Contruire un pipeline DevOps
Tous les spécialistes vous le diront, le DevOps, c'est une histoire de culture d'entreprise d'abord. Car il s'agit avant tout de faire collaborer des ingénieurs du développement logiciel avec des ingénieurs de la production informatique. Deux mondes qui ne partagent pas forcément les mêmes objectifs. Les premiers font des projets qui induisent fatalement des changements, tandis que les seconds sont les garants du bon fonctionnement du SI, et appréhendent par là-même tout changement qui pourrait mettre cette fiabilité en péril.
C'est ce qu'on appelle communément le mur de la confusion, mur qui se dresse entre Dév et Ops et qui les empêchent de collaborer. Difficile de travailler de concert quand on a des objectifs opposés et irréconciliables. Et ce ne sont pas les outils qui font collaborer les gens. Non, c'est la culture de la collaboration. En cela, les puristes ont raison.
La qualité au centre de tout
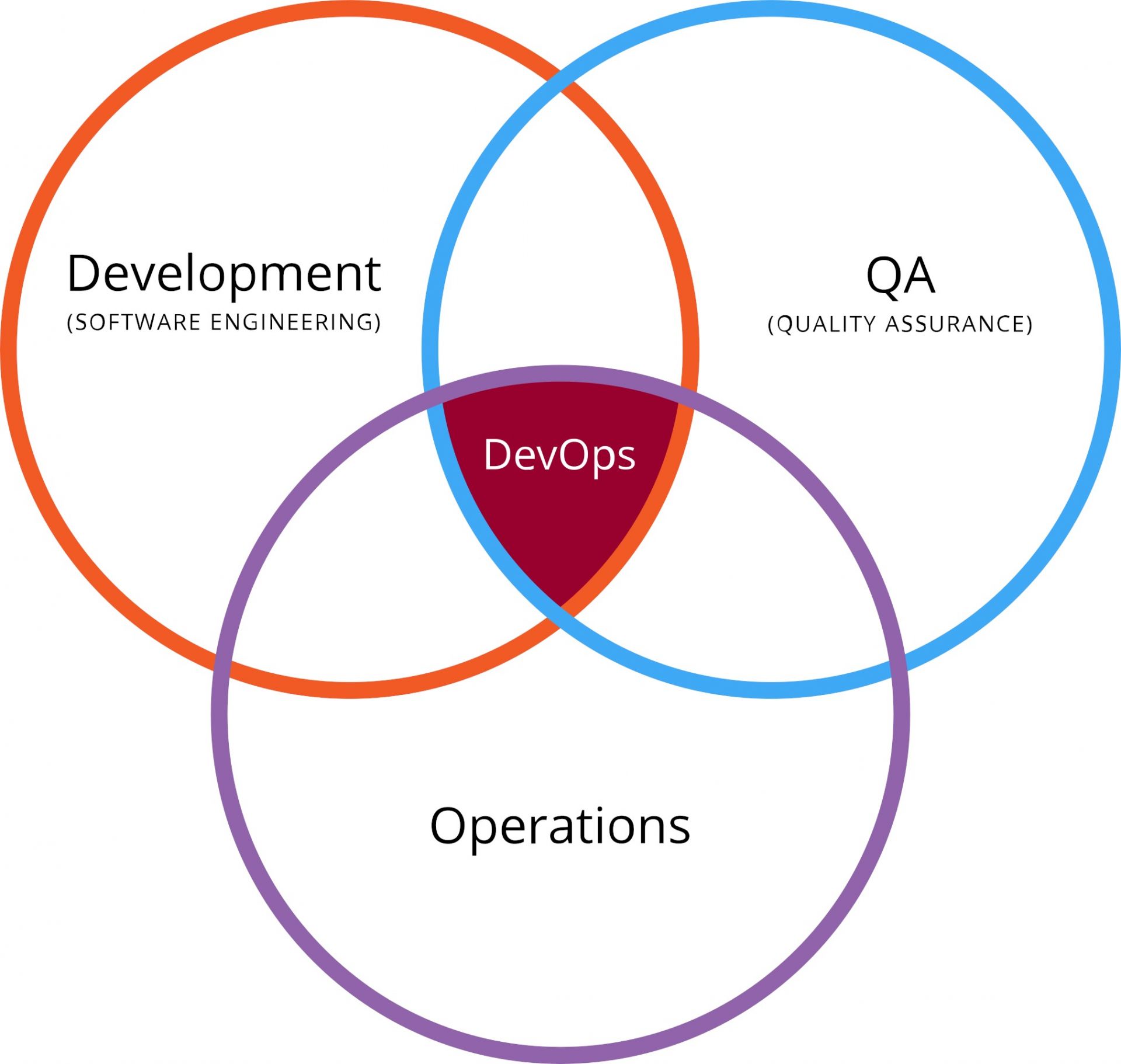 Irréconciliables, les Devs et les Ops ne le sont qu'en apparence. Car les Dév ne jettent pas toujours leur code en production en priant pour qu'il marche et sans se soucier des conséquences. Et les Ops ne sont pas systématiquement opposés aux changements, pourvu que ces derniers n'entrainent pas d'incidents ou d'instabilité. Devs et Ops se retrouvent et se réconcilient sur le terrain de la qualité.
Irréconciliables, les Devs et les Ops ne le sont qu'en apparence. Car les Dév ne jettent pas toujours leur code en production en priant pour qu'il marche et sans se soucier des conséquences. Et les Ops ne sont pas systématiquement opposés aux changements, pourvu que ces derniers n'entrainent pas d'incidents ou d'instabilité. Devs et Ops se retrouvent et se réconcilient sur le terrain de la qualité.
Facile à dire mais pas facile à faire. La qualité a souvent été sacrifiée sur l'autel du respect du coût et des délais, quand elle n'était pas assassinée avant par l'incompétence ou les mauvaises pratiques de développement. Avant de se faire définitivement enterrée par une infrastructure inadéquate et deux ou trois erreurs de déploiement en production.
La solution existe pourtant et est connue depuis longtemps. Il faut auditer et surtout tester le code intensivement. Mais cela coûte cher et prend du temps, me direz-vous. A moins que vous n'automatisiez tout cela. Du développement au déploiement en production. Grâce à des outils. Alors si la culture de la coopération entre Devs et Ops constitue les fondations du DevOps, l'automatisation et la mesure en sont assurément les réacteurs.
La démarche DevOps, qui vise à réconcilier ces deux grands métiers de l'Informatique, en étendant les principes des méthodes agiles aux équipes de production, ne peut donc vivre sans un "pipeline" automatisé (et vice-versa). Nous allons donc nous intéresser ici à la façon de construire un pipeline DevOps.
Le pipeline (ou chaîne d'outils)
La première erreur du débutant est de confondre méthode agile et absence de méthode. C'est d'autant plus vrai avec nous français. Il ne faut pas confondre le "Quick and dirty" et l'agilité. Les deux approches ont en commun la rapidité, mais la première vous donnera un résultat approximatif, tandis que la seconde vous garantira la qualité en sus. Et pour éviter les travers, rien ne vaut un bon rail, qui vous guide du développement jusqu'à la production. Et ce rail, c'est le pipeline.
