée avec le nombre de tests.
L'étape la plus importante dans la vie d'un logiciel est la phase de tests. Et des tests, il y en a. A croire qu'on ne teste jamais assez...ce qui n'est pas faux. La qualité du code est directement corrélée avec le nombre de tests.
-
Les tests d'intégration système (ou System Integration Tests) qui permettent de tester l'application intégrée dans son écosystème (référentiels, applications amont et aval, etc.)
-
Les Tests fonctionnels (ou Functionnal Integration Tests), qui permettent de valider les fonctions de l'application. Ils incluent les tests bilatéraux (d'application à application) et les tests de bout en bout (déroulant l'ensemble du processus).
-
Les tests de non-régression (TNR ou Regression Tests) : ce sont des tests fonctionnels ayant déjà été exécutés lors de la précédente recette et qui permettent de vérifier que les évolutions introduites dans la nouvelle version ne font pas dysfonctionner les précédentes fonctions livrées.
-
Les tests d'acceptation utilisateurs (UAT). Ils permettent de vérifier la conformité du produit final grâce à des scénarios réels (et avec des utilisateurs réels). C'est une sorte de phase de béta test, juste avant la publication du produit.
-
Les tests de performances (ou Capacity Tests) : ce sont les plus compliqués à réaliser. Il faut les réaliser quand l'application est assez stable pour passer sur le banc d'essai, mais sans qu'il soit trop tard pour changer quoi que ce soit.
-
Les tests de sécurité. De la même manière, on peut aussi tester la sécurité de l'application en même temps que ses performances.
 L'idée générale est d'automatiser un maximum de tests. Les tests unitaires sont généralement pris en charge lors de l'intégration. Les TNR sont de bons candidats, car ces tests ont déjà été exécutés au moins une fois. Les tests de performances et de sécurité aussi. Les smoke tests, ou sanity checks, ou encore tests de fumée, qui permettent généralement de valider la bonne livraison d'une version dans son environnement cible, sont aussi d'excellents candidats. En terme d'outils, on trouvera des choses très simples comme des choses très complexes.
L'idée générale est d'automatiser un maximum de tests. Les tests unitaires sont généralement pris en charge lors de l'intégration. Les TNR sont de bons candidats, car ces tests ont déjà été exécutés au moins une fois. Les tests de performances et de sécurité aussi. Les smoke tests, ou sanity checks, ou encore tests de fumée, qui permettent généralement de valider la bonne livraison d'une version dans son environnement cible, sont aussi d'excellents candidats. En terme d'outils, on trouvera des choses très simples comme des choses très complexes.
Dans la catégorie "Tests fonctionnels"
-
Selenium, pour tester toutes les applications avec une interface utilisateur basée sur un navigateur Web. Comme Selenium demande des compétences techniques importantes, il vaut mieux utiliser un outil compagnon, comme cucumber, pour s'aider dans la constitution des tests. Il a l'avantage d'être gratuit et bien intégré à Jenkins.
-
Micro Focus (Ex HPE) Unified Functionnel Testing (UFT). Le leader incontesté du marché. Il a aussi l'avantage d'être couplé à ALM (ex Quality Center), qui gère entre autre les cas de tests et les anomalies de recette. Il est capable de tester les applications Web, mais aussi les applications Client/Serveur et les applications sous Citrix. Il ne demande pas non plus de compétences en programmation Java. Ce qui constitue des plus non négligeables par rapport à Sélénium. Il existe un plugin Jenkins pour UFT mais sa mise en oeuvre vous demandera un peu plus d'huile de coude.
-
Tricentis Tosca, son challenger (voir figure ci-dessous).
-
Smartbear TestComplete
-
IBM Rational Test Workbench. Il faut mieux avoir la suite Rational et un bon Mainframe pour ce genre d'outils.
Dans la catégorie "Tests de performances"
-
Micro Focus (Ex HPE) LoadRunner. Le leader incontesté du marché.
