
Le bureau du DSI
Comment s'organiser pour télétravailler efficacement

Paris, le 29 mars 2020
Crise du Covid-19 oblige, nous voilà confinés depuis déjà 2 semaines. Et il a bien fallu apprendre à travailler à distance, depuis sa maison. Nous avons reçu quelques conseils pour bien s'organiser. J'en ai expérimenté quelques uns, j'en ai partagé d'autres. J'en ai faite une petite compilation.
1 - Garder la forme et mettre les formes

Vous connaissez tous cette fameuse citation, « Mens sana in corpore sano » ou « Un esprit sain dans un corps sain. ». Elle est issue de la dixième Satire de Juvénal. Oui je sais, cela vous fait une belle jambe. Justement, parlons-en. Pour garder la forme, il faut l'entretenir.
Ce n'est pas parce qu'on est confiné chez soi qu'il ne faut pas faire un minimum d'exercice, oublier de se raser ou de se brosser les dents. Rester en pyjama toute la journée n'est pas une option non plus. Il est donc important de conserver ces gestes du quotidien : faire sa toilette, se raser (pour les hommes), se maquiller (pour les femmes), s'habiller.
Conserver ces rituels liés au travail est important, car sinon la séparation entre vie professionnelle et vie personnelle s'estompe. Et on commence à tout mélanger. Un sentiment diffu d'être en vacances peut s'installer, avec malheureusement les contraintes dû au travail, et cet écart finit par créer un malaise.
Il faut aussi pouvoir se ménager un ou plusieurs créneaux pendant la journée pour faire un peu d'exercice. Une heure par jour suffit. Si vous le pouvez, profitez également du beau temps en sortant vous aérer sur votre balcon, ou dans votre jardin si vous avez la chance d'en avoir un. Rappelons qu'une heure de jardinage permet de bruler plus de calories qu'une séance de sport. Alors comme c'est le printemps, profitez-en.
2 - Aménager son environnement de (télé)travail

Travailler de chez soi depuis son canapé, on peut le faire pendant une petite heure ou deux. Mais passer toute la journée devant son ordinateur, en vidéoconférence ou au téléphone, ce n'est plus la même histoire. Il est alors indispensable d'aménager sa maison pour se constituer un petit espace à soi ou presque.
Plus facile à dire qu'à faire, surtout si l'on ne dispose pas d'une pièce dédiée à cet effet. Si vous ne disposez pas d'un bureau, vous pouvez encore requisitionner un bout de la table de la salle à manger, ou de la table basse du salon (moins confortable), ou investir les combles que vous venez de faire aménager, ou bien encore votre sous-sol.
Si vous vous installez dans une salle commune comme le salon, ou si vous partagez votre bureau avec votre conjoint ou conjointe, prévoyez des systèmes vous permettant de vous isoler pour travailler plus sereinement. Equipez-vous par exemple d'un casque à réduction de bruit active, du type Bose Headphones 700, Sony WH-1000XM3 (le 4 est en approche) ou Jabra Elite 85H. J'ai à ce propos écrit un article sur l'utilisation du Bose pour participer à des vidéoconférences.
Il faut aussi pouvoir compter sur un réseau domestique performant. Réseau domestique basé sur le WiFi ou câblé (il suffit de se brancher directement sur sa box Internet) et sur une connexion Internet haut débit (Fibre Optique ou ADSL).
J'avais écrit, il y a un bon moment déjà (whaou, 4 ans déjà), un petit article sur la meilleure façon de distribuer le WiFi dans sa maison. Les conseils que j'y donne sont toujours valables, même si à cette époque, les réseaux WiFi Mesh (réseaux maillés) n'existaient pas encore.
Si votre réseau WiFi sature, notamment parce que vos enfants suivent leurs cours sur Internet, que votre conjoint participe à une vidéoconférence en même temps que vous, sachez qu'aujourd'hui, il existe des réseaux WiFi Mesh tri-bandes (comme les Netgear Orbi, Asus ZenWiFi CT8/XT8, Linksys Velop), avec une bande dédiée pour la communication entre amplificateurs, laissant les 2 autres bandes de 2,4 Ghz et 5 Ghz disponibles pour les équipements domestiques et offrant ainsi des débits importants compatibles avec la vidéo (et donc la vidéoconférence). Je vous explique tout et comment optimiser la couverture de réseau WiFi dans cet article.
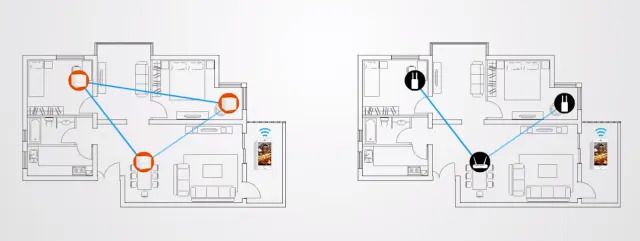
Exemple de réseaux WiFi maillés
Il vous faut naturellement un PC portable ou fixe et si possible un 2ème écran, plus grand que le simple écran de votre portable. Ceci vous permettra d'afficher des documents tout en travaillant par ailleurs sur votre messagerie ou en vidéoconférence.
3 - Utiliser les bons outils au bon moment

Messagerie électronique, vidéoconférence, téléphone, les outils collaboratifs ne manquent pas. Mais encore faut-il savoir les utiliser à bon escient. Voici donc un petit tour d'horizon et quelques conseils de bon sens, que nous appliquons tous généralement de façon assez intuitive.
- Le téléphone (fixe ou mobile) : un appel est généralement intrusif et oblige votre correspondant à interrompre son travail. Réservez-le aux sujets urgents et importants ;
- La messagerie instantanée ou Chat (Google Hangouts, Microsoft Teams, WhatsApp, Messenger, Slack, Discord, RocketChat, etc.) : elle présente l'avantage d'échanger par écrit et en mode synchrone (votre correspondant vous répond généralement immédiatement) ou au pire en mode asynchrone (il répondra quand il sera disponible, mais dans ces cas là, autant utiliser la messagerie) ;
- La visioconférence* (Google Meet, Microsoft Teams ou Skype, Zoom, Cisco WebEx, ou les outils sur smartphones comme WhatsApp, Messenger, Facetime, Google Duo) : elle permet d'organiser des réunions dans lesquelles vous pourrez vous voir, partager des documents ou votre écran. Privilégiez des formats courts (1 heure max), opérationnels avec un ordre du jour, un plan d'actions et établissez un compte-rendu (comme d'habitude bien sûr);
- La messagerie électronique ou mail (Office365, GMail, Lotus, etc.) : utilisez le mail pour des sujets complexes qui nécessitent de conserver un écrit.
En sus de ces outils de communication, privilégiez les outils collaboratifs :
- Les documents partagés (Google GSuite ou Miscosoft Office365) : Ces outils permettent de collaborer simultanément dans un même document partagé dans le Cloud, que ce soit un document Word/Doc, une présentation Powerpoint/Slides ou une feuille Excel/Sheet.
- Les tableaux blancs (Microsoft Teams - tableau blanc intégré - ou Google Jamboard) : ces outils permettent de dessiner, coller des post-it, écrire, comme sur un vrai tableau de salle de réunion. Rappelonns qu'un dessin vaut mieux qu'un long discours.
- Les tableaux Kanban (Trello, Asana ou Wekan - si votre entreprise a mis cet outil en oeuvre) : organisez votre travail d'équipe à travers des tableaux partagés.
- Les drives (espace de stockage dans le Cloud comme Microsoft OneDrive, Google Drive, DropBox, Box, etc.) : échangez des documents volumineux ou non en toute confidentialité.
(*) Pour profiter de la visioconférence, il faut naturellement disposer d'une WebCam sur son PC Portable. Et espérer que tous vos correspondants disposent d'un équipement similaire. Mais tout le monde dispose d'un smartphone, et donc d'une caméra et d'une app de visioconférence.
Si vos correspondants ont encore la chance de pouvoir se réunir dans une salle de réunion (en respectant les distances de sécurité), ils devront également utiliser le même système de visioconférence, avec en complément une caméra 360 avec focus automatique sur l'intervenant, telle que Owl Meeting Pro.
4 - Appliquer les bonnes pratiques

Disposer d'un bureau et des bons outils ne suffit malheureusement pas à se sentir à l'aise en télétravail. Comme disait Aristote, « l'homme est un animal social ». Notre cerveau comporte des neurones miroirs qui nous permettent spontanément d’entrer en empathie avec d’autres. Cette empathie nous nourrit, elle génère un confort, une appartenance, élargit le corps social au vivant. Elle cultive notre intuition.
En télétravail, nous sommes isolés même si connectés en permanence. Il faut donc restaurer les relations sociales en instituant quelques rituels. Ils peuvent vous paraître futiles, mais ils sont en réalité très importants.
- Dites bonjour le matin à votre groupe / équipe, de préférence à travers la messagerie instantanée (Chat).
- Faites un point régulier, ne serait-ce qu'une demi-heure et instaurez un rituel régulier tous les jours.
- Faire des pauses pendant la journée, et instaurez une « télépause café » avec vos collègues. Sachez que le fait de travailler sans voir vos interlocuteurs vous impose une charge cognitive plus importante que d'habitude. Votre cerveau travaille en effet pour imaginer votre interlocuteur.
Le télétravail introduit aussi un flou entre le monde professionnel et personnel. Car vous travaillez maintenant chez vous. Il faut donc réintroduire une séparation symbolique entre vos activités professionnelles et personnelles, par exemple en fermant complètement votre ordinateur à 18 heures et en désactivant les applications de travail de votre téléphone.
Car votre cerveau a besoin de déconnecter pour bien fonctionner. Ne pas déconnecter vous expose à une baisse significative de votre efficacité au travail. C'est d'ailleurs pour cela que le législateur à introduit un droit à la déconnexion.
Le droit à la déconnexion permet à chaque collaborateur de ne pas se connecter aux outils numériques, lire et/ou répondre aux mails, SMS ou appels en dehors des horaires habituels de travail et ce, afin d’assurer le respect des temps de repos.
5 - En conclusion
Voilà à ce jour mes conseils pour bien télétravailler. Ils ne constituent évidemment pas une liste exhaustive des bonnes pratiques. Si vous avez vous même des conseils à suggérer, n'hésitez pas à laisser un commentaire.
Et en bonus, un peu d'humour
Les grandes évolutions du Système d'Information
Paris, le 14 août 2019
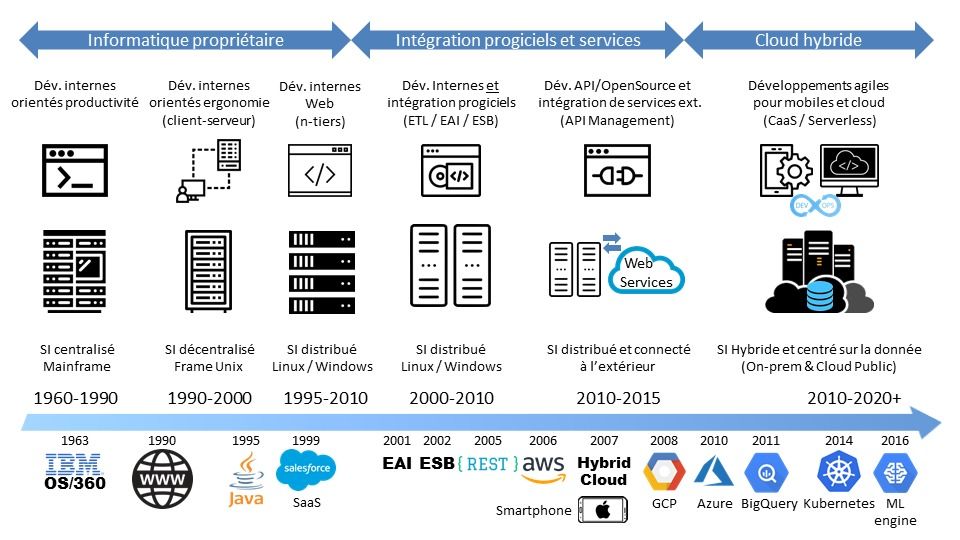
Retracer les évolutions des Système d'Information (SI) est un exercice des plus classiques. Tous les cabinets de conseil dignes de ce nom pourront vous en parler. Alors dans ce petit billet, j'ai essayé de faire différemment : j'ai fait tenir cette évolution dans une seule figure.
C'est donc forcément une analyse très macroscopique. Mais cela permet de voir d'où on vient et vers où on va en matière de SI.