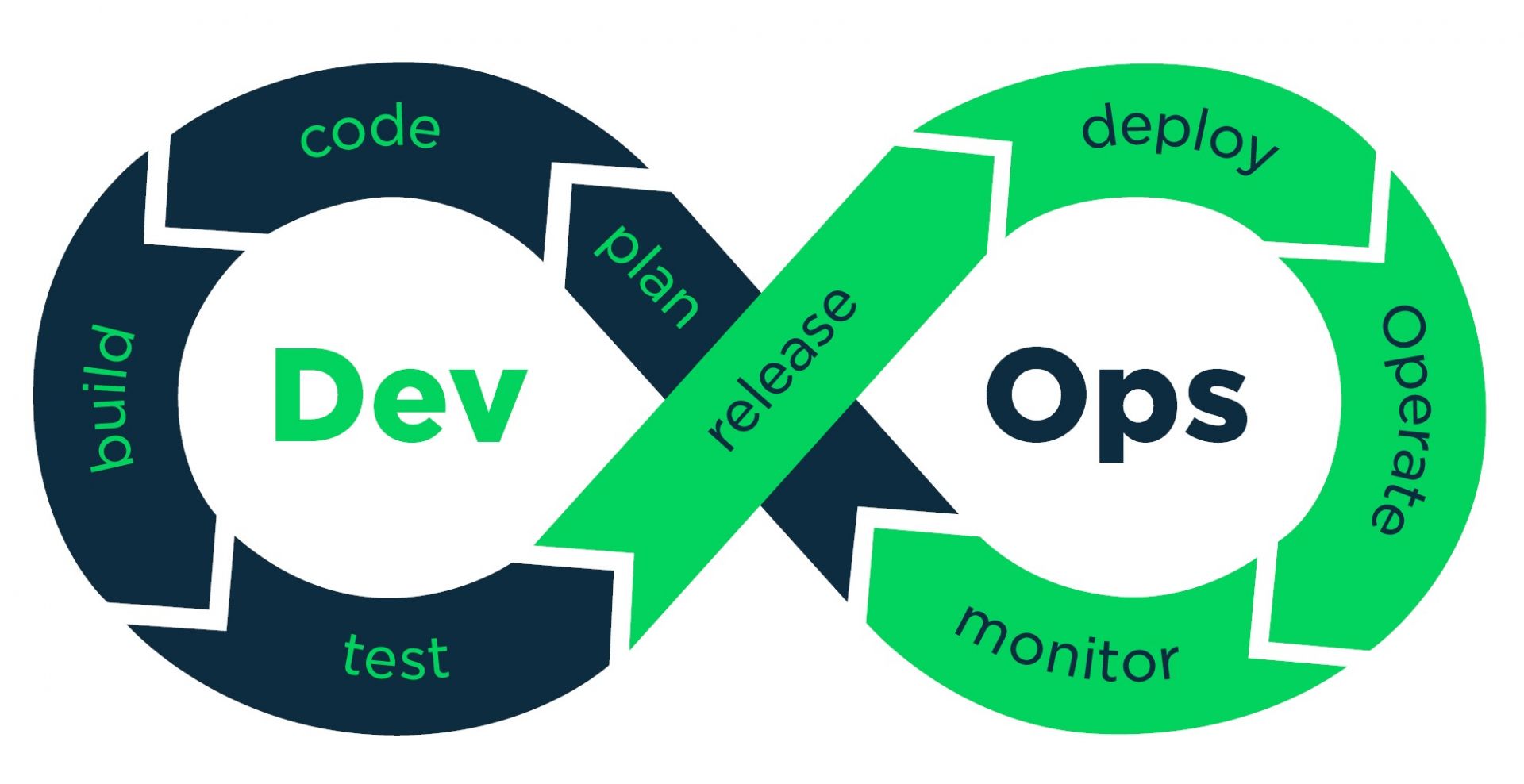
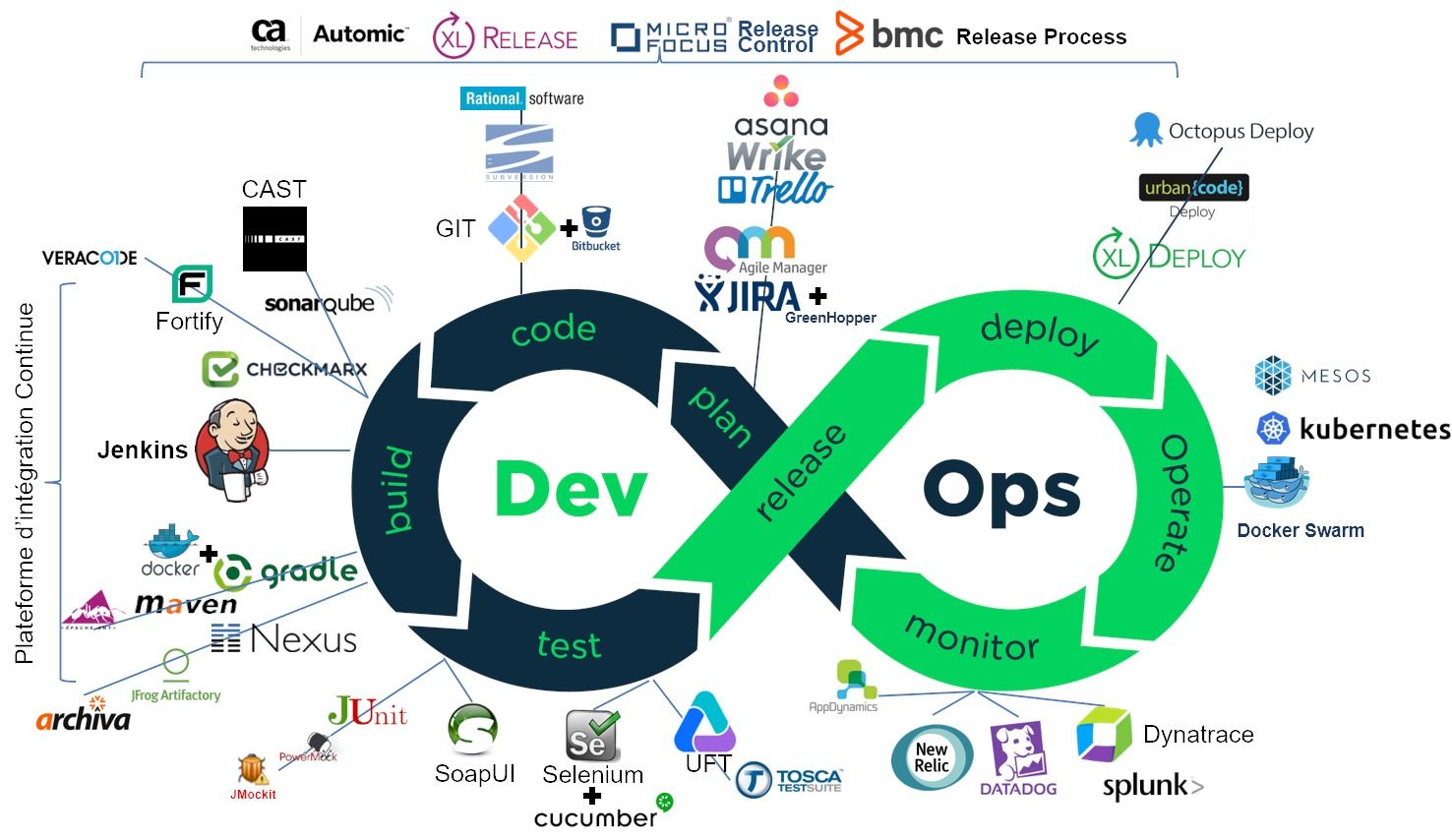
Sur le papier, rien ne ressemble plus à un pipeline DevOps qu'un pipeline de développement logiciel classique. Il faut planifier, coder, compiler et packager son logiciel, le tester, le livrer en recette avant de le déployer en production. Une fois en production, il faut le maintenir en condition opérationnelle et donc le superviser en permanence. La seule différence, c'est que ce cycle se déroule sur une période courte et fixe, et qu'on peut réitérer ainsi à l'infini (et au-delà). D'où le ruban de Moebius en symbole de ce cycle.
Afin d'automatiser ce cycle, il est nécessaire de mettre en oeuvre et d'intégrer de nombreux outils. Cela est souvent synonyme de coûts de licences et de maintenance éditeur et de coûts de mise en oeuvre et de maintien en conditions opérationnelles. La bonne nouvelle, c'est qu'il existe sur le marché de nombreux outils OpenSource, avec des versions de base gratuites et des versions payantes pour ceux qui ont besoin de fonctions avancées. La mauvaise nouvelle, c'est que l'OpenSource bascule rapidement d'un fork à l'autre ou d'un outil à un autre. Il faut donc être capable de suivre.