-
Apache JMeter, une alternative OpenSoure
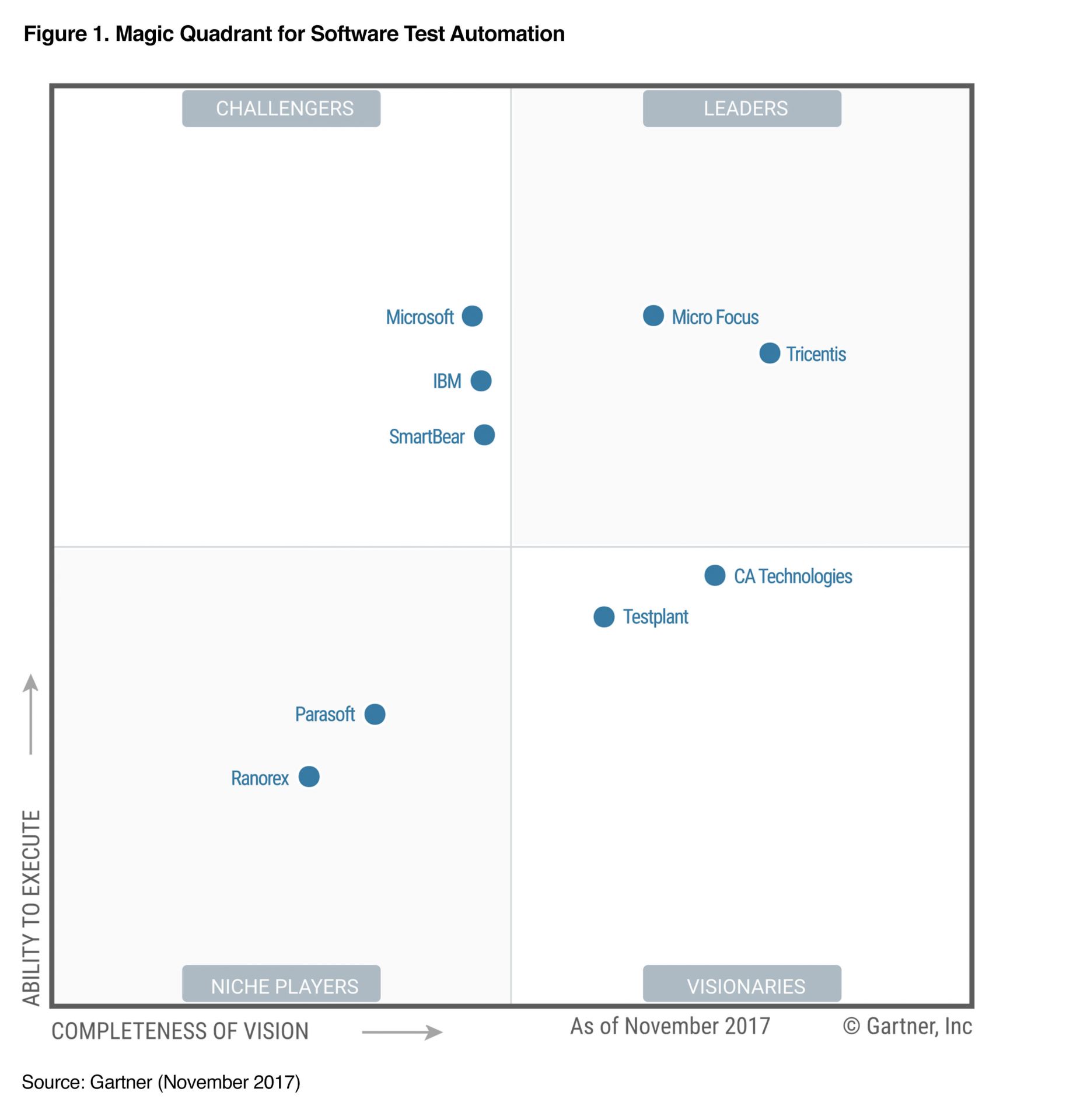
La figure suivante est issu du rapport de novembre 2017 du Gartner sur l'automatisation des tests logiciels. Comme le Gartner ne prend pas en compte les outils OpenSource (le CA est un critère important du Magic Quadrant), vous n'y trouverez évidemment pas Sélénium.
Dans la catégorie Sécurité, nous retrouvons les mêmes acteurs, tels que Checkmarx, CA Veracode et Micro Focus Fortify. Je ne reviendrai donc pas dessus. Vous pouvez les retrouver dans la section "Intégration continue".
Tous ces outils ont un point commun, ils nécessitent des données pour réaliser leurs tests. Ils peuvent donc générer leur propres données (données synthétiques) ou utiliser des données pré-existantes, chargées par un autre outil. C'est ce qu'on appelle le Test Data Management, dont les leader sont IBM InfoSphere Optim, Compuware FileAID et Informatica TDM. Mais ces outils sont hors champs de cet article. Notez simplement que vous aurez besoin d'y faire appel.