Une évolution en trois phases
J'ai pour ma part identifié à ce jour trois grandes phases d'évolution du SI. A l'intérieur de chaque phase, on trouvera des évolutions structurantes bien sûr, mais qui n'ont pas fondamentalement changé la façon dont le SI fonctionnait.
1 ère phase : le SI propriétaire
Chaque entreprise, pour répondre à ses besoins, a développé ses applications et construit, brique fonctionnelle par brique fonctionnelle et serveur par serveur, son Système d'Information.
Chaque SI s'est bien sûr construit sur la base des technologies existantes de son époque. Dans les années 70, le langage de programmation Cobol et les mainframes dominaient, que ce soit ceux d'IBM, Unisys, Fujitsu, HP ou même Bull et son système d'exploitation GCOS.
Dans les années 90, les serveurs Unix ont pris le pas, et on a commencé à voir d'autres architectures apparaître : le client-serveur (que l'on a appelé rétrospectivement architecture 2-tiers) puis les architectures Web de type 3-tiers et n-tiers poussées par l'avènement d'Internet et l'apparition des langages de programmation Java et C#.
Passer des architectures monolithiques mainframe au client-serveur puis aux architectures n-tiers a demandé de très grosses évolutions technologiques. Mais cela n'a pas fondamentalement changé la façon dont on pensait le Système d'Information. Le SI était avant tout composé d'applications développées en interne avec peu d'interaction avec les autres systèmes.
2 ème phase : le SI intégré
Le passage à l'an 2000 a fait peur à tout le monde ; A tout le moins à ceux qui utilisaient l'informatique dans leur vie quotidienne. La plupart des programmes n'utilisaient alors que des dates codées sur 2 chiffres. Il a donc fallu, pour ceux qui s'en souviennent encore, engager des travaux de modernisation du SI. C'est alors que les progiciels et notamment les ERP (Enterprise Resource Planning ou Progiciel de Gestion Intégré en bon français) ont commencé à prendre une place prédominante, en remplaçant les vieux logiciels obsolètes dépassés par l'an 2000.
Il a donc fallu intégrer ces progiciels au reste du SI. Avec des applications désormais distribuées sur différents serveurs. Voire sur des serveurs virtualisés (VM). On a donc inventé des solutions comme l'EAI (Enterprise Application Integration) puis quand les interfaces Web se sont généralisées l'ESB (Enterprise Service Bus).
Et avec des interfaces Web et un réseau Internet plus fiable, on s'est aperçu qu'on pouvait faire de l'EDI (Echange de Données Informatisé) pour beaucoup moins cher et plus rapidement. On a donc commencé à intégrer les WebServices d'autres partenaires ou fournisseurs à son propre SI.
Plutôt que de développer des applications propriétaires, on a donc conçu le SI en pensant ses interfaces, ces fameuses API (Application Program Interface), permettant de communiquer tant en interne, entre le front office et le back office, qu'en externe avec d'autres SI. Avec en point central, la gestion de ces API : l'API Management, et un protocole simple : REST (REpresentational State Transfer).
3 ème phase : le SI hybride
Créer des API pour permettre à ses applications de communiquer, c'est bien. Mais généraliser les API à tout son SI, c'est encore mieux. C'est ce qui a donné naissance au Cloud et à l'automatisation d'un grand nombre d'opérations. Désormais, on ne gère plus son infrastructure par ses composants, mais par du code.
Le Cloud Public a-t-il pour autant changé notre façon de concevoir le SI ?
La réponse est non si l'on utilise le Cloud en mode IaaS (Infrastructure as a Service). Dans ce mode, l'entreprise loue des machines virtuels (VM) à son fournisseur et vient simplement installer ses applications dessus. Elle y gagne en souplesse, mais la location à long terme peut lui revenir plus cher que l'achat de serveurs en propre. Faire des économies avec le IaaS demande une gestion fine de sa capacité : il faut savoir couper les serveurs inutilisés (la nuit par exemple) et n'allouer des ressources qu'en cas de demande forte.
NB : Le mode PaaS (Platform as a Service) s'avère économiquement plus intéressant car il permet à l'entreprise de s'affranchir de toute la maintenance de la pile logiciel et du middleware, prise en charge par le fournisseur de Cloud. Mais il demande un peu de discipline car il faut naturellement que vos applications suivent les montées de version du fournisseur.
La réponse est oui si l'on commence à concevoir son SI en terme de progiciels loués en mode SaaS (Software as a Service), de micro-services, de conteneurs et d'application serverless (sans serveur). Tout en intégrant un maximum de services de son fournisseur, comme le Machine Learning, le BigData, la BlockChain, etc., et en veillant à ne pas créer trop d'adhérence entre son fournisseur et son SI.
Concevoir son SI n'est plus une histoire d'intégration de progiciels et d'API. Il s'agit plutôt d'intégrer des applications en mode SaaS avec ses propres applications, conçues en mode micro-services et Serverless. Ce terme barbare ne signifie pas que le serveur a disparu. Non, les ressources sont simplement allouées dynamiquement par le fournisseur de cloud au moment de l'exécution du code. Et vous ne payez qu'à l'usage réel (pay-as-you-go). Ce qui vous évite de réfléchir aux règles liées à l'élasticité (auto-scaling) de votre infrastructure, tout étant géré par le Cloud. Et ce n'est plus la fonction mais la donnée qui devient la brique première de votre SI.
On peut aussi coupler son code serverless à des micro-services hébergés dans des conteneurs, gérés par Kubernetes (le gestionnaire de conteneur le plus populaire loin devant Mesos ou Docker Swarm) en mode CaaS (Container as a Service).
Et comme le SI est encore en grande partie on-premise, il faut pouvoir gérer le mélange des genres, à savoir un SI hybride, hébergé dans le Cloud Public et dans des centres de traitement traditionnels. Car tout ne passera pas dans le Cloud Public quoiqu'on puisse en dire.
Les 3 phases du SI
La Gestion des Données de Test, le DevOps et le RGPD

Je vous ai parlé, il y a quelques temps déjà, de la façon dont on construit un pipeline DevOps. Et comment on pouvait ainsi automatiser sa chaîne de développement logiciel. Avec une étape cruciale qui est le "continuous testing" et des outils populaires comme Junit, SoapUI, Selenium ou encore HP UFT. Mais ce dont je ne vous ai pas parlé, c'est des données de tests. Car pour tester une fonction, il faut souvent des données. Et quand on automatise ses tests, c'est encore plus important. Car une seule donnée de test vous manque et tout votre pipeline est planté, comme disait la Martine.
Cela parait tellement évident qu'on oublie souvent de le dire. Et on passe donc trop rapidement sur un pan essentiel du DevOps qui est la gestion des données de test, ou le Test Data Management (TDM) comme diraient les anglo-saxons. Et pour citer le Gartner (2017),
« L’impact financier moyen de données de qualité médiocre sur les organisations est de 8,2 M$ par an »
Il est vrai qu'l s'agit surtout pour le Gartner de problème de qualité de données de production avant tout, mais ce coût inclut également ceux de test, n'en doutons pas. Voilà donc un article qui vous permettra de poser les bases d'une bonne gestion de vos données de tests, des bonnes pratiques aux outils.
Pourquoi gérer des données de test
Les données de tests servent avant tout aux tests fonctionnels. La gestion des données de test facilite la vie des testeurs, améliore leur productivité mais aussi la qualité de leurs tests. S'ils peuvent disposer de données de test pertinentes, représentatives et cohérentes, de manière simple et automatisée, les testeurs passeront moins de temps à générer, extraire ou charger leurs données et plus de temps sur leurs cas de test. Surtout qu'avec les environnements distribués que nous connaissons aujourd'hui, il devient souvent nécessaire d'émuler un service ou de bouchonner une partie des flux, et donc de disposer des données correspondantes rapidement.
Mais les données de test facilitent aussi la vie des développeurs. Surtout ceux qui sont en charge de la maintenance de l'application. Car pour reproduire une anomalie détectée en production et la corriger, il faut souvent pouvoir disposer des données à l'origine de l'anomalie. Il faut donc être capable de les mettre à disposition des développeurs rapidement. Mais encore faut-il s'assurer que vous respectez le récent Règlement Général sur la Protection des Données (RGPD) qui veut que vous protégiez les données personnelles de vos clients. Or des données qui sortent de la production sont fatalement plus exposées, les environnements de développement étant généralement moins sécurisés. La gestion des données de test peut répondre au problème en anonymisant ou masquant les données sensibles ou personnelles.
Enfin, les données peuvent aussi servir aux tests de performance. Pour vérifier la stabilité, la tenue à la charge ou déterminer le point de rupture d'une application, les tests de performances nécessitent des milliers voire des millions d'enregistrements. Ceci afin d'exécuter des tests sur plusieurs heures. Pas facile de disposer d'une telle volumétrie dans des environnements de non production. Le plus simple reste encore de charger l'image de la base de production sur votre banc de test. Tout en respectant encore une fois le RGPD.
Données de production ou données synthétiques
Maintenant que vous êtes convaincu qu'il est nécessaire de disposer de données pour vos tests, la première question à se poser est de savoir de quelles données vous avez besoin.
-
Vous partez de zéro et vous développez une nouvelle application ? Vous ne disposez donc évidemment pas de données réelles issues de la production. Il vous faut donc fabriquer des données de toutes pièces, des données synthétiques. Générer de la donnée synthétique, c'est assez facile. Il suffit généralement de la saisir au travers des écrans transactionnels de votre application. Cela a l'avantage de respecter l'intégrité fonctionnelle de la base de données, contrairement à un chargement direct en base de données. Sauf que la saisie est longue et fastidieuse. Oui mais...vous disposez d'un automate de test comme Selenium, HP UFT ou Tricentis Tosca. Il vous suffit alors de faire exécuter cette saisie par ces automates pour générer en masse des données artificielles avec lesquelles vous pourrez jouer ensuite vos scénarios de test. Il existe aussi des outils spécialisés, comme CA Test Data Manager, qui ont l'avantage d'offrir d'autres fonctions (que nous allons voir ci-après).
Pour faire simple, pour générer des données de test et exécuter vos scénarios, vous n'avez besoin que d'un automate type Selenium ou HP UFT. Un seul outil pour tout faire (ou presque). Le rêve ! -
Vous disposez d'un certain existant voire d'un existant certain. Comme des référentiels clients ou des applications tierces (une application de comptabilité générale par exemple) avec lesquelles votre application en cours de développement ou d'évolution doit communiquer. Et dans ce cas, rien ne vaut de bonnes données de production. Car créer des données synthétiques cohérentes sur l'ensemble des applications impliquées dans les tests peut s'avérer une vraie gageur. Alors que vos données de production sont naturellement cohérentes et tellement plus riches. Il suffit donc de capturer ces données de production pour constituer son jeu de test. Mais c'est là que les choses se corsent. Extraire manuellement les données de production de plusieurs systèmes différents hébergées sur des plates-formes hétérogènes peut vite devenir un vrai casse-tête. Il vous faut donc un outil pour gérer toute la complexité que cela peut représenter.
En conclusion, un outil de gestion des données de test s'avère vite indispensable dès que l'on dispose d'un existant et d'un patrimoine applicatif important. Cet outil aura l'avantage d'automatiser la capture des données de production, tout en gérant tout le cycle de vie de ces données.
Mais avant de passer en revue les meilleurs outils du moment, je vous propose de nous pencher avant sur la façon dont on met en œuvre une gestion des données de test. Dans la suite de ce billet, je me placerai dans le cas le plus fréquent, celui d'une application interconnectée à de nombreux autres systèmes applicatifs, impliquant une vraie gestion des données.
Commet mettre en œuvre une gestion des données de test
La mise en œuvre de la gestion des données de tests se décompose en 7 grandes étapes :
|
1 - Cartographier ses données 3 - Masquer les données sensibles 4 - Charger des sous-ensembles 5 - Contrôler automatiquement les résultats |
1 - Découvrir et cartographier les données de test
 Les données de production sont souvent réparties entre plusieurs applications, stockées dans différents formats et hébergées sur des plates-formes hétérogènes (Windows, Unix, Z/OS, OS/400, etc.). Ce ne serait pas drôle sinon. Mais pour capturer des données et à les mettre à disposition des testeurs, encore faut-il savoir où elles sont stockées et à quels systèmes elles sont liées.