Vu de manière linéaire, le pipeline, avec ses outils, c'est plutôt çà :
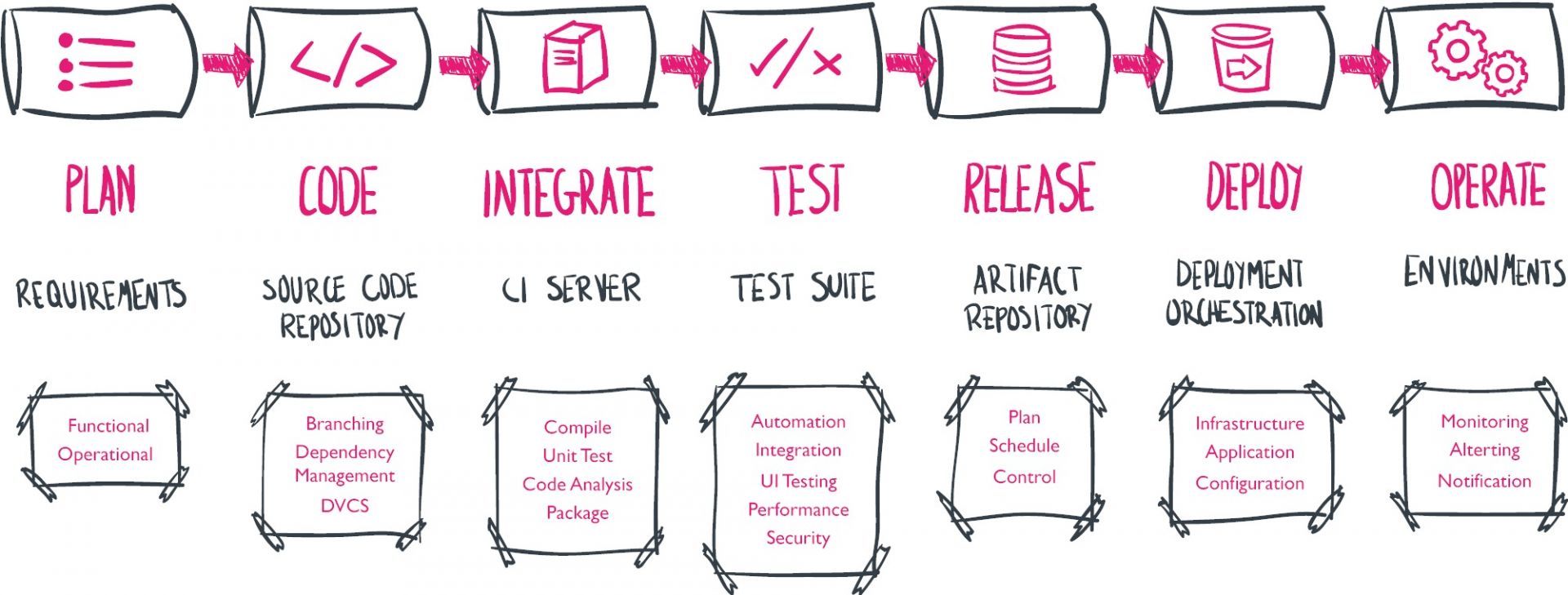
Je vais donc vous présenter ici les principaux outils qui constituent le pipeline DevOps. Évidemment, cet état de l'art ne vaut que les quelques mois qui viennent, mais c'est toujours intéressant d'avoir une photo du moment (Février 2018). J'aborde les outils du monde Open, car ils constituent la majorité des implémentations. Mais je n'oublie pas que le monde DevOps est aussi valable pour les développeurs Cobol et le mainframe. Cela intéresse certainement moins de personnes et je traiterai donc de ce sujet dans un article séparé.
Pour accéder directement aux différents thèmes ou phases du pipeline, cliquez simplement sur les liens ci-dessous.
| Plan → Code → Build → Test → Release → Deploy → Operate →Monitor |
Plan
 Pour commencer, il vous faut un bon outil de planification, adapté aux ou conçu pour les méthodes agiles. Histoire de pouvoir planifier ses sprints et ses « releases », suivre l'avancée de son backlog, et faciliter la collaboration entre équipes avec des tableau Kanban électroniques. Il existe deux grandes catégories sur le marché. Les outils orientés planification, relativement complexes et pas toujours faciles à maîtriser, et les outils orientés tâches, plus simples de prise en main. Ces derniers peuvent suffire si vous vous lancez dans l'Agile. Vous aurez ensuite la possibilité d'évoluer vers des outils plus complexes. Citons parmi les principaux outils :
Pour commencer, il vous faut un bon outil de planification, adapté aux ou conçu pour les méthodes agiles. Histoire de pouvoir planifier ses sprints et ses « releases », suivre l'avancée de son backlog, et faciliter la collaboration entre équipes avec des tableau Kanban électroniques. Il existe deux grandes catégories sur le marché. Les outils orientés planification, relativement complexes et pas toujours faciles à maîtriser, et les outils orientés tâches, plus simples de prise en main. Ces derniers peuvent suffire si vous vous lancez dans l'Agile. Vous aurez ensuite la possibilité d'évoluer vers des outils plus complexes. Citons parmi les principaux outils :
-
Micro Focus (anciennement HPE) Agile Manager
-
Microsoft Team Fondation Server (TFS)
-
CA Agile Central (anciennement Rally)
-
Atlassian Jira Software (connu pour son outil de bug tracking)
-
Trello (de la société éponyme, spin off de Fog Creek Software) : orienté tâches ;
NB : Trello a été racheté en 2017 par Atlassian mais garde pour le moment son identité. -
CollabNet ScrumWorks
-
Thoughtworks Mingle
-
Wrike (de la société éponyme)
-
Asana ((de la société éponyme) : orienté tâches
NB : un outil de gestion de projet offre notamment un découpage (WBS) et une gestion des tâches, un suivi des temps, du budget, un planning, une gestion des ressources, des outils collaboratifs (messagerie instantanée, wiki, espaces de partages etc.), des fonctions de rapports, de suivi des anomalies, etc.
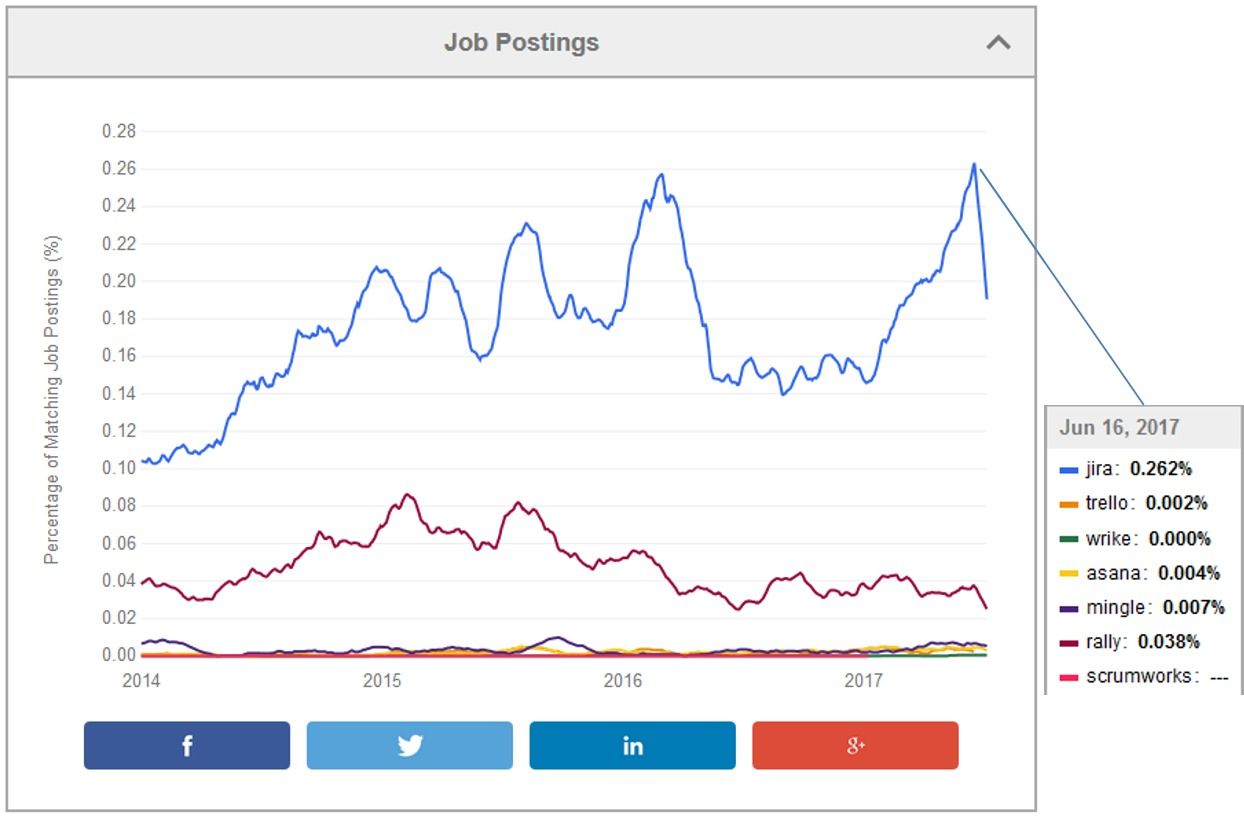
Si on regarde la fréquence des offres d'emplois sur la plate-forme Indeed, on voit que Jira arrive très loin devant ses concurrents. Il faut dire qu'Atlassian bénéficie d'une base installée importante et que son produit phare s'impose donc comme le produit leader. Mais Wrike ou Trello valent aussi l'essai...