Release
 Quand votre logiciel a passé les tests d'intégration, il peut généralement être mis à disposition des testeurs. Tant qu'il était en phase de développement, on ne parlait que de build. Dès qu'il est jugé suffisamment stable pour être mis en recette, on parle de "release" (le développeur autorise la sortie de son produit en quelque sorte). Évidemment, avant qu'un produit ne soit mis en production, un certain nombre de versions applicatives va se succéder en recette pour aboutir à une release. On taggue alors le code, une fois le niveau de maturité atteint, avec un n° de version.
Quand votre logiciel a passé les tests d'intégration, il peut généralement être mis à disposition des testeurs. Tant qu'il était en phase de développement, on ne parlait que de build. Dès qu'il est jugé suffisamment stable pour être mis en recette, on parle de "release" (le développeur autorise la sortie de son produit en quelque sorte). Évidemment, avant qu'un produit ne soit mis en production, un certain nombre de versions applicatives va se succéder en recette pour aboutir à une release. On taggue alors le code, une fois le niveau de maturité atteint, avec un n° de version.
Pour gérer ces différentes releases, il faut un outil de gestion des référentiels de composants. Ces outils ont pour vocation de stocker mais aussi d'organiser et distribuer les logiciels et leurs bibliothèques, avec la bonne version. J'ai déjà évoqué ces produits dans la phase de build, les principaux sont Nexus, Archiva et Artifactory, mais il en existe bien d'autres naturellement.
Deploy
 Une fois votre produit testé et mis à disposition dans le référentiel de composants, il faut le déployer dans les différents environnements d'intégration, de recette, de pré-production et de production, sans parler de ceux de maintenance et de formation. Tout cela de manière automatisée si possible. Dans le plus simple des cas, il vous faut un outil qui sache déployer votre produit sur les différents environnements existants. Dans les cas les plus complexes, il faut aussi provisionner ces environnements, et ce de manière automatisée bien sûr.
Une fois votre produit testé et mis à disposition dans le référentiel de composants, il faut le déployer dans les différents environnements d'intégration, de recette, de pré-production et de production, sans parler de ceux de maintenance et de formation. Tout cela de manière automatisée si possible. Dans le plus simple des cas, il vous faut un outil qui sache déployer votre produit sur les différents environnements existants. Dans les cas les plus complexes, il faut aussi provisionner ces environnements, et ce de manière automatisée bien sûr.
Dans la catégorie Déploiement, on trouvera donc des outils comme :
-
Jenkins. En sus d'assurer l'intégration continue, Jenkins est aussi capable de faire du déploiement continu. Mais cela reste assez rudimentaire. Pour des outils un peu plus évolués, il faut s'orienter vers des outils payants, qui offrent de nombreux plugins et interfaces.
-
Electric Cloud ElectricFlow
-
XebiaLabs XL-Deploy. Un des leaders en France.
-
CA Technologies Automic Release Automation (rachat). Notons qu'Automic a réalisé un belle cartographie des différents outils, qui vaut le coup d'oeil.
-
Octopus Deploy
-
IBM UrbanCode Deploy (rachat)
Dans la catégorie Provisionning, on trouvera donc des outils (tous ont une version OpenSource) permettant de décrire son infrastructure par de simples lignes de "code" (Infrastructure as a code) comme :
-
Chef. Notons que Chef dispose aussi d'un outil de déploiement, ChefAutomate...Chef s'appuie sur Git et Ruby, il vaut donc mieux que vous ayez ces 2 produits en magasins. Chef est intéressant pour tous ceux qui cherche une solution mature fonctionnant dans un environnement hétérogène.
-
Puppet. Comme son concurrent, Puppet dispose aussi d'un outil de déploiement, Puppet Pipelines...Puppet est aussi un bon choix d'outil stable et mature, fonctionnant dans un environnement hétérogène et maitrisant bien le DevOps.
-
Ansible. Sans doute le plus simple des 3 produits, et fonctionnant sans agent, ce qui fait son succès, mais aussi le plus limité de ce fait.
-
Mentionnons aussi SaltStack et Fabric, des outils assez frustres de déploiement mais qui ont l'avantage d'être simples et gratuits.
Vous pouvez naturellement coupler Puppet ou Chef avec XL-Deploy par exemple, de manière à assurer la cohérence de votre déploiement avec celui du provisionning et de la gestion de la configuration de l'infrastructure.