Les données de production sont souvent réparties entre plusieurs applications, stockées dans différents formats et hébergées sur des plates-formes hétérogènes (Windows, Unix, Z/OS, OS/400, etc.). Ce ne serait pas drôle sinon. Mais pour capturer des données et à les mettre à disposition des testeurs, encore faut-il savoir où elles sont stockées et à quels systèmes elles sont liées.
Pour cela, il faut donc cartographier vos données, c'est à dire disposer d'un plan répertoriant vos données et leur localisation. Ce plan peut être établi manuellement mais cela est souvent fastidieux. L'outil de gestion des données de test vous aidera en découvrant automatiquement la façon dont vos données sont organisées. Comment ? Simplement grâce aux intégrités référentielles de vos bases de données. Évidemment, cela ne vous permettra pas de répertorier 100% de vos données, car certaines relations peuvent s'étendre sur plusieurs bases de données. Ces dernières peuvent d'ailleurs être hétérogènes (une base de type Oracle, une base MySQL et une base SQL Server) et stocker les données dans des formats différents. Mais cela servira de base de départ. Et cela n'est déjà pas si mal. Il vous faudra ainsi saisir à la main les relations fédérées entre bases de données.
2 - Extraire un sous-ensemble de données de production à partir de plusieurs sources de données Afin de constituer un jeu de données de test impliquant plusieurs applications, on pourrait simplement se contenter de "cloner" l'ensemble des bases de données de production. Mais les volumes que cela implique (et donc l'espace de stockage), les temps de traitement et les coûts que cela représente rendent vite cette solution inenvisageable.
Afin de constituer un jeu de données de test impliquant plusieurs applications, on pourrait simplement se contenter de "cloner" l'ensemble des bases de données de production. Mais les volumes que cela implique (et donc l'espace de stockage), les temps de traitement et les coûts que cela représente rendent vite cette solution inenvisageable.
L'extraction d'un sous-ensemble de données est donc sans doute la meilleure méthode pour vous constituer des jeux de données de test réalistes, représentatifs et cohérents. Il vous faudra sans doute procéder à quelques itérations pour trouver le bon sous-ensemble. Pas trop grand pour que vos tests soient faciles à exécuter, mais pas trop petits, sinon vos données ne seraient pas assez variées et vos tests pas ou peu représentatifs. Vous l'aurez compris, la difficulté de l'exercice consiste surtout à trouver les données de production qui remplissent les conditions de vos cas de test. Cela demande un peu de recherche, ce qui est souvent plus facile quand vous disposez d'un infocentre ou datamart. Vous pouvez aussi modifier légèrement vos données pour mieux les faire correspondre à vos cas de test.
Mais l'extraction n'est pas la seule méthode. Vous pouvez aussi cloner et virtualiser vos bases de données. Le clonage est une bonne vieille technique, bien maîtrisée par les administrateurs de base de données. Mais elle avait l'inconvénient de répliquer la totalité des volumes de production. Combinée à la virtualisation des bases de données, elle offre désormais des possibilités plus qu'intéressantes : un seul clone peut être virtualisé plusieurs fois de manière instantanée (comprenez par là que les données ne sont répliquées physiquement mais qu'elles existent pourtant) et donc servir plusieurs projets différents sans que les volumes s'en retrouvent multipliés.
Pour autant, le clonage et la virtualisation ne vous épargnera sans doute pas la préparation de sous-ensembles pour vos tests. Car il faut que ces derniers puissent être exécuter simplement et facilement. Il est bien plus facile de sélectionner un item (et toujours le même) parmi trois que parmi 10 000. Et de lancer un traitement sur 100 lignes que 1 millions.
3 - Masquer, pseudonymiser ou anonymiser les données sensibles ou personnelles Le récent Règlement Général sur la Protection des Données (RGPD ou en bon anglais General Data Protection Regulation - GDPR) impose aux sociétés de protéger les données de leurs clients. Et d'informer le régulateur si ces données venaient à être compromises. Les pénalités en cas de non-respect peuvent s'élever à 4% du chiffre d'affaire mondial de la société épinglée, même si cette dernière n'est qu'une petite filiale du bout du monde. Autant dire que vous avez intérêt à renforcer la sécurité de vos systèmes et de vos applications si ces derniers sont exposés ou vulnérables. Mais si la sécurité des environnements de production a toujours été stricte, celle des environnements de développements et de tests l'est généralement moins. Notamment en ce qui concerne l'authentification des utilisateurs. Les équipes de développement se font et se défont trop rapidement pour que les habilitations suivent dans les systèmes. Les développeurs ont donc pris l'habitude de se partager les login de test ou de désactiver simplement le système d'authentification.
Le récent Règlement Général sur la Protection des Données (RGPD ou en bon anglais General Data Protection Regulation - GDPR) impose aux sociétés de protéger les données de leurs clients. Et d'informer le régulateur si ces données venaient à être compromises. Les pénalités en cas de non-respect peuvent s'élever à 4% du chiffre d'affaire mondial de la société épinglée, même si cette dernière n'est qu'une petite filiale du bout du monde. Autant dire que vous avez intérêt à renforcer la sécurité de vos systèmes et de vos applications si ces derniers sont exposés ou vulnérables. Mais si la sécurité des environnements de production a toujours été stricte, celle des environnements de développements et de tests l'est généralement moins. Notamment en ce qui concerne l'authentification des utilisateurs. Les équipes de développement se font et se défont trop rapidement pour que les habilitations suivent dans les systèmes. Les développeurs ont donc pris l'habitude de se partager les login de test ou de désactiver simplement le système d'authentification.
Les données de test sont donc facilement accessibles et s'échangent souvent entre équipes, parfois délocalisées en Inde ou ailleurs. Autant dire que même avec un bon contrat et des clauses de confidentialité béton, vous n'êtes sûr de rien. Pour éviter tout risque de compromission, on a donc tendance à masquer ou anonymiser les données, ce qui rend leur valeur nulle pour un cyber-attaquant. Sans rentrer dans les détails, voici 3 techniques possibles :
-
Le masquage des données. Il suffit de remplacer une donnée par une autre non significative. Vous pouvez ainsi changer le numéro de téléphone de vos clients par une série de 0. C'est le plus simple à réaliser mais c'est aussi le plus intrusif. Car si votre test utilise cette donnée, il risque d'échouer lamentablement. Il existe bien sût plusieurs techniques de masquage, allant de la substitution de valeur fixe à la génération de valeurs en passant par la substitution de sources de données.
-
L'anonymisation des données. Cette technique a pour but de rendre toute identification impossible. En remplaçant le nom de votre client "Jean Chambard" par "John Doe", il devient théoriquement impossible de l'identifier. Mais ce n'est pas aussi simple que cela. Car avec le nom vient aussi souvent l'adresse, le numéro de téléphone, le n° d'INSEE, le n° de carte bleue, etc. Il est donc facile de remonter à la véritable identité de la personne si vous n'y prenez pas garde. Et par le jeu des recoupements, on peut obtenir des résultats surprenants. C'est pourquoi on a introduit la notion de pseudonymisation, dont parle tant le RGPD.
-
La pseudonymisation des données ressemble comme 2 gouttes d'eau à l'anonymisation. Sauf que si l'anonymisation n'autorise aucune faille dans l'identification, la pseudonymisation si. Identifier une personne via des données ne doit pas être possible, mais le fait de recouper plusieurs données distinctes reste autorisé. Charge à l'entreprise de bien protéger les données complémentaires qui permettraient cette identification.
Tout cela n'est pas forcément simple. Heureusement, la plupart des outils propose des mécanismes d'anonymisation ou de masquage. Comme des algorithmes permettant de générer des numéros de cartes bancaires conformes, des noms et prénoms, des numéros IBAN, etc.
A noter que puisque la plupart des outils savent manipuler les données dans tous les sens, ils savent aussi faire vieillir les données de test. Ce qui peut être intéressant lorsque votre campagne de test doit exécuter un test qui normalement se déroule sur plusieurs semaines dans la vraie vie.
4 - Charger le sous-ensemble de données dans les environnementsI cibles
Une fois votre jeu de données constitué puis anonymisé, il vous faut le charger dans l'environnement cible. Généralement, il s'agit de l'environnement de recette, mais cela peut aussi être un simple environnement d'intégration ou de maintenance. Tout dépend de ce que vous voulez faire (reproduire une anomalie de production, valider une nouvelle fonction, tester les non-régressions, etc.).
Le chargement des données de test est un traitement qui demande du temps (d'où la nécessité de constituer un sous-ensemble), sauf si vous utilisez une méthode de virtualisation des bases de données. Dans ce dernier cas, la création et mise à disposition des données de test peut être quasi immédiat.
Une fois vos données chargées, vous pourrez exécuter votre batterie de tests. Si cette dernière n'est pas concluante, il vous faudra corriger puis relancer vos cas de test. Mais pour cela, il vous faudra remettre vos données dans leur état initial. Il vaut donc mieux disposer d'une sauvegarde de votre jeu de données ou d'une photographie (snapshot) dans le cas de bases de données virtuelles. Cela parait évident mais il vaut mieux y penser avant qu'après. Ceci introduit une notion de contrôle de version des jeux de donnés, fonction que proposent certains outils.
5 - Contrôler automatiquement les résultats avant et après
Lorsque vous jouez des tests de non-régression (à tout hasard), vous connaissez déjà les résultats attendus. Et peut-être avez-vous déjà fait une sauvegarde de ces résultats ? Dans ce cas-là, tant mieux, car certains outils vous proposent de comparer les résultats des différentes campagnes de tests avec des données de référence. Et de mettre en exergue les différences, histoire d'identifier plus rapidement les régressions.
6 - Rafraichir ses données de test
 Une fois la campagne de test terminée et vos développements validés, votre environnement de recette se trouve dans un état incertain. Du moins en ce qui concerne les données, qui ont subi tout un tas de modifications et d'essais dans tous les sens. Et c'est pourquoi il est nécessaire de restaurer une certaine cohérence dans tout cela. Il faut donc procéder à intervalle régulier à une réinitialisation des environnements (on efface tout et on recommence, certains appellent cela un rafraichissement total) ou tout au moins à un rafraîchissement (partiel) des données. Cela consiste à mettre à jour un sous-ensemble des données de test (elles-mêmes déjà un sous-ensemble des données de production) avec les dernières valeurs des données de production.
Une fois la campagne de test terminée et vos développements validés, votre environnement de recette se trouve dans un état incertain. Du moins en ce qui concerne les données, qui ont subi tout un tas de modifications et d'essais dans tous les sens. Et c'est pourquoi il est nécessaire de restaurer une certaine cohérence dans tout cela. Il faut donc procéder à intervalle régulier à une réinitialisation des environnements (on efface tout et on recommence, certains appellent cela un rafraichissement total) ou tout au moins à un rafraîchissement (partiel) des données. Cela consiste à mettre à jour un sous-ensemble des données de test (elles-mêmes déjà un sous-ensemble des données de production) avec les dernières valeurs des données de production.
Certains testeurs protesteront car ce rafraichissement partiel ou total peut casser leurs tests. On peut alors procéder à un rafraichissement incrémental, consistant à ajouter à nos données de tests existantes de nouvelles données qui n'écraseront pas les anciennes. Pratique mais dangereux car votre environnement de test sera de plus en plus pollué par une redondance importante des données, dont une bonne partie dans un état incertain.
7 - Offrir les données en self-service et en automatique
 Enfin, pour gagner en agilité (nous sommes partis de notre pipeline DevOps rappelez-vous), il faut pouvoir automatiser l'alimentation des données de tests lors de l'exécution des TNR, eux-même pilotés par notre plate-forme d'intégration continue et notre automate de tests fonctionnels ; ou pouvoir déclencher l'extraction des données à la demande, au travers d'une interface en self-service, de manière à rendre les testeurs le plus autonomes possible.
Enfin, pour gagner en agilité (nous sommes partis de notre pipeline DevOps rappelez-vous), il faut pouvoir automatiser l'alimentation des données de tests lors de l'exécution des TNR, eux-même pilotés par notre plate-forme d'intégration continue et notre automate de tests fonctionnels ; ou pouvoir déclencher l'extraction des données à la demande, au travers d'une interface en self-service, de manière à rendre les testeurs le plus autonomes possible.
Certains outils disposent nativement de ces interfaces (un plugin avec Jenkin, un portail utilisateur en self-service). Mais pour certains, il faut développer une surcouche et se brancher sur les API de l'outil.
Voila nos grandes étapes de la gestion des données de test. Passons maintenant à la revue des meilleurs produits du moment (qui ne vaut que pour cette année 2018 donc).