Code
 Toute société de développement qui se respecte dispose d'un outil de gestion du code source. Cet outil permet non seulement de conserver le code source, mais de gérer aussi les différentes versions et branches du code. Sur le marché, il existe 2 générations d'outils. La première est centralisée : le code est stocké à un endroit et éventuellement répliqué, mais seule la base centrale fait foi. Ce qui peut être contraignant pour des équipes réparties géographiquement (qui n'a pas des équipes de développement en Inde ?). La seconde génération est décentralisée. Les répliques se synchronisent automatiquement. Parmi les premières générations d'outils, centralisés, on trouve :
Toute société de développement qui se respecte dispose d'un outil de gestion du code source. Cet outil permet non seulement de conserver le code source, mais de gérer aussi les différentes versions et branches du code. Sur le marché, il existe 2 générations d'outils. La première est centralisée : le code est stocké à un endroit et éventuellement répliqué, mais seule la base centrale fait foi. Ce qui peut être contraignant pour des équipes réparties géographiquement (qui n'a pas des équipes de développement en Inde ?). La seconde génération est décentralisée. Les répliques se synchronisent automatiquement. Parmi les premières générations d'outils, centralisés, on trouve :
-
Apache Subversion (SVN)
-
IBM Rational Clearcase
-
Microsoft Team Fondation Version Control (intégré à TFS)
Parmi les secondes générations d'outils, décentralisés, citons :
-
Git (l'outil) ou GitHub (le service) ; Outre le fait d'être décentralisé, Git gère plus facilement les différentes branches de codes et les fusions, surtout avec le produit Bitbucket d'Atalssian (qui peut utiliser Git ou Mercurial).
-
Mercurial Source Version Control (SVC)
-
Canonical Bazaar
-
Fossil Source Version Control
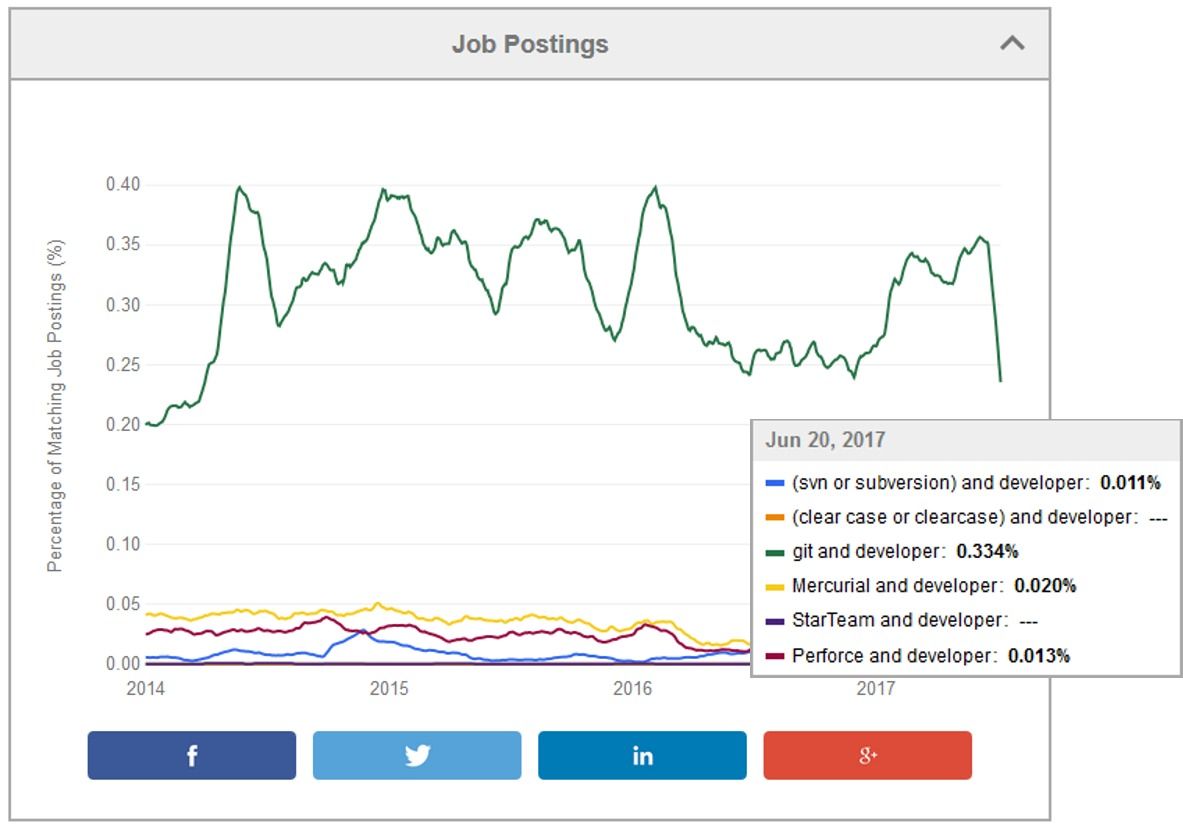
Git est de loin l'outil le plus utilisé, comme on peut le voir sur Indeed.
Build & Package - Integrate
 On appelle aussi la phase de "Build" phase "d'intégration" car c'est à ce moment que le code de chaque développeur est assemblé pour donner le produit final. Techniquement, on compile, on réalise l'édition de lien et on package le tout pour que l'exécutable puisse être déployé dans les différents environnements, y compris de production.
On appelle aussi la phase de "Build" phase "d'intégration" car c'est à ce moment que le code de chaque développeur est assemblé pour donner le produit final. Techniquement, on compile, on réalise l'édition de lien et on package le tout pour que l'exécutable puisse être déployé dans les différents environnements, y compris de production.
Pour intégrer, il faut un serveur d'intégration. Et en méthode agile, on appelle cela un serveur d'intégration continue (Continuous Integration Server ou CIS en anglais). Il y a quelques années encore, la bataille faisait rage entre Hudson et son clone Jenkins. Aujourd'hui, la question ne se pose plus : la plupart des utilisateurs ont basculé sur Jenkins. Il existe bien sûr quelques alternatives, mais c'est plus cher et moins bien :
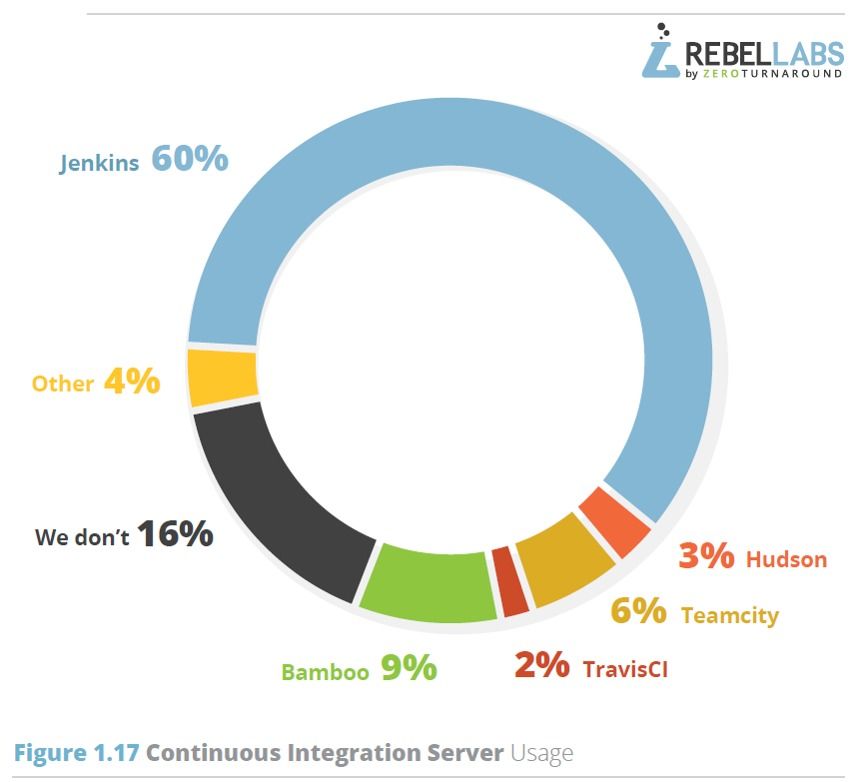
TFS a l'avantage d'être bien intégré à l'environnement de développement phare de Microsoft, Visual Studio, mais les compétences sur cette plate-forme sont assez "rares" sur le marché. Si l'on regarde les résultats de l'enquête de RebelsLabs, Jenkins domine le marché avec 60 % des parts, loin devant Bamboo ou Teamcity
Bien sûr, un logiciel comme Jenkins ne pourra pas répondre à tous les besoins d'une intégration continue. Rappelons que pour faire un bon pipeline, il vous faut être en mesure de compiler et de livrer tous les jours quelque chose de qualité. Cela suppose des retours rapides aux développeurs sur les modifications qu'ils ont apportés. Il vous faut donc intégrer quelques logiciels complémentaires, en sus des outils traditionnels de compilation, pour mesurer automatiquement la qualimétrie du code, détecter les failles (évidentes) de sécurité, ou encore tester de manière unitaire les différents modules.