La figure suivante est issu du rapport de septembre 2017 du Gartner sur l'automatisation des deploiements des applications. Comme le Gartner ne prend pas en compte les outils OpenSource (le CA est un critère important du Magic Quadrant), vous n'y trouverez évidemment pas Jenkins, ni Chef, mais Puppet et Ansible y figurent en bonne place.
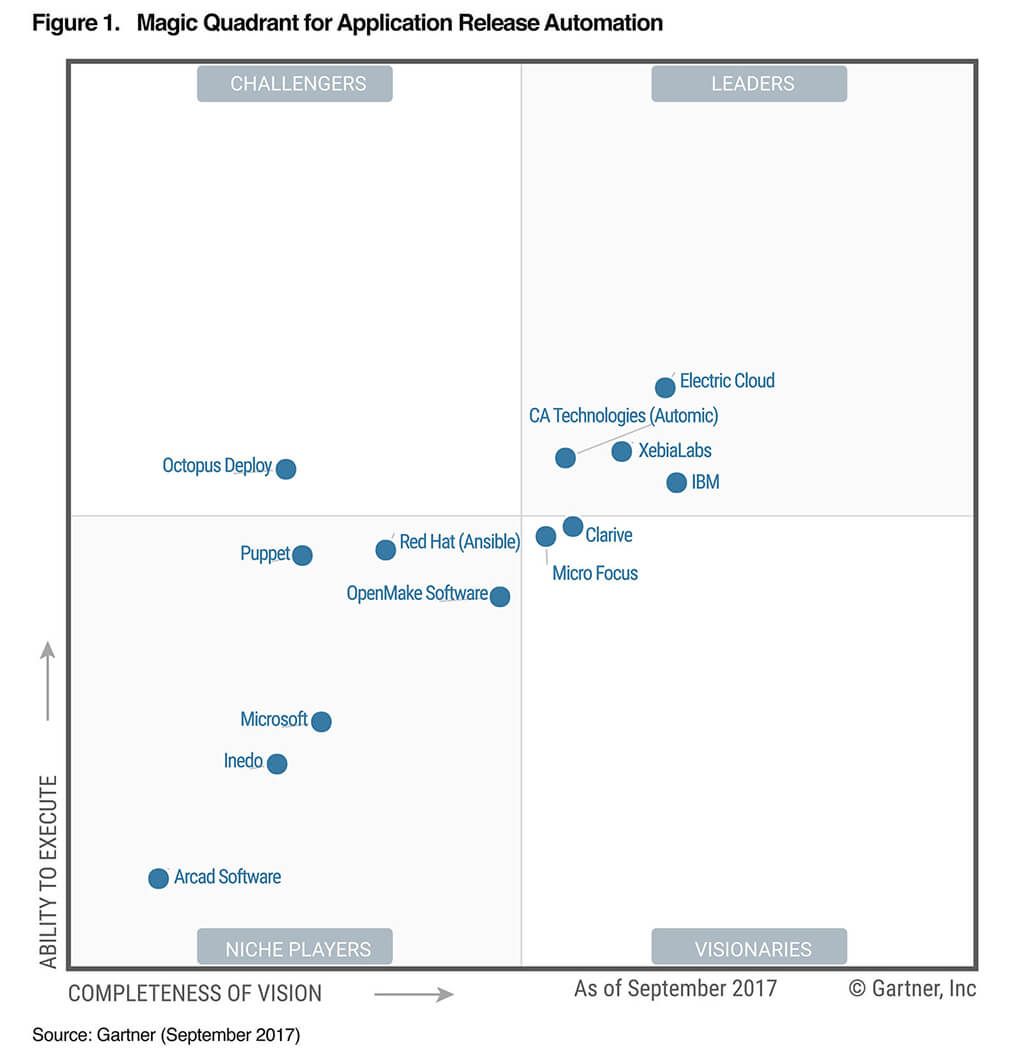
Maîtrise du processus de bout en bout
Nous venons de passer en revue les différentes produits de notre pipeline, et l'on serait tenter de s'arrêter ici. Nous avons en effet un outil pour planifier, gérer notre code, construire et packager notre produit, le tester, gérer les différentes releases et un outil pour les déployer. Mais n'oublions pas que la base de l'Agile, c'est Culture, Automation, Measurement and Sharing. Culture et Partage ne sont pas vraiment les sujets de cet article mais Automatisation et Mesure le sont totalement.