Les meilleurs outils de gestion des données de test
Je liste ici les outils par ordre alphabétique et non par ordre de préférence, chacun aura sans doute son classement préféré, fonction de ses besoins et contraintes.
-
CA Test Data Manager : un des leaders du marché.
-
Compuware’s File-AID Data Management, combiné avec Test Data Privacy pour l'anonymisation des données
-
Delphix Test Data Management, une solution complète de virtualisation des bases de données
-
Doble Test Data Management
-
Ekobit BizDataX (une société croate)
-
Grid-Tools (pour référence, acquis par CA Technologies en 2015)
-
IBM InfoSphere Optim Test Data Management : un incontournable.
-
Informatica Test Data Management tool : un des leaders du marché avec IBM et CA.
-
Oracle Enterprise Manager : Oracle fournit des fonctions de Test Data Management avec son outil d'administration de ses bases de données (Modélisation, Création de sous-ensembles et anonymisation des données). Compte-tenu des parts de marché d'Oracle, c'est un incontournable...mais est-ce vraiment encore le cas ?
-
Original software Test Data Management
-
Solix EDMS Test Data Management
-
SAP Test Data Migration Server (un outil dédié aux solutions SAP, mais qui fait son job)
Les leaders du marché sont clairement Informatica, IBM et CA Technologies, suivi de Delphix qui possède une technologie innovante de virtualisation de bases de données et Compuware qui est un des rares avec IBM à couvrir à la fois les plates-formes Z/OS et Open (Windows, Unix, Linux). Mais le choix reste votre. N'hésitez pas à laisser vos commentaires sur ces produits ou sur la démarche de gestion des données de test en elle-même.
D'ici là, faites de bons tests...

Contruire un pipeline DevOps
Tous les spécialistes vous le diront, le DevOps, c'est une histoire de culture d'entreprise d'abord. Car il s'agit avant tout de faire collaborer des ingénieurs du développement logiciel avec des ingénieurs de la production informatique. Deux mondes qui ne partagent pas forcément les mêmes objectifs. Les premiers font des projets qui induisent fatalement des changements, tandis que les seconds sont les garants du bon fonctionnement du SI, et appréhendent par là-même tout changement qui pourrait mettre cette fiabilité en péril.
C'est ce qu'on appelle communément le mur de la confusion, mur qui se dresse entre Dév et Ops et qui les empêchent de collaborer. Difficile de travailler de concert quand on a des objectifs opposés et irréconciliables. Et ce ne sont pas les outils qui font collaborer les gens. Non, c'est la culture de la collaboration. En cela, les puristes ont raison.
La qualité au centre de tout
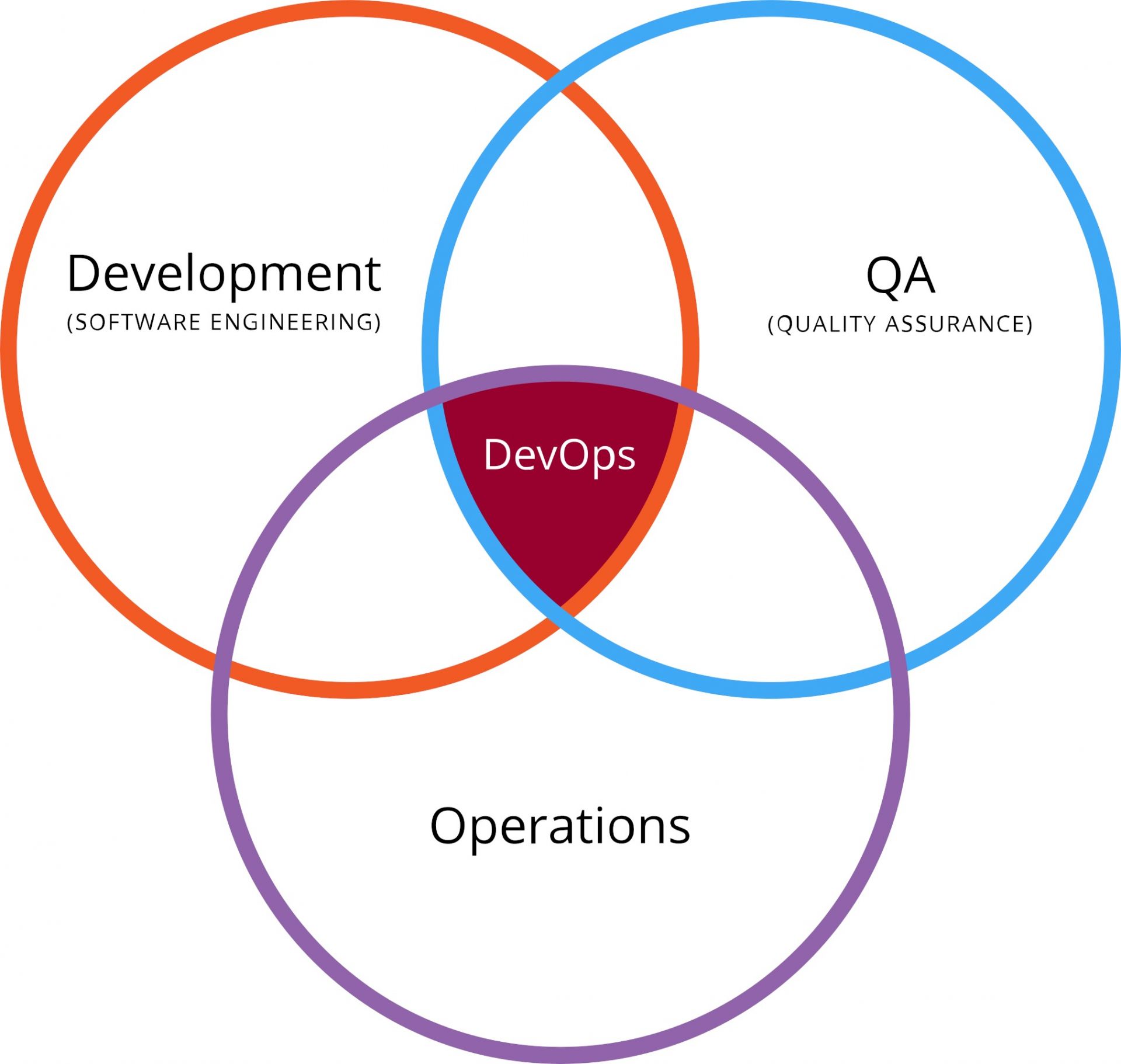 Irréconciliables, les Devs et les Ops ne le sont qu'en apparence. Car les Dév ne jettent pas toujours leur code en production en priant pour qu'il marche et sans se soucier des conséquences. Et les Ops ne sont pas systématiquement opposés aux changements, pourvu que ces derniers n'entrainent pas d'incidents ou d'instabilité. Devs et Ops se retrouvent et se réconcilient sur le terrain de la qualité.
Irréconciliables, les Devs et les Ops ne le sont qu'en apparence. Car les Dév ne jettent pas toujours leur code en production en priant pour qu'il marche et sans se soucier des conséquences. Et les Ops ne sont pas systématiquement opposés aux changements, pourvu que ces derniers n'entrainent pas d'incidents ou d'instabilité. Devs et Ops se retrouvent et se réconcilient sur le terrain de la qualité.
Facile à dire mais pas facile à faire. La qualité a souvent été sacrifiée sur l'autel du respect du coût et des délais, quand elle n'était pas assassinée avant par l'incompétence ou les mauvaises pratiques de développement. Avant de se faire définitivement enterrée par une infrastructure inadéquate et deux ou trois erreurs de déploiement en production.
La solution existe pourtant et est connue depuis longtemps. Il faut auditer et surtout tester le code intensivement. Mais cela coûte cher et prend du temps, me direz-vous. A moins que vous n'automatisiez tout cela. Du développement au déploiement en production. Grâce à des outils. Alors si la culture de la coopération entre Devs et Ops constitue les fondations du DevOps, l'automatisation et la mesure en sont assurément les réacteurs.
La démarche DevOps, qui vise à réconcilier ces deux grands métiers de l'Informatique, en étendant les principes des méthodes agiles aux équipes de production, ne peut donc vivre sans un "pipeline" automatisé (et vice-versa). Nous allons donc nous intéresser ici à la façon de construire un pipeline DevOps.
Le pipeline (ou chaîne d'outils)
La première erreur du débutant est de confondre méthode agile et absence de méthode. C'est d'autant plus vrai avec nous français. Il ne faut pas confondre le "Quick and dirty" et l'agilité. Les deux approches ont en commun la rapidité, mais la première vous donnera un résultat approximatif, tandis que la seconde vous garantira la qualité en sus. Et pour éviter les travers, rien ne vaut un bon rail, qui vous guide du développement jusqu'à la production. Et ce rail, c'est le pipeline.
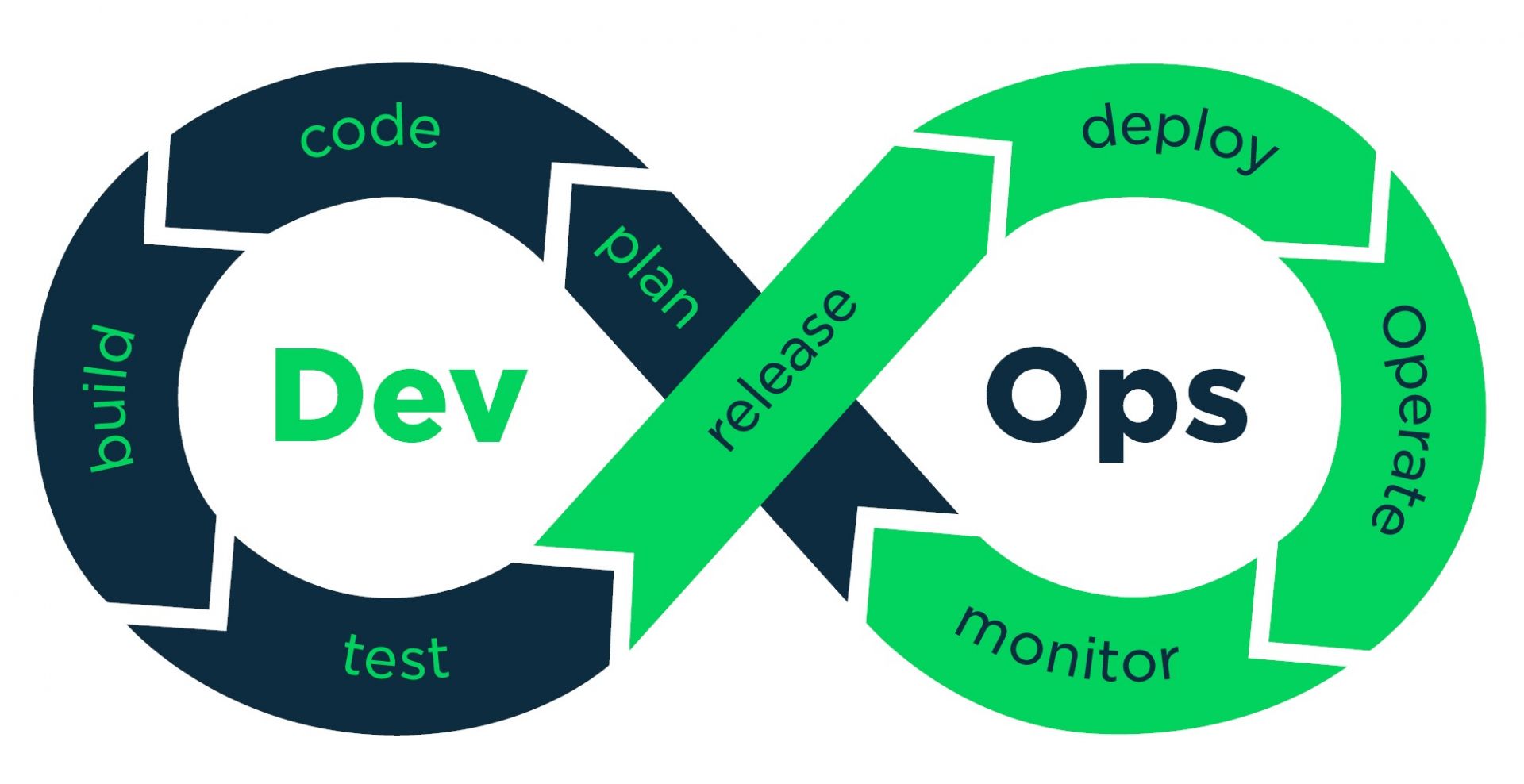
Sur le papier, rien ne ressemble plus à un pipeline DevOps qu'un pipeline de développement logiciel classique. Il faut planifier, coder, compiler et packager son logiciel, le tester, le livrer en recette avant de le déployer en production. Une fois en production, il faut le maintenir en condition opérationnelle et donc le superviser en permanence. La seule différence, c'est que ce cycle se déroule sur une période courte et fixe, et qu'on peut réitérer ainsi à l'infini (et au-delà). D'où le ruban de Moebius en symbole de ce cycle.