Il faut donc veiller à ce que votre serveur d'intégration continue possède bien les bons plugins (ou interfaces) avec ses outils.
Dans la catégorie compilation
En sus de ces outils, si vous utilisez un système de container comme Docker en production, il vous faudra aussi bien sûr intégrer Docker dans votre processus de build. Coup de pot, graddle intègre justement un plugin pour Docker.
Dans la catégorie Analyse de code
-
SonarQube, capable d'analyser plus de 20 langages différents, du Java au Cobol en passant par le C et C++. Il y a aussi CAST bien sûr, mais ce dernier est incapable de sortir une analyse journalière du code. Autant dire que la philosophie de CAST ne colle pas du tout avec celle du DevOps et de l'Agile.
-
Checkmarx, outil permettant de scanner le code à la recherche de failles de sécurité. Cirons aussi dans les scanners sécurité Micro Fous Fortify et CA Veracode (module Developer Sandbox).
Dans la catégorie Tests unitaires, citons
-
JUnit, le plus populaire des xUnit, pour tester le code Java.
-
Jmockit et PowerMock, pour tester son code sans dépendre de connexion vers les composants tiers comme les bases de données par exemple.
-
SoapUI, qui permet de tester les API comme les Web Services. Il permet aussi bien d'autres choses au passage.
Enfin, dans la catégorie "référentiels de composants", qui vous permettent de stocker et gérer le résultat de votre compilation/édition de lien, citons :
-
Sonatype Nexus, qui peut résoudre des dépendances externes en "cachant" pour vous les composants externes à votre projet. Il fait aussi office de proxy Internet permettant de récupérer les composants disponibles sur Internet.
-
Apache Archiva
-
JFrog Artifactory
Chaque outil dispose généralement d'une barrière de qualité (quality gate). Si votre score Qualité/Sécurité est trop faible, votre code est recalé et ne sera pas déployé. En revanche, si votre score est suffisamment élevé, alors votre code sera compilé et poussé vers la prochaine étape. Généralement celle des "Tests fonctionnels".
Test
 L'étape la plus importante dans la vie d'un logiciel est la phase de tests. Et des tests, il y en a. A croire qu'on ne teste jamais assez...ce qui n'est pas faux. La qualité du code est directement corrélée avec le nombre de tests.
L'étape la plus importante dans la vie d'un logiciel est la phase de tests. Et des tests, il y en a. A croire qu'on ne teste jamais assez...ce qui n'est pas faux. La qualité du code est directement corrélée avec le nombre de tests.
-
Les tests d'intégration système (ou System Integration Tests) qui permettent de tester l'application intégrée dans son écosystème (référentiels, applications amont et aval, etc.)
-
Les Tests fonctionnels (ou Functionnal Integration Tests), qui permettent de valider les fonctions de l'application. Ils incluent les tests bilatéraux (d'application à application) et les tests de bout en bout (déroulant l'ensemble du processus).
-
Les tests de non-régression (TNR ou Regression Tests) : ce sont des tests fonctionnels ayant déjà été exécutés lors de la précédente recette et qui permettent de vérifier que les évolutions introduites dans la nouvelle version ne font pas dysfonctionner les précédentes fonctions livrées.
-
Les tests d'acceptation utilisateurs (UAT). Ils permettent de vérifier la conformité du produit final grâce à des scénarios réels (et avec des utilisateurs réels). C'est une sorte de phase de béta test, juste avant la publication du produit.
-
Les tests de performances (ou Capacity Tests) : ce sont les plus compliqués à réaliser. Il faut les réaliser quand l'application est assez stable pour passer sur le banc d'essai, mais sans qu'il soit trop tard pour changer quoi que ce soit.
-
Les tests de sécurité. De la même manière, on peut aussi tester la sécurité de l'application en même temps que ses performances.
 L'idée générale est d'automatiser un maximum de tests. Les tests unitaires sont généralement pris en charge lors de l'intégration. Les TNR sont de bons candidats, car ces tests ont déjà été exécutés au moins une fois. Les tests de performances et de sécurité aussi. Les smoke tests, ou sanity checks, ou encore tests de fumée, qui permettent généralement de valider la bonne livraison d'une version dans son environnement cible, sont aussi d'excellents candidats. En terme d'outils, on trouvera des choses très simples comme des choses très complexes.
L'idée générale est d'automatiser un maximum de tests. Les tests unitaires sont généralement pris en charge lors de l'intégration. Les TNR sont de bons candidats, car ces tests ont déjà été exécutés au moins une fois. Les tests de performances et de sécurité aussi. Les smoke tests, ou sanity checks, ou encore tests de fumée, qui permettent généralement de valider la bonne livraison d'une version dans son environnement cible, sont aussi d'excellents candidats. En terme d'outils, on trouvera des choses très simples comme des choses très complexes.
Dans la catégorie "Tests fonctionnels"
-
Selenium, pour tester toutes les applications avec une interface utilisateur basée sur un navigateur Web. Comme Selenium demande des compétences techniques importantes, il vaut mieux utiliser un outil compagnon, comme cucumber, pour s'aider dans la constitution des tests. Il a l'avantage d'être gratuit et bien intégré à Jenkins.
-
Micro Focus (Ex HPE) Unified Functionnel Testing (UFT). Le leader incontesté du marché. Il a aussi l'avantage d'être couplé à ALM (ex Quality Center), qui gère entre autre les cas de tests et les anomalies de recette. Il est capable de tester les applications Web, mais aussi les applications Client/Serveur et les applications sous Citrix. Il ne demande pas non plus de compétences en programmation Java. Ce qui constitue des plus non négligeables par rapport à Sélénium. Il existe un plugin Jenkins pour UFT mais sa mise en oeuvre vous demandera un peu plus d'huile de coude.
-
Tricentis Tosca, son challenger (voir figure ci-dessous).
-
Smartbear TestComplete
-
IBM Rational Test Workbench. Il faut mieux avoir la suite Rational et un bon Mainframe pour ce genre d'outils.
Dans la catégorie "Tests de performances"
-
Micro Focus (Ex HPE) LoadRunner. Le leader incontesté du marché.
-
Apache JMeter, une alternative OpenSoure
La figure suivante est issu du rapport de novembre 2017 du Gartner sur l'automatisation des tests logiciels. Comme le Gartner ne prend pas en compte les outils OpenSource (le CA est un critère important du Magic Quadrant), vous n'y trouverez évidemment pas Sélénium.
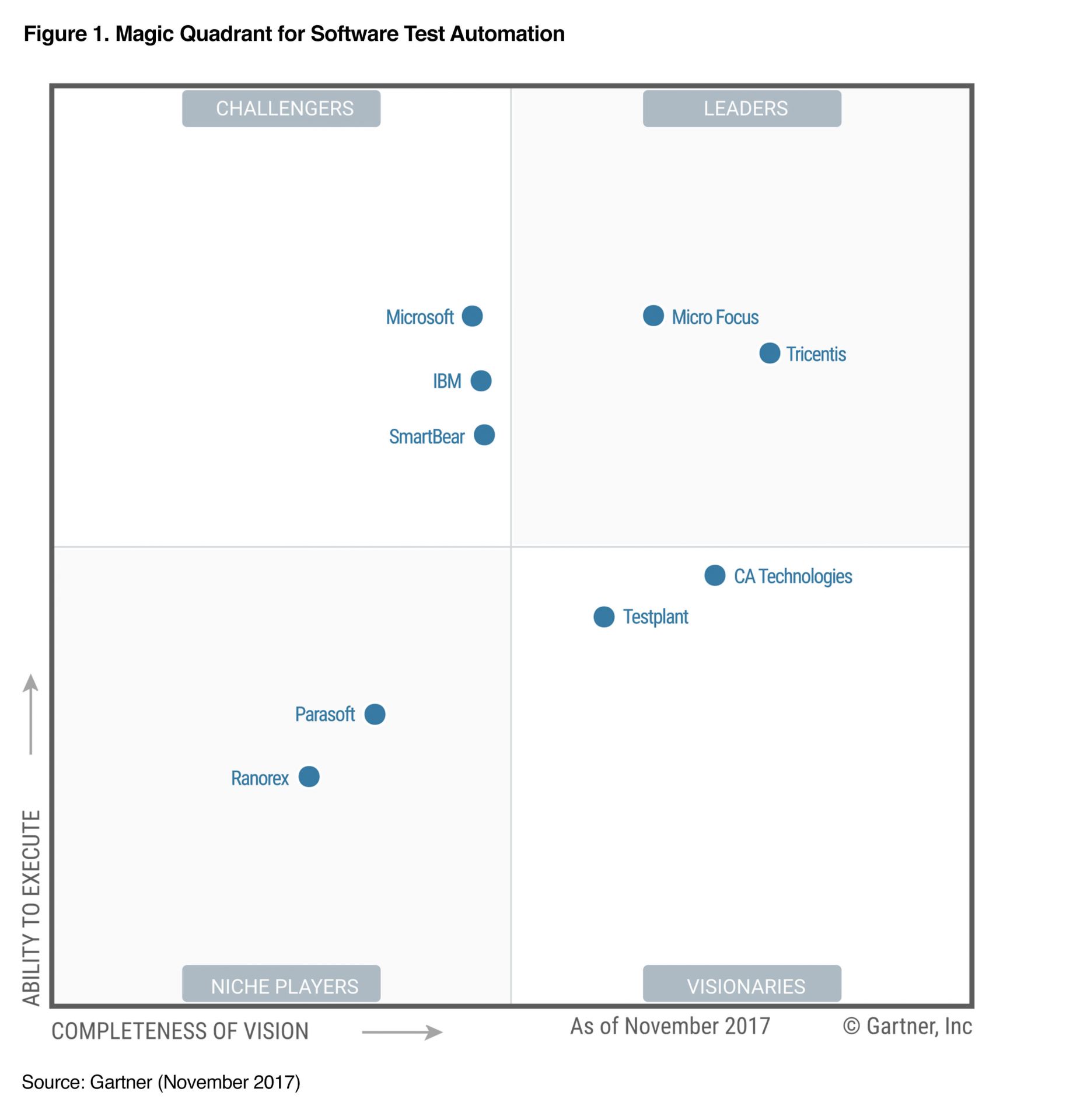
Dans la catégorie Sécurité, nous retrouvons les mêmes acteurs, tels que Checkmarx, CA Veracode et Micro Focus Fortify. Je ne reviendrai donc pas dessus. Vous pouvez les retrouver dans la section "Intégration continue".