 Pas étonnant donc que l'on trouve avec l'émergence du DevOps des outils permettant de suivre son processus de release de bout en bout, du build au déploiement en production, et de pointer les dysfonctionnements, là où ça fait mal et ce qu'il faut améliorer pour disposer d'un pipeline le plus fluide possible. On n'améliore que ce que l'on mesure après tout...
Pas étonnant donc que l'on trouve avec l'émergence du DevOps des outils permettant de suivre son processus de release de bout en bout, du build au déploiement en production, et de pointer les dysfonctionnements, là où ça fait mal et ce qu'il faut améliorer pour disposer d'un pipeline le plus fluide possible. On n'améliore que ce que l'on mesure après tout...
-
L'outil le plus connu est certainement XebiaLabs XL-Release. Il permet de modéliser puis de superviser les livraisons logicielles, il orchestre les tâches au sein des équipes IT, du développement à la mise en production en passant par la recette. XL Release fournit des tableaux de bord de bout-en-bout, des outils d’analyse et de rapports approfondis et est facile d’utilisation. Il vous donne ainsi une chance de réduire les délais de livraison et d'améliorer les processus de livraison. L'outil dispose de nombreux plugins luis permettant de se brancher au pipeline DevOps, de l’intégration continue au provisionnement et au déploiement continu.
-
IBM UrbanCode Release
-
CA Technologies Automic Release Automation
J'aborde le sujet de l'orchestration des processus DevOps en dernier, mais ce n'est pas forcément le dernier outil à mettre en oeuvre. Si vous souhaitez en effet savoir par où commencer et où porter vos efforts, peut-être faut-il commencer par cette étape. Cela vous permettra de modéliser vos processus actuels avant de commencer à les améliorer.
Operate
 Nous abordons enfin pour terminer le sujet le plus vaste, celui des Ops. Il s'agit de maintenir en condition opérationnelle l'infrastructure et les applications qui tournent dessus. Un sujet vieux comme le monde. Je ne vais donc pas vous refaire le monde. Il est trop vaste. Mais s'il est un sujet qu'on ne peut éviter en parlant du DevOps, c'est bien celui des conteneurs (containers). Les conteneurs ont été inventés en 2004 par Sun (ce n'est donc pas une innovation récente comme certains ont tendance à l'affirmer un peu vite), mais ils connaissent depuis peu un énorme succès. Mais diantre pourquoi maintenant ?
Nous abordons enfin pour terminer le sujet le plus vaste, celui des Ops. Il s'agit de maintenir en condition opérationnelle l'infrastructure et les applications qui tournent dessus. Un sujet vieux comme le monde. Je ne vais donc pas vous refaire le monde. Il est trop vaste. Mais s'il est un sujet qu'on ne peut éviter en parlant du DevOps, c'est bien celui des conteneurs (containers). Les conteneurs ont été inventés en 2004 par Sun (ce n'est donc pas une innovation récente comme certains ont tendance à l'affirmer un peu vite), mais ils connaissent depuis peu un énorme succès. Mais diantre pourquoi maintenant ?
Un container, c'est une autre façon d'aborder la virtualisation. Ici, pas d'OS virtuel émulé, on fonctionne avec l'OS du système hôte. C'est plus simple et plus rapide. Mais du coup, tous les containers partagent le même OS et surtout les mêmes ressources. Impossible de dédier un processeur ou de la mémoire à un container donné, contrairement aux machines virtuelles.
De fait, un container est plus adapté qu'une machine virtuelle complète pour faire tourner les micro-services. Dédier une machine virtuelle complète pour y faire tourner un petit micro-services, cela fait un peu riche, vous en conviendrez. Pourquoi alors ne pas faire tourner plusieurs micro-services dans une même machine virtuelle ? Parce que l'on perdrait alors en agilité. Tout ce qui se trouver dans la machine virtuelle doit par définition partager la même pile logicielle (les mêmes versions de bases de données, de serveurs d'application, etc.). Or un micro-service évolue très vite et indépendamment des autres micro-services, selon la philosophie DevOps. D'où le retour en grâce des conteneurs.
Le conteneur facilite aussi grandement la vie des développeurs. Car le conteneur embarque toutes les dépendances applicatives. Le code, les éventuels runtime, les outils système, toutes les bibliothèques nécessaires et le paramétrage de l'application. Il suffit donc de construire son application dans son conteneur pour être capable de la déployer et de la faire tourner dans n'importe quel environnement, pourvu que celui-ci dispose d'un gestionnaire de conteneurs.