Afin d'automatiser ce cycle, il est nécessaire de mettre en oeuvre et d'intégrer de nombreux outils. Cela est souvent synonyme de coûts de licences et de maintenance éditeur et de coûts de mise en oeuvre et de maintien en conditions opérationnelles. La bonne nouvelle, c'est qu'il existe sur le marché de nombreux outils OpenSource, avec des versions de base gratuites et des versions payantes pour ceux qui ont besoin de fonctions avancées. La mauvaise nouvelle, c'est que l'OpenSource bascule rapidement d'un fork à l'autre ou d'un outil à un autre. Il faut donc être capable de suivre.
Vu de manière linéaire, le pipeline, avec ses outils, c'est plutôt çà :
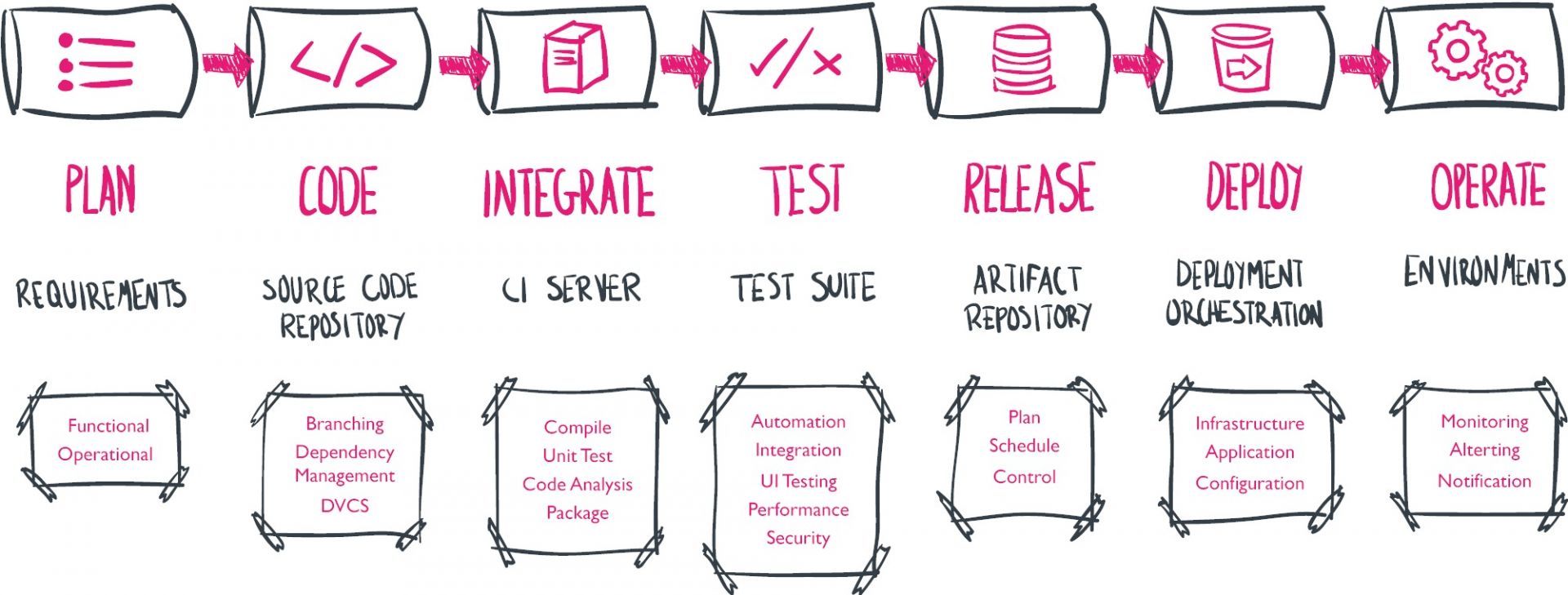
Je vais donc vous présenter ici les principaux outils qui constituent le pipeline DevOps. Évidemment, cet état de l'art ne vaut que les quelques mois qui viennent, mais c'est toujours intéressant d'avoir une photo du moment (Février 2018). J'aborde les outils du monde Open, car ils constituent la majorité des implémentations. Mais je n'oublie pas que le monde DevOps est aussi valable pour les développeurs Cobol et le mainframe. Cela intéresse certainement moins de personnes et je traiterai donc de ce sujet dans un article séparé.
Pour accéder directement aux différents thèmes ou phases du pipeline, cliquez simplement sur les liens ci-dessous.
| Plan → Code → Build → Test → Release → Deploy → Operate →Monitor |
Plan
 Pour commencer, il vous faut un bon outil de planification, adapté aux ou conçu pour les méthodes agiles. Histoire de pouvoir planifier ses sprints et ses « releases », suivre l'avancée de son backlog, et faciliter la collaboration entre équipes avec des tableau Kanban électroniques. Il existe deux grandes catégories sur le marché. Les outils orientés planification, relativement complexes et pas toujours faciles à maîtriser, et les outils orientés tâches, plus simples de prise en main. Ces derniers peuvent suffire si vous vous lancez dans l'Agile. Vous aurez ensuite la possibilité d'évoluer vers des outils plus complexes. Citons parmi les principaux outils :
Pour commencer, il vous faut un bon outil de planification, adapté aux ou conçu pour les méthodes agiles. Histoire de pouvoir planifier ses sprints et ses « releases », suivre l'avancée de son backlog, et faciliter la collaboration entre équipes avec des tableau Kanban électroniques. Il existe deux grandes catégories sur le marché. Les outils orientés planification, relativement complexes et pas toujours faciles à maîtriser, et les outils orientés tâches, plus simples de prise en main. Ces derniers peuvent suffire si vous vous lancez dans l'Agile. Vous aurez ensuite la possibilité d'évoluer vers des outils plus complexes. Citons parmi les principaux outils :
-
Micro Focus (anciennement HPE) Agile Manager
-
Microsoft Team Fondation Server (TFS)
-
CA Agile Central (anciennement Rally)
-
Atlassian Jira Software (connu pour son outil de bug tracking)
-
Trello (de la société éponyme, spin off de Fog Creek Software) : orienté tâches ;
NB : Trello a été racheté en 2017 par Atlassian mais garde pour le moment son identité. -
CollabNet ScrumWorks
-
Thoughtworks Mingle
-
Wrike (de la société éponyme)
-
Asana ((de la société éponyme) : orienté tâches
NB : un outil de gestion de projet offre notamment un découpage (WBS) et une gestion des tâches, un suivi des temps, du budget, un planning, une gestion des ressources, des outils collaboratifs (messagerie instantanée, wiki, espaces de partages etc.), des fonctions de rapports, de suivi des anomalies, etc.
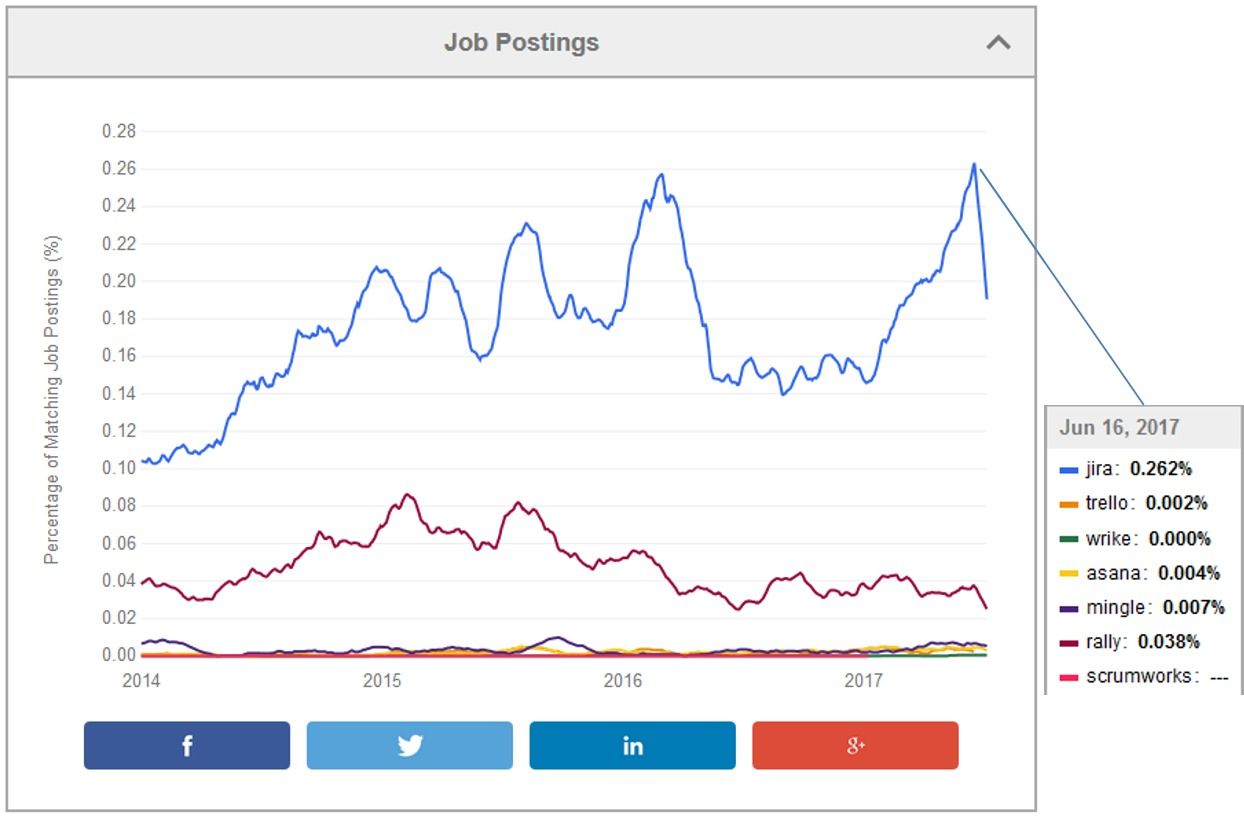
Si on regarde la fréquence des offres d'emplois sur la plate-forme Indeed, on voit que Jira arrive très loin devant ses concurrents. Il faut dire qu'Atlassian bénéficie d'une base installée importante et que son produit phare s'impose donc comme le produit leader. Mais Wrike ou Trello valent aussi l'essai...
Code
 Toute société de développement qui se respecte dispose d'un outil de gestion du code source. Cet outil permet non seulement de conserver le code source, mais de gérer aussi les différentes versions et branches du code. Sur le marché, il existe 2 générations d'outils. La première est centralisée : le code est stocké à un endroit et éventuellement répliqué, mais seule la base centrale fait foi. Ce qui peut être contraignant pour des équipes réparties géographiquement (qui n'a pas des équipes de développement en Inde ?). La seconde génération est décentralisée. Les répliques se synchronisent automatiquement. Parmi les premières générations d'outils, centralisés, on trouve :
Toute société de développement qui se respecte dispose d'un outil de gestion du code source. Cet outil permet non seulement de conserver le code source, mais de gérer aussi les différentes versions et branches du code. Sur le marché, il existe 2 générations d'outils. La première est centralisée : le code est stocké à un endroit et éventuellement répliqué, mais seule la base centrale fait foi. Ce qui peut être contraignant pour des équipes réparties géographiquement (qui n'a pas des équipes de développement en Inde ?). La seconde génération est décentralisée. Les répliques se synchronisent automatiquement. Parmi les premières générations d'outils, centralisés, on trouve :
-
Apache Subversion (SVN)
-
IBM Rational Clearcase
-
Microsoft Team Fondation Version Control (intégré à TFS)
Parmi les secondes générations d'outils, décentralisés, citons :
-
Git (l'outil) ou GitHub (le service) ; Outre le fait d'être décentralisé, Git gère plus facilement les différentes branches de codes et les fusions, surtout avec le produit Bitbucket d'Atalssian (qui peut utiliser Git ou Mercurial).