Tous ces outils ont un point commun, ils nécessitent des données pour réaliser leurs tests. Ils peuvent donc générer leur propres données (données synthétiques) ou utiliser des données pré-existantes, chargées par un autre outil. C'est ce qu'on appelle le Test Data Management, dont les leader sont IBM InfoSphere Optim, Compuware FileAID et Informatica TDM. Mais ces outils sont hors champs de cet article. Notez simplement que vous aurez besoin d'y faire appel.
Release
 Quand votre logiciel a passé les tests d'intégration, il peut généralement être mis à disposition des testeurs. Tant qu'il était en phase de développement, on ne parlait que de build. Dès qu'il est jugé suffisamment stable pour être mis en recette, on parle de "release" (le développeur autorise la sortie de son produit en quelque sorte). Évidemment, avant qu'un produit ne soit mis en production, un certain nombre de versions applicatives va se succéder en recette pour aboutir à une release. On taggue alors le code, une fois le niveau de maturité atteint, avec un n° de version.
Quand votre logiciel a passé les tests d'intégration, il peut généralement être mis à disposition des testeurs. Tant qu'il était en phase de développement, on ne parlait que de build. Dès qu'il est jugé suffisamment stable pour être mis en recette, on parle de "release" (le développeur autorise la sortie de son produit en quelque sorte). Évidemment, avant qu'un produit ne soit mis en production, un certain nombre de versions applicatives va se succéder en recette pour aboutir à une release. On taggue alors le code, une fois le niveau de maturité atteint, avec un n° de version.
Pour gérer ces différentes releases, il faut un outil de gestion des référentiels de composants. Ces outils ont pour vocation de stocker mais aussi d'organiser et distribuer les logiciels et leurs bibliothèques, avec la bonne version. J'ai déjà évoqué ces produits dans la phase de build, les principaux sont Nexus, Archiva et Artifactory, mais il en existe bien d'autres naturellement.
Deploy
 Une fois votre produit testé et mis à disposition dans le référentiel de composants, il faut le déployer dans les différents environnements d'intégration, de recette, de pré-production et de production, sans parler de ceux de maintenance et de formation. Tout cela de manière automatisée si possible. Dans le plus simple des cas, il vous faut un outil qui sache déployer votre produit sur les différents environnements existants. Dans les cas les plus complexes, il faut aussi provisionner ces environnements, et ce de manière automatisée bien sûr.
Une fois votre produit testé et mis à disposition dans le référentiel de composants, il faut le déployer dans les différents environnements d'intégration, de recette, de pré-production et de production, sans parler de ceux de maintenance et de formation. Tout cela de manière automatisée si possible. Dans le plus simple des cas, il vous faut un outil qui sache déployer votre produit sur les différents environnements existants. Dans les cas les plus complexes, il faut aussi provisionner ces environnements, et ce de manière automatisée bien sûr.
Dans la catégorie Déploiement, on trouvera donc des outils comme :
-
Jenkins. En sus d'assurer l'intégration continue, Jenkins est aussi capable de faire du déploiement continu. Mais cela reste assez rudimentaire. Pour des outils un peu plus évolués, il faut s'orienter vers des outils payants, qui offrent de nombreux plugins et interfaces.
-
Electric Cloud ElectricFlow
-
XebiaLabs XL-Deploy. Un des leaders en France.
-
CA Technologies Automic Release Automation (rachat). Notons qu'Automic a réalisé un belle cartographie des différents outils, qui vaut le coup d'oeil.
-
Octopus Deploy
-
IBM UrbanCode Deploy (rachat)
Dans la catégorie Provisionning, on trouvera donc des outils (tous ont une version OpenSource) permettant de décrire son infrastructure par de simples lignes de "code" (Infrastructure as a code) comme :
-
Chef. Notons que Chef dispose aussi d'un outil de déploiement, ChefAutomate...Chef s'appuie sur Git et Ruby, il vaut donc mieux que vous ayez ces 2 produits en magasins. Chef est intéressant pour tous ceux qui cherche une solution mature fonctionnant dans un environnement hétérogène.
-
Puppet. Comme son concurrent, Puppet dispose aussi d'un outil de déploiement, Puppet Pipelines...Puppet est aussi un bon choix d'outil stable et mature, fonctionnant dans un environnement hétérogène et maitrisant bien le DevOps.
-
Ansible. Sans doute le plus simple des 3 produits, et fonctionnant sans agent, ce qui fait son succès, mais aussi le plus limité de ce fait.
-
Mentionnons aussi SaltStack et Fabric, des outils assez frustres de déploiement mais qui ont l'avantage d'être simples et gratuits.
Vous pouvez naturellement coupler Puppet ou Chef avec XL-Deploy par exemple, de manière à assurer la cohérence de votre déploiement avec celui du provisionning et de la gestion de la configuration de l'infrastructure.
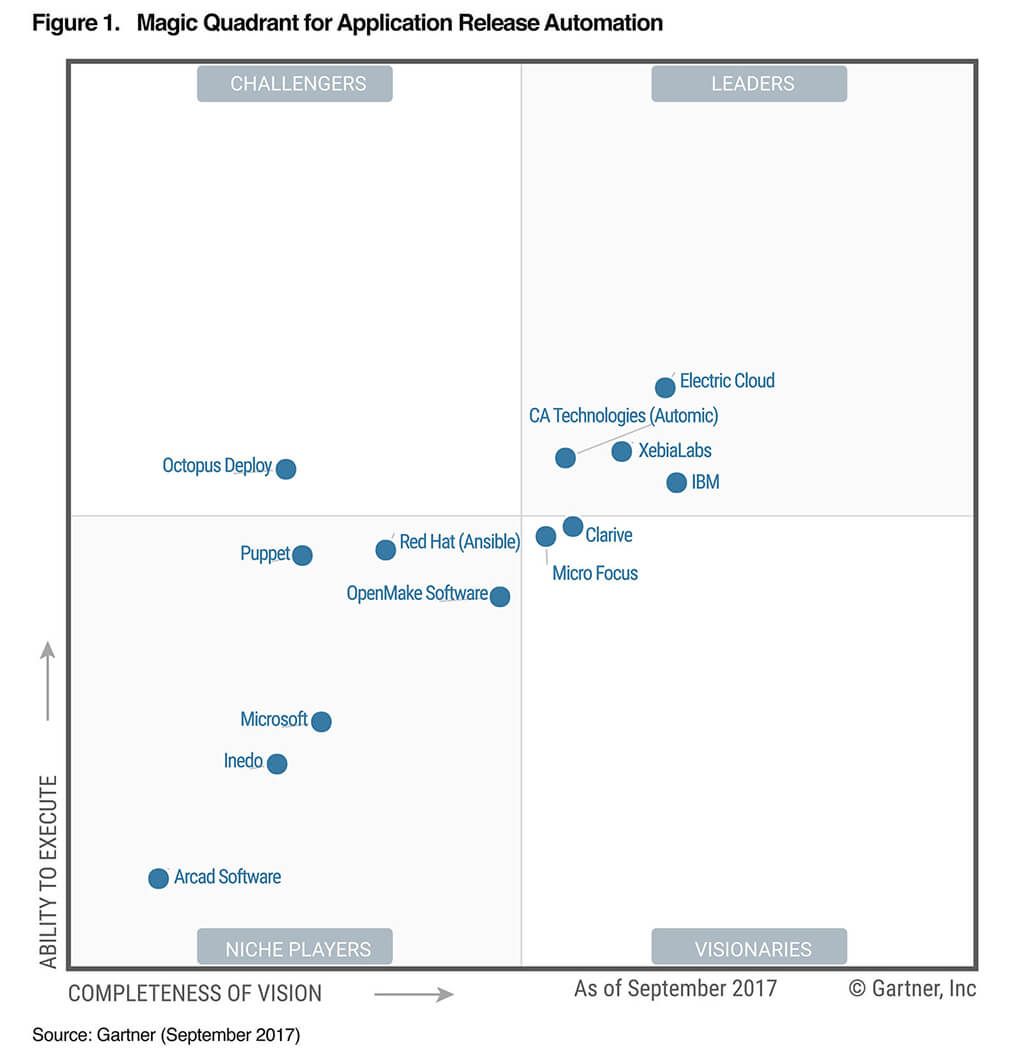
La figure suivante est issu du rapport de septembre 2017 du Gartner sur l'automatisation des deploiements des applications. Comme le Gartner ne prend pas en compte les outils OpenSource (le CA est un critère important du Magic Quadrant), vous n'y trouverez évidemment pas Jenkins, ni Chef, mais Puppet et Ansible y figurent en bonne place.