Parmi les fabricants de systèmes de conteneurs, nous trouvons :
-
Les conteneurs Linux LXC
-
Docker (qui n'est qu'une évolution des conteneurs LXC) et Docker Swarm pour la gestion des clusters, du routage, de la scalability.
-
Apache Mesos ; ce n'est pas un système de container mais plutôt un OS distribué supportant un système de container tel que Docker. Intéressant pour sa scalability.
-
Kubernetes : un système open source conçu à l'origine par Google et offert à la Cloud Native Computing Foundation. Il vise à fournir une « plate-forme permettant d'automatiser le déploiement, la montée en charge et la mise en œuvre de conteneurs d'applications sur des clusters de serveurs ». A noter que Docker offre maintenant le support de Kubertenes dans la Docker Community Edition pour les developpeurs sous Windows et macOS, et dans la Docker Enterprise Edition.
-
Les conteneurs Windows de chez Microsoft
-
et bien d'autres...
Bref, vous l'aurez compris, Docker, intégré dès le poste du développeur via Docker Compose, permet d'optimiser sa chaîne d'outil DevOps et facilite les déploiements en production. Encore faut-il que l'application soit conçue sur la base de micro-services bien sûr...
Monitor

La supervision est un sous-ensemble d'Operate. C'est sans doute un des principaux piliers des Ops avec la sauvegarde des données. Il n'y a donc rien de neuf dans le concept. Mais comme je l'ai dit précédemment, la mesure fait partie intégrante de la culture DevOps. Il est donc essentiel pour les devs comme pour les ops d'avoir des indicateurs sur le comportement de l'application. Et rien ne vaut une bonne supervision des performances de l'application.
Les principaux fournisseurs du marché sont :
A cela, on peut rajouter des outils permettant d'exploiter certaines données comme :
-