-
Mercurial Source Version Control (SVC)
-
Canonical Bazaar
-
Fossil Source Version Control
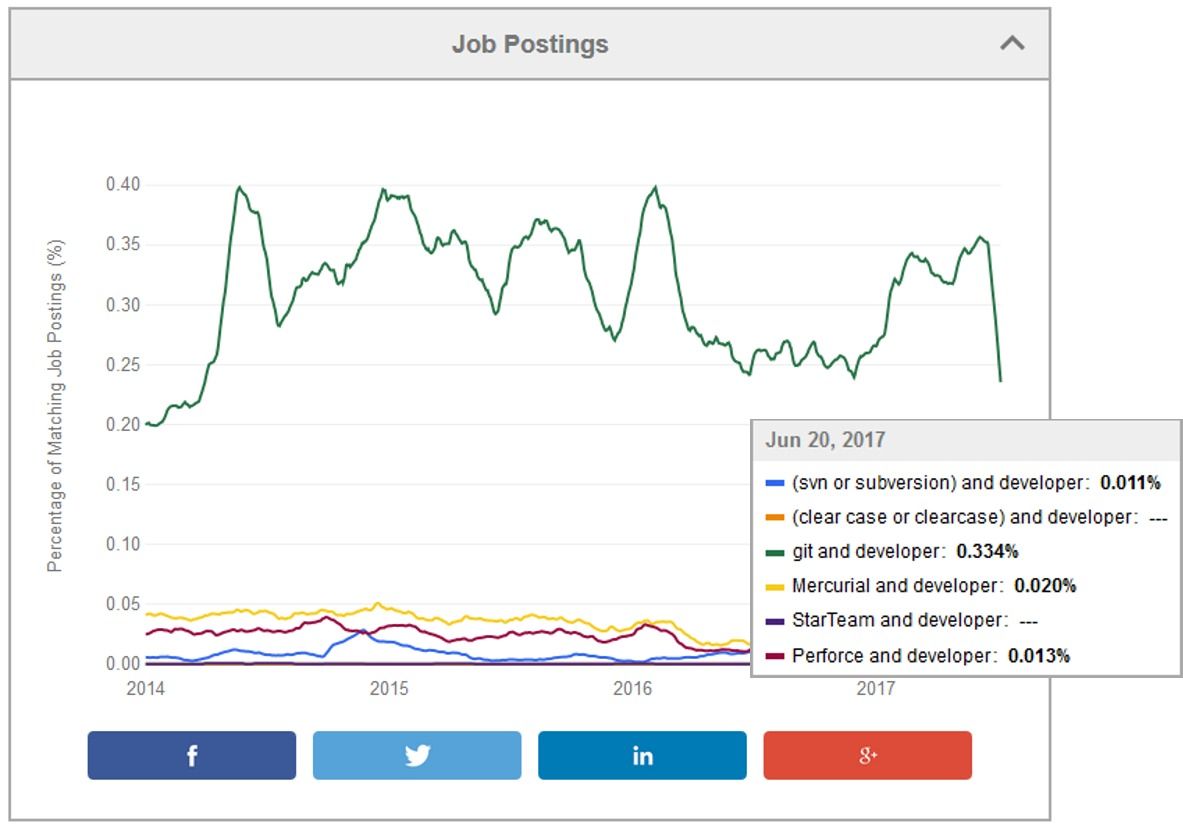
Git est de loin l'outil le plus utilisé, comme on peut le voir sur Indeed.
Build & Package - Integrate
 On appelle aussi la phase de "Build" phase "d'intégration" car c'est à ce moment que le code de chaque développeur est assemblé pour donner le produit final. Techniquement, on compile, on réalise l'édition de lien et on package le tout pour que l'exécutable puisse être déployé dans les différents environnements, y compris de production.
On appelle aussi la phase de "Build" phase "d'intégration" car c'est à ce moment que le code de chaque développeur est assemblé pour donner le produit final. Techniquement, on compile, on réalise l'édition de lien et on package le tout pour que l'exécutable puisse être déployé dans les différents environnements, y compris de production.
Pour intégrer, il faut un serveur d'intégration. Et en méthode agile, on appelle cela un serveur d'intégration continue (Continuous Integration Server ou CIS en anglais). Il y a quelques années encore, la bataille faisait rage entre Hudson et son clone Jenkins. Aujourd'hui, la question ne se pose plus : la plupart des utilisateurs ont basculé sur Jenkins. Il existe bien sûr quelques alternatives, mais c'est plus cher et moins bien :
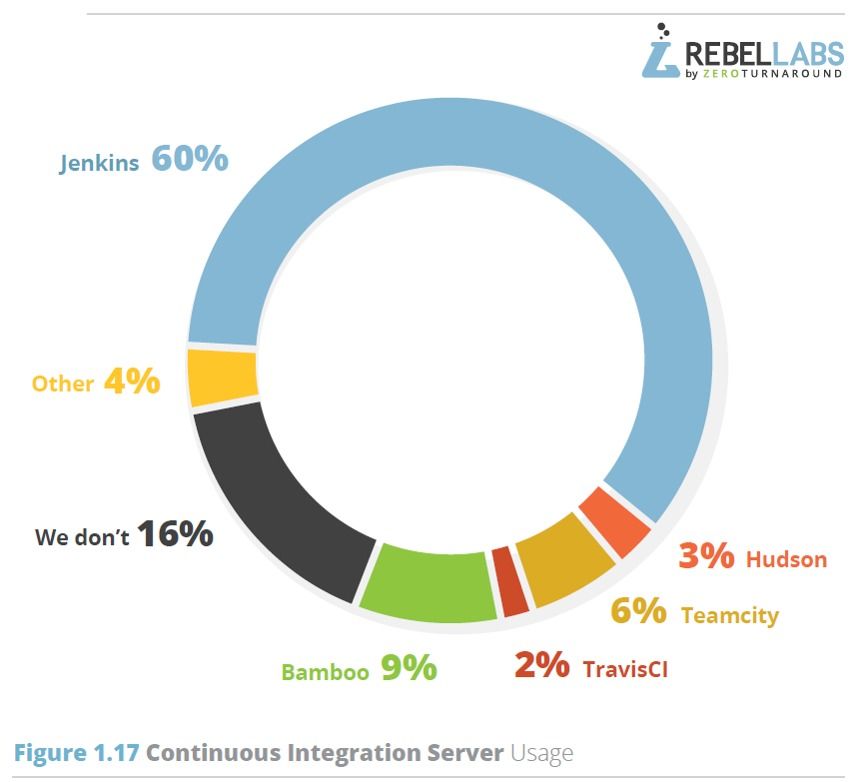
TFS a l'avantage d'être bien intégré à l'environnement de développement phare de Microsoft, Visual Studio, mais les compétences sur cette plate-forme sont assez "rares" sur le marché. Si l'on regarde les résultats de l'enquête de RebelsLabs, Jenkins domine le marché avec 60 % des parts, loin devant Bamboo ou Teamcity
Bien sûr, un logiciel comme Jenkins ne pourra pas répondre à tous les besoins d'une intégration continue. Rappelons que pour faire un bon pipeline, il vous faut être en mesure de compiler et de livrer tous les jours quelque chose de qualité. Cela suppose des retours rapides aux développeurs sur les modifications qu'ils ont apportés. Il vous faut donc intégrer quelques logiciels complémentaires, en sus des outils traditionnels de compilation, pour mesurer automatiquement la qualimétrie du code, détecter les failles (évidentes) de sécurité, ou encore tester de manière unitaire les différents modules.
Il faut donc veiller à ce que votre serveur d'intégration continue possède bien les bons plugins (ou interfaces) avec ses outils.
Dans la catégorie compilation
En sus de ces outils, si vous utilisez un système de container comme Docker en production, il vous faudra aussi bien sûr intégrer Docker dans votre processus de build. Coup de pot, graddle intègre justement un plugin pour Docker.
Dans la catégorie Analyse de code
-
SonarQube, capable d'analyser plus de 20 langages différents, du Java au Cobol en passant par le C et C++. Il y a aussi CAST bien sûr, mais ce dernier est incapable de sortir une analyse journalière du code. Autant dire que la philosophie de CAST ne colle pas du tout avec celle du DevOps et de l'Agile.
-
Checkmarx, outil permettant de scanner le code à la recherche de failles de sécurité. Cirons aussi dans les scanners sécurité Micro Fous Fortify et CA Veracode (module Developer Sandbox).
Dans la catégorie Tests unitaires, citons
-
JUnit, le plus populaire des xUnit, pour tester le code Java.
-
Jmockit et PowerMock, pour tester son code sans dépendre de connexion vers les composants tiers comme les bases de données par exemple.
-
SoapUI, qui permet de tester les API comme les Web Services. Il permet aussi bien d'autres choses au passage.
Enfin, dans la catégorie "référentiels de composants", qui vous permettent de stocker et gérer le résultat de votre compilation/édition de lien, citons :
-
Sonatype Nexus, qui peut résoudre des dépendances externes en "cachant" pour vous les composants externes à votre projet. Il fait aussi office de proxy Internet permettant de récupérer les composants disponibles sur Internet.
-
Apache Archiva
-
JFrog Artifactory
Chaque outil dispose généralement d'une barrière de qualité (quality gate). Si votre score Qualité/Sécurité est trop faible, votre code est recalé et ne sera pas déployé. En revanche, si votre score est suffisamment élevé, alors votre code sera compilé et poussé vers la prochaine étape. Généralement celle des "Tests fonctionnels".
Test
 L'étape la plus importante dans la vie d'un logiciel est la phase de tests. Et des tests, il y en a. A croire qu'on ne teste jamais assez...ce qui n'est pas faux. La qualité du code est directement corrélée avec le nombre de tests.
L'étape la plus importante dans la vie d'un logiciel est la phase de tests. Et des tests, il y en a. A croire qu'on ne teste jamais assez...ce qui n'est pas faux. La qualité du code est directement corrélée avec le nombre de tests.
-
Les tests d'intégration système (ou System Integration Tests) qui permettent de tester l'application intégrée dans son écosystème (référentiels, applications amont et aval, etc.)
-
Les Tests fonctionnels (ou Functionnal Integration Tests), qui permettent de valider les fonctions de l'application. Ils incluent les tests bilatéraux (d'application à application) et les tests de bout en bout (déroulant l'ensemble du processus).
-
Les tests de non-régression (TNR ou Regression Tests) : ce sont des tests fonctionnels ayant déjà été exécutés lors de la précédente recette et qui permettent de vérifier que les évolutions introduites dans la nouvelle version ne font pas dysfonctionner les précédentes fonctions livrées.
-
Les tests d'acceptation utilisateurs (UAT). Ils permettent de vérifier la conformité du produit final grâce à des scénarios réels (et avec des utilisateurs réels). C'est une sorte de phase de béta test, juste avant la publication du produit.
-
Les tests de performances (ou Capacity Tests) : ce sont les plus compliqués à réaliser. Il faut les réaliser quand l'application est assez stable pour passer sur le banc d'essai, mais sans qu'il soit trop tard pour changer quoi que ce soit.
-
Les tests de sécurité. De la même manière, on peut aussi tester la sécurité de l'application en même temps que ses performances.
 L'idée générale est d'automatiser un maximum de tests. Les tests unitaires sont généralement pris en charge lors de l'intégration. Les TNR sont de bons candidats, car ces tests ont déjà été exécutés au moins une fois. Les tests de performances et de sécurité aussi. Les smoke tests, ou sanity checks, ou encore tests de fumée, qui permettent généralement de valider la bonne livraison d'une version dans son environnement cible, sont aussi d'excellents candidats. En terme d'outils, on trouvera des choses très simples comme des choses très complexes.
L'idée générale est d'automatiser un maximum de tests. Les tests unitaires sont généralement pris en charge lors de l'intégration. Les TNR sont de bons candidats, car ces tests ont déjà été exécutés au moins une fois. Les tests de performances et de sécurité aussi. Les smoke tests, ou sanity checks, ou encore tests de fumée, qui permettent généralement de valider la bonne livraison d'une version dans son environnement cible, sont aussi d'excellents candidats. En terme d'outils, on trouvera des choses très simples comme des choses très complexes.
Dans la catégorie "Tests fonctionnels"
-
Selenium, pour tester toutes les applications avec une interface utilisateur basée sur un navigateur Web. Comme Selenium demande des compétences techniques importantes, il vaut mieux utiliser un outil compagnon, comme cucumber, pour s'aider dans la constitution des tests. Il a l'avantage d'être gratuit et bien intégré à Jenkins.