Maîtrise du processus de bout en bout
Nous venons de passer en revue les différentes produits de notre pipeline, et l'on serait tenter de s'arrêter ici. Nous avons en effet un outil pour planifier, gérer notre code, construire et packager notre produit, le tester, gérer les différentes releases et un outil pour les déployer. Mais n'oublions pas que la base de l'Agile, c'est Culture, Automation, Measurement and Sharing. Culture et Partage ne sont pas vraiment les sujets de cet article mais Automatisation et Mesure le sont totalement.
 Pas étonnant donc que l'on trouve avec l'émergence du DevOps des outils permettant de suivre son processus de release de bout en bout, du build au déploiement en production, et de pointer les dysfonctionnements, là où ça fait mal et ce qu'il faut améliorer pour disposer d'un pipeline le plus fluide possible. On n'améliore que ce que l'on mesure après tout...
Pas étonnant donc que l'on trouve avec l'émergence du DevOps des outils permettant de suivre son processus de release de bout en bout, du build au déploiement en production, et de pointer les dysfonctionnements, là où ça fait mal et ce qu'il faut améliorer pour disposer d'un pipeline le plus fluide possible. On n'améliore que ce que l'on mesure après tout...
-
L'outil le plus connu est certainement XebiaLabs XL-Release. Il permet de modéliser puis de superviser les livraisons logicielles, il orchestre les tâches au sein des équipes IT, du développement à la mise en production en passant par la recette. XL Release fournit des tableaux de bord de bout-en-bout, des outils d’analyse et de rapports approfondis et est facile d’utilisation. Il vous donne ainsi une chance de réduire les délais de livraison et d'améliorer les processus de livraison. L'outil dispose de nombreux plugins luis permettant de se brancher au pipeline DevOps, de l’intégration continue au provisionnement et au déploiement continu.
-
IBM UrbanCode Release
-
CA Technologies Automic Release Automation
J'aborde le sujet de l'orchestration des processus DevOps en dernier, mais ce n'est pas forcément le dernier outil à mettre en oeuvre. Si vous souhaitez en effet savoir par où commencer et où porter vos efforts, peut-être faut-il commencer par cette étape. Cela vous permettra de modéliser vos processus actuels avant de commencer à les améliorer.
Operate
 Nous abordons enfin pour terminer le sujet le plus vaste, celui des Ops. Il s'agit de maintenir en condition opérationnelle l'infrastructure et les applications qui tournent dessus. Un sujet vieux comme le monde. Je ne vais donc pas vous refaire le monde. Il est trop vaste. Mais s'il est un sujet qu'on ne peut éviter en parlant du DevOps, c'est bien celui des conteneurs (containers). Les conteneurs ont été inventés en 2004 par Sun (ce n'est donc pas une innovation récente comme certains ont tendance à l'affirmer un peu vite), mais ils connaissent depuis peu un énorme succès. Mais diantre pourquoi maintenant ?
Nous abordons enfin pour terminer le sujet le plus vaste, celui des Ops. Il s'agit de maintenir en condition opérationnelle l'infrastructure et les applications qui tournent dessus. Un sujet vieux comme le monde. Je ne vais donc pas vous refaire le monde. Il est trop vaste. Mais s'il est un sujet qu'on ne peut éviter en parlant du DevOps, c'est bien celui des conteneurs (containers). Les conteneurs ont été inventés en 2004 par Sun (ce n'est donc pas une innovation récente comme certains ont tendance à l'affirmer un peu vite), mais ils connaissent depuis peu un énorme succès. Mais diantre pourquoi maintenant ?
Un container, c'est une autre façon d'aborder la virtualisation. Ici, pas d'OS virtuel émulé, on fonctionne avec l'OS du système hôte. C'est plus simple et plus rapide. Mais du coup, tous les containers partagent le même OS et surtout les mêmes ressources. Impossible de dédier un processeur ou de la mémoire à un container donné, contrairement aux machines virtuelles.
De fait, un container est plus adapté qu'une machine virtuelle complète pour faire tourner les micro-services. Dédier une machine virtuelle complète pour y faire tourner un petit micro-services, cela fait un peu riche, vous en conviendrez. Pourquoi alors ne pas faire tourner plusieurs micro-services dans une même machine virtuelle ? Parce que l'on perdrait alors en agilité. Tout ce qui se trouver dans la machine virtuelle doit par définition partager la même pile logicielle (les mêmes versions de bases de données, de serveurs d'application, etc.). Or un micro-service évolue très vite et indépendamment des autres micro-services, selon la philosophie DevOps. D'où le retour en grâce des conteneurs.
Le conteneur facilite aussi grandement la vie des développeurs. Car le conteneur embarque toutes les dépendances applicatives. Le code, les éventuels runtime, les outils système, toutes les bibliothèques nécessaires et le paramétrage de l'application. Il suffit donc de construire son application dans son conteneur pour être capable de la déployer et de la faire tourner dans n'importe quel environnement, pourvu que celui-ci dispose d'un gestionnaire de conteneurs.