ELK : acronyme pour 3 projets open source, Elasticsearch, Logstash, et Kibana. Ce triptyque est très répandu et utilisé notamment pour la supervision de la sécurité, mais pas que.
-
Splunk : C'est une sorte de plate-forme d'Intelligence Opérationnelle (par opposition à la Business Intelligence) temps réel. On peut ainsi explorer, surveiller, analyser et visualiser les données machine via Splunk.
-
DataDog : DataDog est une excellente alternative à Splunk. La solution fonctionne aussi sur des environnements dans le Cloud.
La figure suivante est issu du rapport de décembre 2016 du Gartner sur les outils de supervision des performances applicatives.
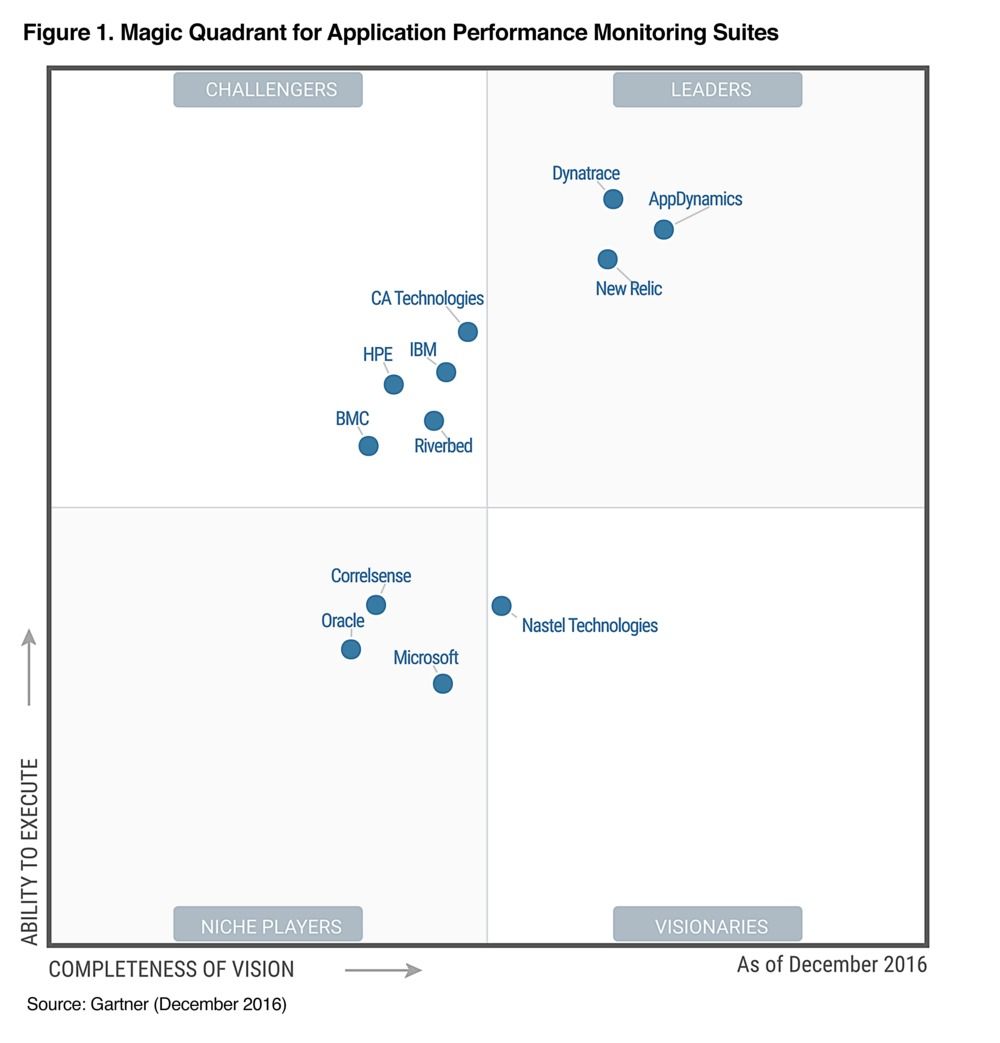
Conclusion
En résumé : pour construire votre pipeline, prenez un bon outil de planification agile comme Jira (si vous êtes familier avec les méthodes agiles), ou Wrike voire Trello pour démarrer, ajouter un bon gestionnaire de code source comme Git ou SVN (plus ancien), un bon serveur d'intégration continu comme Jenkins, assaisonnez d'outils complémentaires comme Maven ou Graddle, Junit SonaQube et Checkmarx pour les tests unitaires, la qualité et la sécurité. Mélangez ensuite avec Selenium ou UFT pour bien tester votre application et déployez le tout avec XL-Deploy. Il ne vous restera ensuite qu'à bien exploiter votre application et assurer sa disponibilité avec Docker Swarm et kubenetes et superviser ses performances avec Dynatrace et la sécurité avec Splunk ou ELK.
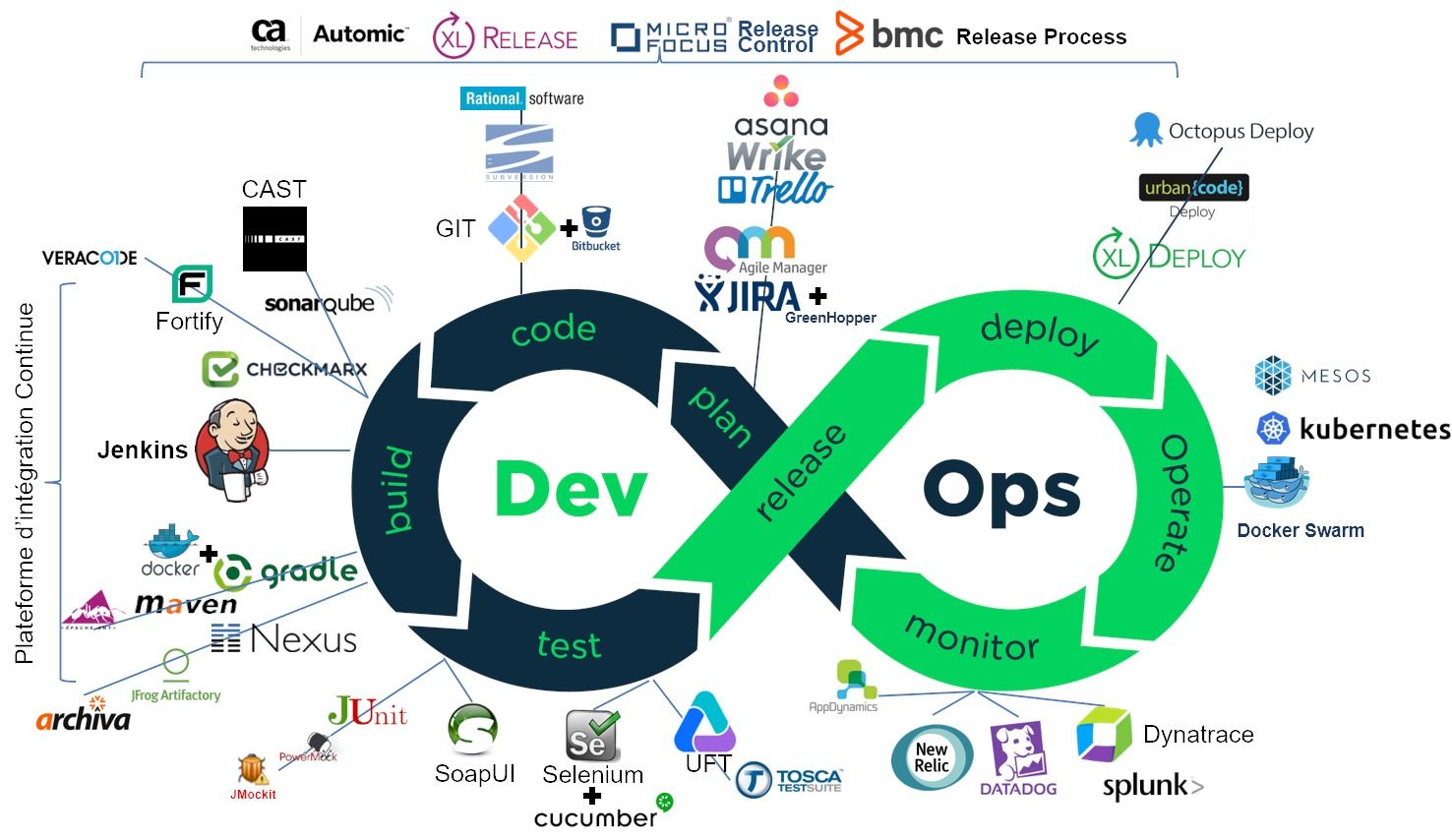
Bonne intégration et procédez par ordre, de l'intégration continue vers le déploiement continu : vous risqueriez sinon de finir comme sur la dernière image, ce serait dommage...
Charlie 3 ans après
 Graffitis sur les murs parisiens après l’attentat de Charlie Hebdo (JOEL SAGET / AFP)
Graffitis sur les murs parisiens après l’attentat de Charlie Hebdo (JOEL SAGET / AFP)