-
Micro Focus (Ex HPE) Unified Functionnel Testing (UFT). Le leader incontesté du marché. Il a aussi l'avantage d'être couplé à ALM (ex Quality Center), qui gère entre autre les cas de tests et les anomalies de recette. Il est capable de tester les applications Web, mais aussi les applications Client/Serveur et les applications sous Citrix. Il ne demande pas non plus de compétences en programmation Java. Ce qui constitue des plus non négligeables par rapport à Sélénium. Il existe un plugin Jenkins pour UFT mais sa mise en oeuvre vous demandera un peu plus d'huile de coude.
-
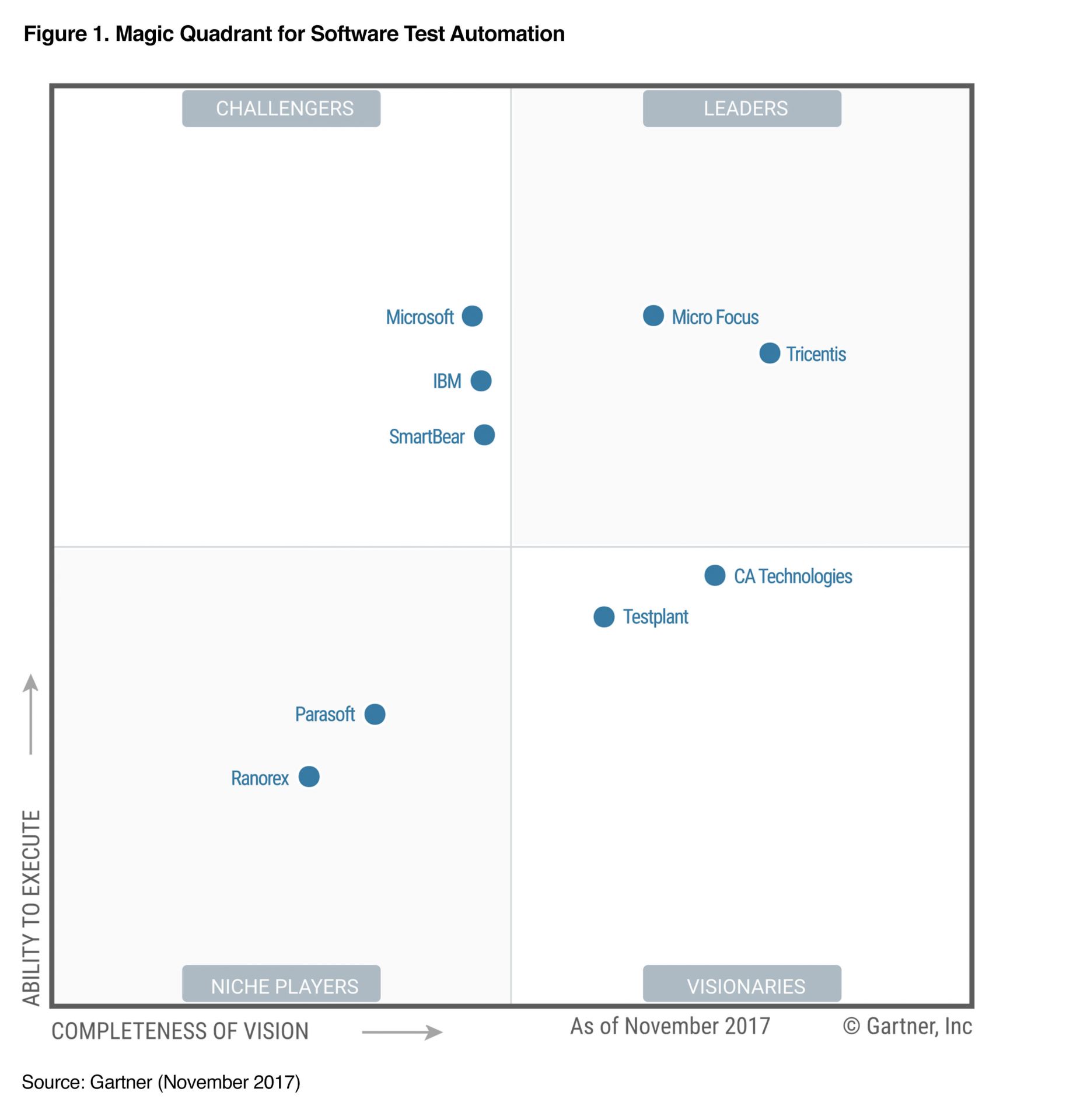
Tricentis Tosca, son challenger (voir figure ci-dessous).
-
Smartbear TestComplete
-
IBM Rational Test Workbench. Il faut mieux avoir la suite Rational et un bon Mainframe pour ce genre d'outils.
Dans la catégorie "Tests de performances"
-
Micro Focus (Ex HPE) LoadRunner. Le leader incontesté du marché.
-
Apache JMeter, une alternative OpenSoure
La figure suivante est issu du rapport de novembre 2017 du Gartner sur l'automatisation des tests logiciels. Comme le Gartner ne prend pas en compte les outils OpenSource (le CA est un critère important du Magic Quadrant), vous n'y trouverez évidemment pas Sélénium.
Dans la catégorie Sécurité, nous retrouvons les mêmes acteurs, tels que Checkmarx, CA Veracode et Micro Focus Fortify. Je ne reviendrai donc pas dessus. Vous pouvez les retrouver dans la section "Intégration continue".
Tous ces outils ont un point commun, ils nécessitent des données pour réaliser leurs tests. Ils peuvent donc générer leur propres données (données synthétiques) ou utiliser des données pré-existantes, chargées par un autre outil. C'est ce qu'on appelle le Test Data Management, dont les leader sont IBM InfoSphere Optim, Compuware FileAID et Informatica TDM. Mais ces outils sont hors champs de cet article. Notez simplement que vous aurez besoin d'y faire appel.
Release
 Quand votre logiciel a passé les tests d'intégration, il peut généralement être mis à disposition des testeurs. Tant qu'il était en phase de développement, on ne parlait que de build. Dès qu'il est jugé suffisamment stable pour être mis en recette, on parle de "release" (le développeur autorise la sortie de son produit en quelque sorte). Évidemment, avant qu'un produit ne soit mis en production, un certain nombre de versions applicatives va se succéder en recette pour aboutir à une release. On taggue alors le code, une fois le niveau de maturité atteint, avec un n° de version.
Quand votre logiciel a passé les tests d'intégration, il peut généralement être mis à disposition des testeurs. Tant qu'il était en phase de développement, on ne parlait que de build. Dès qu'il est jugé suffisamment stable pour être mis en recette, on parle de "release" (le développeur autorise la sortie de son produit en quelque sorte). Évidemment, avant qu'un produit ne soit mis en production, un certain nombre de versions applicatives va se succéder en recette pour aboutir à une release. On taggue alors le code, une fois le niveau de maturité atteint, avec un n° de version.
Pour gérer ces différentes releases, il faut un outil de gestion des référentiels de composants. Ces outils ont pour vocation de stocker mais aussi d'organiser et distribuer les logiciels et leurs bibliothèques, avec la bonne version. J'ai déjà évoqué ces produits dans la phase de build, les principaux sont Nexus, Archiva et Artifactory, mais il en existe bien d'autres naturellement.
Deploy
 Une fois votre produit testé et mis à disposition dans le référentiel de composants, il faut le déployer dans les différents environnements d'intégration, de recette, de pré-production et de production, sans parler de ceux de maintenance et de formation. Tout cela de manière automatisée si possible. Dans le plus simple des cas, il vous faut un outil qui sache déployer votre produit sur les différents environnements existants. Dans les cas les plus complexes, il faut aussi provisionner ces environnements, et ce de manière automatisée bien sûr.
Une fois votre produit testé et mis à disposition dans le référentiel de composants, il faut le déployer dans les différents environnements d'intégration, de recette, de pré-production et de production, sans parler de ceux de maintenance et de formation. Tout cela de manière automatisée si possible. Dans le plus simple des cas, il vous faut un outil qui sache déployer votre produit sur les différents environnements existants. Dans les cas les plus complexes, il faut aussi provisionner ces environnements, et ce de manière automatisée bien sûr.
Dans la catégorie Déploiement, on trouvera donc des outils comme :
-
Jenkins. En sus d'assurer l'intégration continue, Jenkins est aussi capable de faire du déploiement continu. Mais cela reste assez rudimentaire. Pour des outils un peu plus évolués, il faut s'orienter vers des outils payants, qui offrent de nombreux plugins et interfaces.
-
Electric Cloud ElectricFlow
-
XebiaLabs XL-Deploy. Un des leaders en France.
-
CA Technologies Automic Release Automation (rachat). Notons qu'Automic a réalisé un belle cartographie des différents outils, qui vaut le coup d'oeil.
-
Octopus Deploy
-
IBM UrbanCode Deploy (rachat)
Dans la catégorie Provisionning, on trouvera donc des outils (tous ont une version OpenSource) permettant de décrire son infrastructure par de simples lignes de "code" (Infrastructure as a code) comme :
-
Chef. Notons que Chef dispose aussi d'un outil de déploiement, ChefAutomate...Chef s'appuie sur Git et Ruby, il vaut donc mieux que vous ayez ces 2 produits en magasins. Chef est intéressant pour tous ceux qui cherche une solution mature fonctionnant dans un environnement hétérogène.
-
Puppet. Comme son concurrent, Puppet dispose aussi d'un outil de déploiement, Puppet Pipelines...Puppet est aussi un bon choix d'outil stable et mature, fonctionnant dans un environnement hétérogène et maitrisant bien le DevOps.
-
Ansible. Sans doute le plus simple des 3 produits, et fonctionnant sans agent, ce qui fait son succès, mais aussi le plus limité de ce fait.
-
Mentionnons aussi SaltStack et Fabric, des outils assez frustres de déploiement mais qui ont l'avantage d'être simples et gratuits.
Vous pouvez naturellement coupler Puppet ou Chef avec XL-Deploy par exemple, de manière à assurer la cohérence de votre déploiement avec celui du provisionning et de la gestion de la configuration de l'infrastructure.
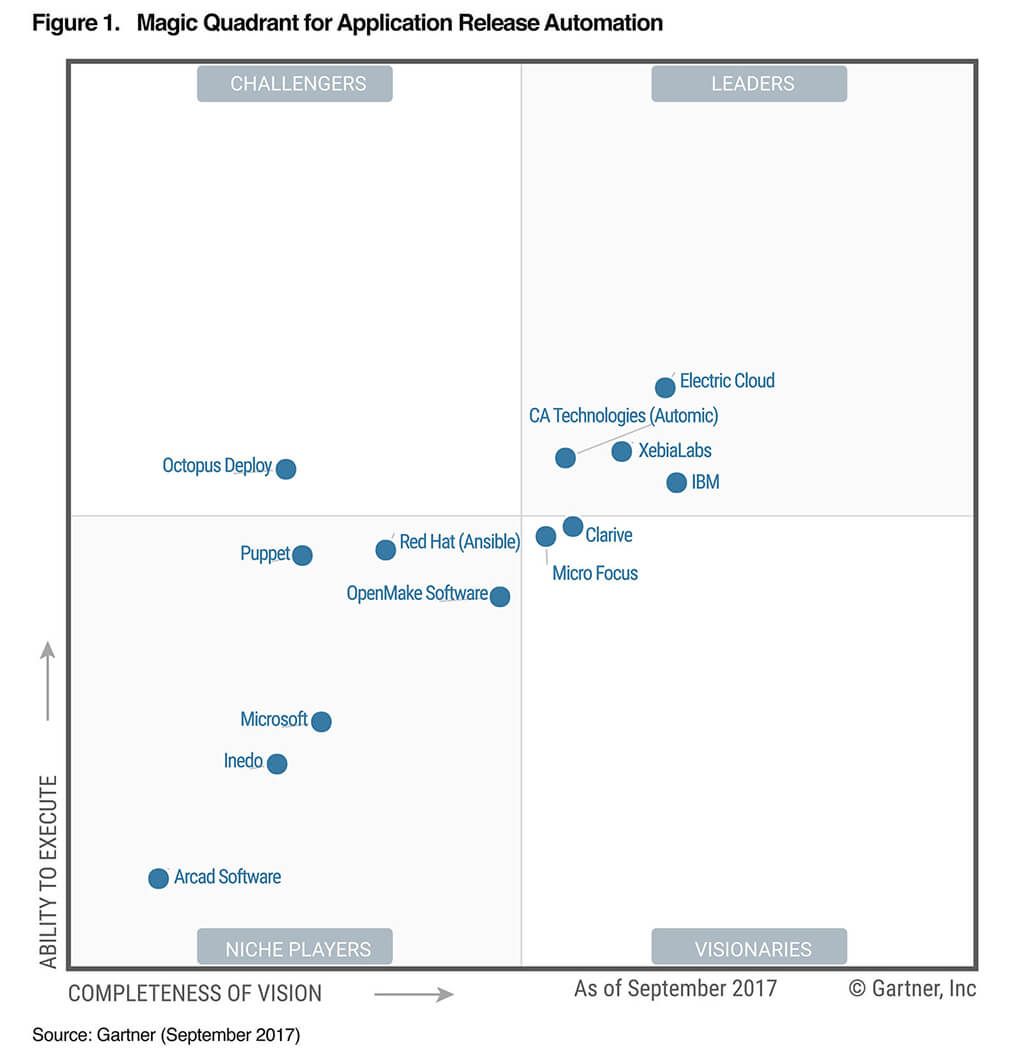
La figure suivante est issu du rapport de septembre 2017 du Gartner sur l'automatisation des deploiements des applications. Comme le Gartner ne prend pas en compte les outils OpenSource (le CA est un critère important du Magic Quadrant), vous n'y trouverez évidemment pas Jenkins, ni Chef, mais Puppet et Ansible y figurent en bonne place.