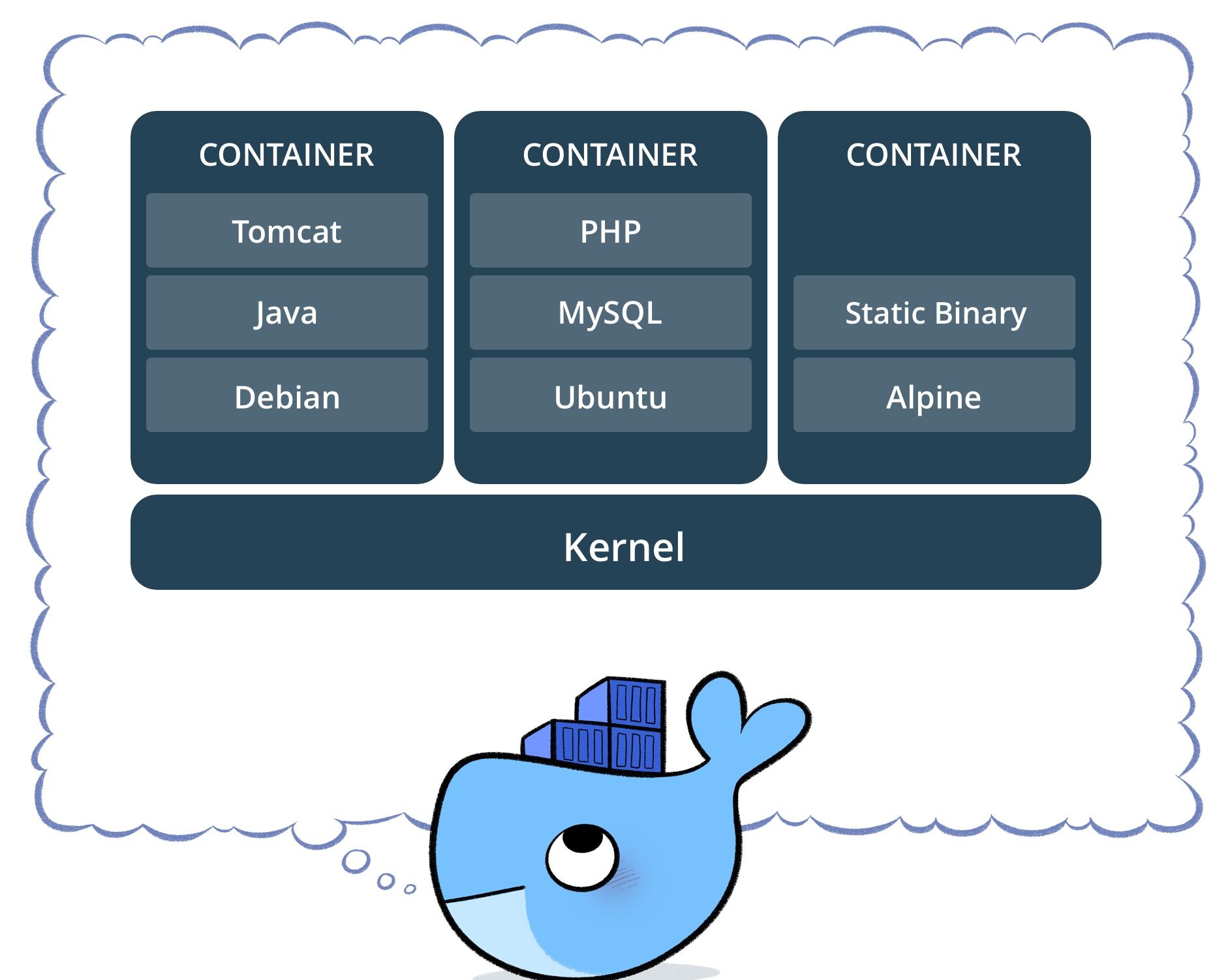
Parmi les fabricants de systèmes de conteneurs, nous trouvons :
-
Les conteneurs Linux LXC
-
Docker (qui n'est qu'une évolution des conteneurs LXC) et Docker Swarm pour la gestion des clusters, du routage, de la scalability.
-
Apache Mesos ; ce n'est pas un système de container mais plutôt un OS distribué supportant un système de container tel que Docker. Intéressant pour sa scalability.
-
Kubernetes : un système open source conçu à l'origine par Google et offert à la Cloud Native Computing Foundation. Il vise à fournir une « plate-forme permettant d'automatiser le déploiement, la montée en charge et la mise en œuvre de conteneurs d'applications sur des clusters de serveurs ». A noter que Docker offre maintenant le support de Kubertenes dans la Docker Community Edition pour les developpeurs sous Windows et macOS, et dans la Docker Enterprise Edition.
-
Les conteneurs Windows de chez Microsoft
-
et bien d'autres...
Bref, vous l'aurez compris, Docker, intégré dès le poste du développeur via Docker Compose, permet d'optimiser sa chaîne d'outil DevOps et facilite les déploiements en production. Encore faut-il que l'application soit conçue sur la base de micro-services bien sûr...
Monitor

La supervision est un sous-ensemble d'Operate. C'est sans doute un des principaux piliers des Ops avec la sauvegarde des données. Il n'y a donc rien de neuf dans le concept. Mais comme je l'ai dit précédemment, la mesure fait partie intégrante de la culture DevOps. Il est donc essentiel pour les devs comme pour les ops d'avoir des indicateurs sur le comportement de l'application. Et rien ne vaut une bonne supervision des performances de l'application.
Les principaux fournisseurs du marché sont :
A cela, on peut rajouter des outils permettant d'exploiter certaines données comme :
-
ELK : acronyme pour 3 projets open source, Elasticsearch, Logstash, et Kibana. Ce triptyque est très répandu et utilisé notamment pour la supervision de la sécurité, mais pas que.
-
Splunk : C'est une sorte de plate-forme d'Intelligence Opérationnelle (par opposition à la Business Intelligence) temps réel. On peut ainsi explorer, surveiller, analyser et visualiser les données machine via Splunk.
-
DataDog : DataDog est une excellente alternative à Splunk. La solution fonctionne aussi sur des environnements dans le Cloud.
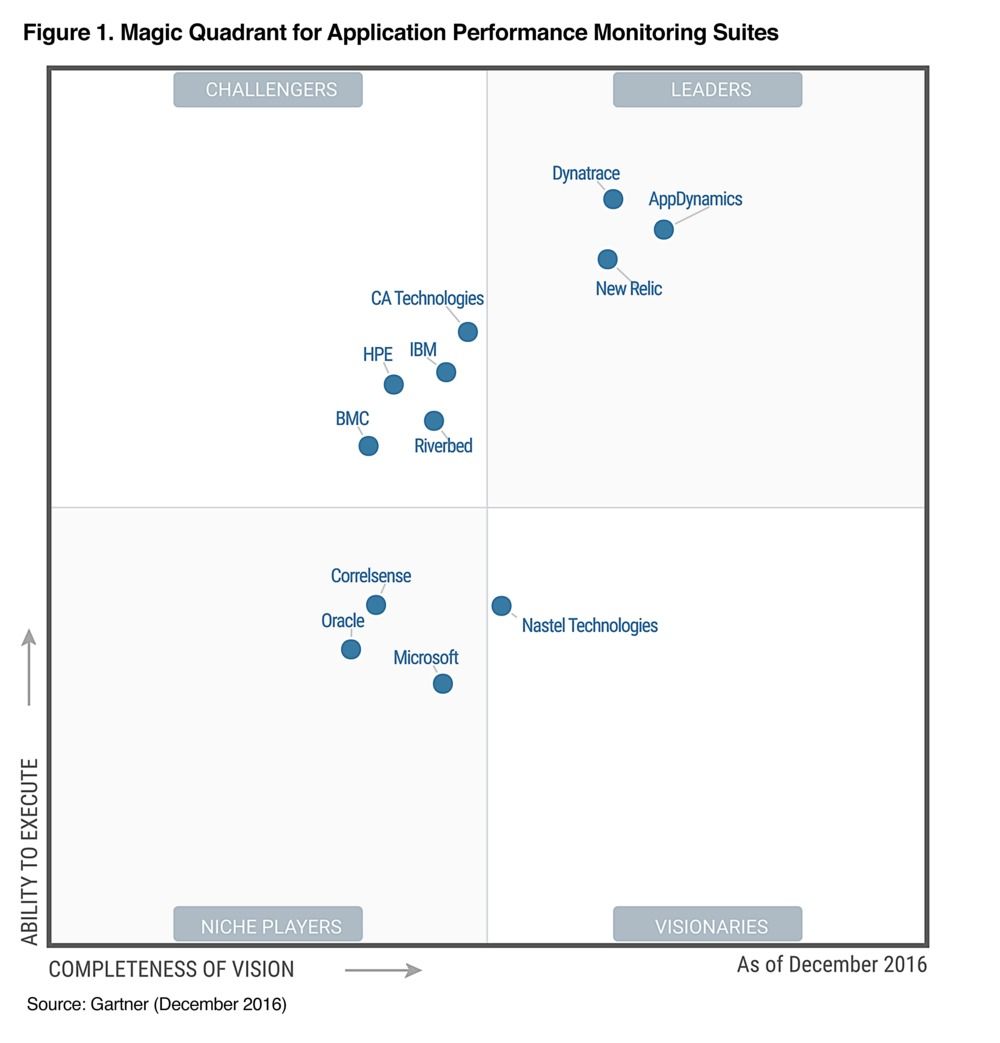
La figure suivante est issu du rapport de décembre 2016 du Gartner sur les outils de supervision des performances applicatives.
Conclusion
En résumé : pour construire votre pipeline, prenez un bon outil de planification agile comme Jira (si vous êtes familier avec les méthodes agiles), ou Wrike voire Trello pour démarrer, ajouter un bon gestionnaire de code source comme Git ou SVN (plus ancien), un bon serveur d'intégration continu comme Jenkins, assaisonnez d'outils complémentaires comme Maven ou Graddle, Junit SonaQube et Checkmarx pour les tests unitaires, la qualité et la sécurité. Mélangez ensuite avec Selenium ou UFT pour bien tester votre application et déployez le tout avec XL-Deploy. Il ne vous restera ensuite qu'à bien exploiter votre application et assurer sa disponibilité avec Docker Swarm et kubenetes et superviser ses performances avec Dynatrace et la sécurité avec Splunk ou ELK.
Bonne intégration et procédez par ordre, de l'intégration continue vers le déploiement continu : vous risqueriez sinon de finir comme sur la dernière image, ce serait dommage...