Le collectif "Toujours Charlie" organise un rassemblement et des débats ce samedi 6 janvier aux Folies Bergères, à Paris. Et selon un sondage Ifop, les Français se sentent de moins en moins "Charlie". Trois ans après l'attentat qui a frappé le journal satirique, seuls 61% Français sur dix se sentent toujours solidaires de l'hebdomadaire.
61%, c'est encore beaucoup. Il ne faut pas voir le verre à moitié vide mais plutôt à moitié plein. Mais en regardant de plus près, Ils étaient 71% à se sentir "Charlie" en janvier 2017 et ils ne sont plus que 61% aujourd'hui.
Les français commencent à oublier les attentats de 2015, ou en tout cas, ils sont moins marqués par ces derniers. Ce qui est normal et plutôt positif.
Ce qui est moins normal, c'est la liberté d'expression, pour laquelle Charlie Hebdo se bat aussi, qui régresse. La preuve ?
-
L'humoriste Tex est viré de France 2 après sa blague sur les femmes battues. Certes une mauvaise blague, mais Cyril Hanouna en a fait des pires.
-
La blackface d'Antoine Griezmann, jugée raciste, alors qu'il ne fait qu'imiter les Harlem Globe Trotters. Certes, nul n’ignore que le fait de se grimer en noir renvoie à une vision péjorative et humiliante des personnes noires ». OK. Mais je ne vois rien de péjoratif ici. Etre basketteur, ce n'est pas péjoratif. Et aujourd'hui, la NBA compte 77% de joueurs noirs...
-
Les réseaux sociaux, Facebook en tête, ont renforcé son contrôle et interdisent, de manière assez arbitraire, les propos et les images qui leur paraissent de nature à heurter ou « violer les droits » d’un groupe. Prétendre combattre les inégalités et l’oppression en bannissant certains discours ou images n'aboutit en fait qu'à son contraire, malheureusement.
Espérons que cette phase du ultra-politiquement correct ne durera pas trop longtemps.