Maîtrise du processus de bout en bout
Nous venons de passer en revue les différentes produits de notre pipeline, et l'on serait tenter de s'arrêter ici. Nous avons en effet un outil pour planifier, gérer notre code, construire et packager notre produit, le tester, gérer les différentes releases et un outil pour les déployer. Mais n'oublions pas que la base de l'Agile, c'est Culture, Automation, Measurement and Sharing. Culture et Partage ne sont pas vraiment les sujets de cet article mais Automatisation et Mesure le sont totalement.
 Pas étonnant donc que l'on trouve avec l'émergence du DevOps des outils permettant de suivre son processus de release de bout en bout, du build au déploiement en production, et de pointer les dysfonctionnements, là où ça fait mal et ce qu'il faut améliorer pour disposer d'un pipeline le plus fluide possible. On n'améliore que ce que l'on mesure après tout...
Pas étonnant donc que l'on trouve avec l'émergence du DevOps des outils permettant de suivre son processus de release de bout en bout, du build au déploiement en production, et de pointer les dysfonctionnements, là où ça fait mal et ce qu'il faut améliorer pour disposer d'un pipeline le plus fluide possible. On n'améliore que ce que l'on mesure après tout...
-
L'outil le plus connu est certainement XebiaLabs XL-Release. Il permet de modéliser puis de superviser les livraisons logicielles, il orchestre les tâches au sein des équipes IT, du développement à la mise en production en passant par la recette. XL Release fournit des tableaux de bord de bout-en-bout, des outils d’analyse et de rapports approfondis et est facile d’utilisation. Il vous donne ainsi une chance de réduire les délais de livraison et d'améliorer les processus de livraison. L'outil dispose de nombreux plugins luis permettant de se brancher au pipeline DevOps, de l’intégration continue au provisionnement et au déploiement continu.
-
IBM UrbanCode Release
-
CA Technologies Automic Release Automation
J'aborde le sujet de l'orchestration des processus DevOps en dernier, mais ce n'est pas forcément le dernier outil à mettre en oeuvre. Si vous souhaitez en effet savoir par où commencer et où porter vos efforts, peut-être faut-il commencer par cette étape. Cela vous permettra de modéliser vos processus actuels avant de commencer à les améliorer.
Operate
 Nous abordons enfin pour terminer le sujet le plus vaste, celui des Ops. Il s'agit de maintenir en condition opérationnelle l'infrastructure et les applications qui tournent dessus. Un sujet vieux comme le monde. Je ne vais donc pas vous refaire le monde. Il est trop vaste. Mais s'il est un sujet qu'on ne peut éviter en parlant du DevOps, c'est bien celui des conteneurs (containers). Les conteneurs ont été inventés en 2004 par Sun (ce n'est donc pas une innovation récente comme certains ont tendance à l'affirmer un peu vite), mais ils connaissent depuis peu un énorme succès. Mais diantre pourquoi maintenant ?
Nous abordons enfin pour terminer le sujet le plus vaste, celui des Ops. Il s'agit de maintenir en condition opérationnelle l'infrastructure et les applications qui tournent dessus. Un sujet vieux comme le monde. Je ne vais donc pas vous refaire le monde. Il est trop vaste. Mais s'il est un sujet qu'on ne peut éviter en parlant du DevOps, c'est bien celui des conteneurs (containers). Les conteneurs ont été inventés en 2004 par Sun (ce n'est donc pas une innovation récente comme certains ont tendance à l'affirmer un peu vite), mais ils connaissent depuis peu un énorme succès. Mais diantre pourquoi maintenant ?
Un container, c'est une autre façon d'aborder la virtualisation. Ici, pas d'OS virtuel émulé, on fonctionne avec l'OS du système hôte. C'est plus simple et plus rapide. Mais du coup, tous les containers partagent le même OS et surtout les mêmes ressources. Impossible de dédier un processeur ou de la mémoire à un container donné, contrairement aux machines virtuelles.
De fait, un container est plus adapté qu'une machine virtuelle complète pour faire tourner les micro-services. Dédier une machine virtuelle complète pour y faire tourner un petit micro-services, cela fait un peu riche, vous en conviendrez. Pourquoi alors ne pas faire tourner plusieurs micro-services dans une même machine virtuelle ? Parce que l'on perdrait alors en agilité. Tout ce qui se trouver dans la machine virtuelle doit par définition partager la même pile logicielle (les mêmes versions de bases de données, de serveurs d'application, etc.). Or un micro-service évolue très vite et indépendamment des autres micro-services, selon la philosophie DevOps. D'où le retour en grâce des conteneurs.
Le conteneur facilite aussi grandement la vie des développeurs. Car le conteneur embarque toutes les dépendances applicatives. Le code, les éventuels runtime, les outils système, toutes les bibliothèques nécessaires et le paramétrage de l'application. Il suffit donc de construire son application dans son conteneur pour être capable de la déployer et de la faire tourner dans n'importe quel environnement, pourvu que celui-ci dispose d'un gestionnaire de conteneurs.
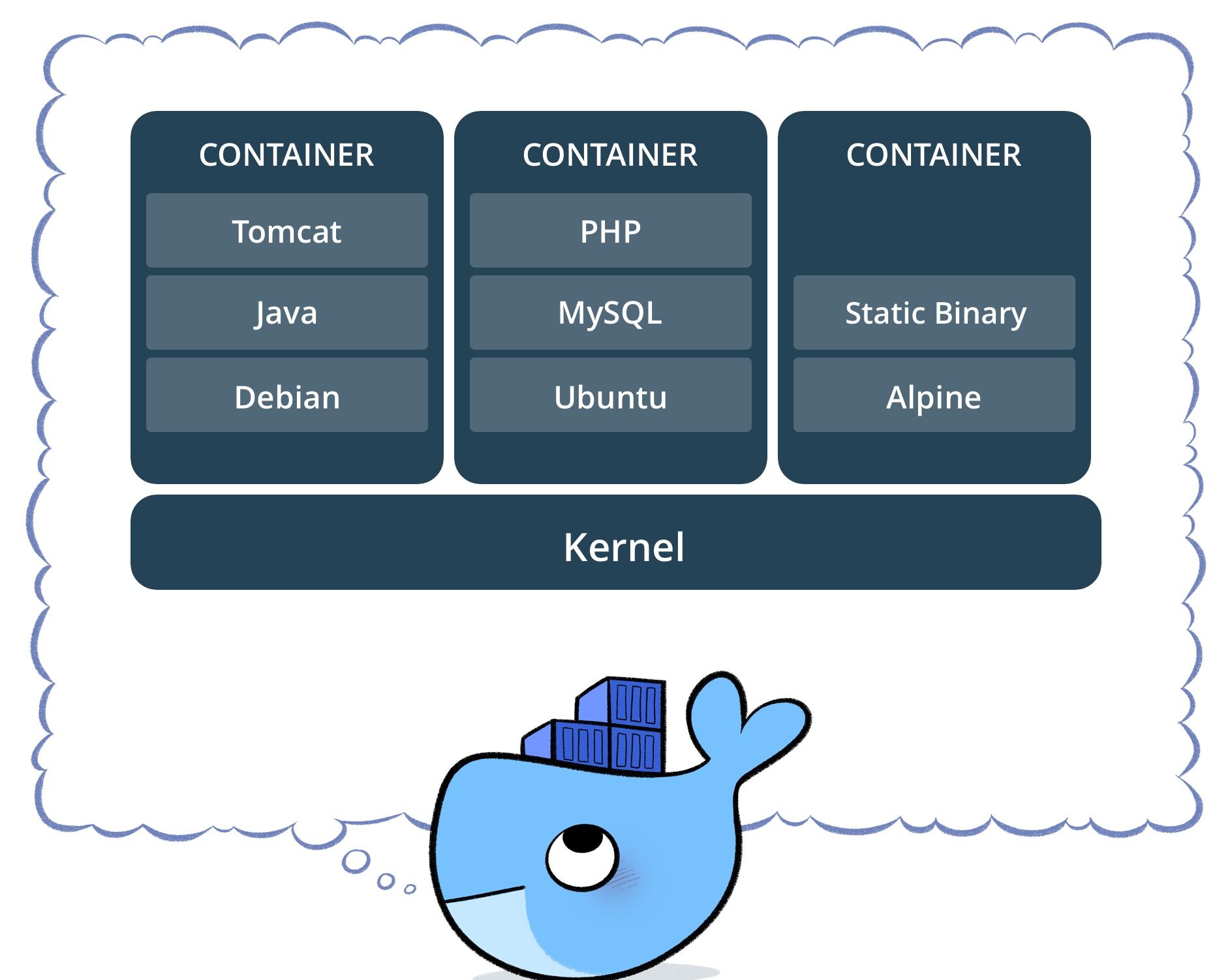
Parmi les fabricants de systèmes de conteneurs, nous trouvons :
-
Les conteneurs Linux LXC
-
Docker (qui n'est qu'une évolution des conteneurs LXC) et Docker Swarm pour la gestion des clusters, du routage, de la scalability.
-
Apache Mesos ; ce n'est pas un système de container mais plutôt un OS distribué supportant un système de container tel que Docker. Intéressant pour sa scalability.
-
Kubernetes : un système open source conçu à l'origine par Google et offert à la Cloud Native Computing Foundation. Il vise à fournir une « plate-forme permettant d'automatiser le déploiement, la montée en charge et la mise en œuvre de conteneurs d'applications sur des clusters de serveurs ». A noter que Docker offre maintenant le support de Kubertenes dans la Docker Community Edition pour les developpeurs sous Windows et macOS, et dans la Docker Enterprise Edition.
-
Les conteneurs Windows de chez Microsoft
-
et bien d'autres...
Bref, vous l'aurez compris, Docker, intégré dès le poste du développeur via Docker Compose, permet d'optimiser sa chaîne d'outil DevOps et facilite les déploiements en production. Encore faut-il que l'application soit conçue sur la base de micro-services bien sûr...
Monitor

La supervision est un sous-ensemble d'Operate. C'est sans doute un des principaux piliers des Ops avec la sauvegarde des données. Il n'y a donc rien de neuf dans le concept. Mais comme je l'ai dit précédemment, la mesure fait partie intégrante de la culture DevOps. Il est donc essentiel pour les devs comme pour les ops d'avoir des indicateurs sur le comportement de l'application. Et rien ne vaut une bonne supervision des performances de l'application.
Les principaux fournisseurs du marché sont :
A cela, on peut rajouter des outils permettant d'exploiter certaines données comme :
-
ELK : acronyme pour 3 projets open source, Elasticsearch, Logstash, et Kibana. Ce triptyque est très répandu et utilisé notamment pour la supervision de la sécurité, mais pas que.
-
Splunk : C'est une sorte de plate-forme d'Intelligence Opérationnelle (par opposition à la Business Intelligence) temps réel. On peut ainsi explorer, surveiller, analyser et visualiser les données machine via Splunk.
-
DataDog : DataDog est une excellente alternative à Splunk. La solution fonctionne aussi sur des environnements dans le Cloud.
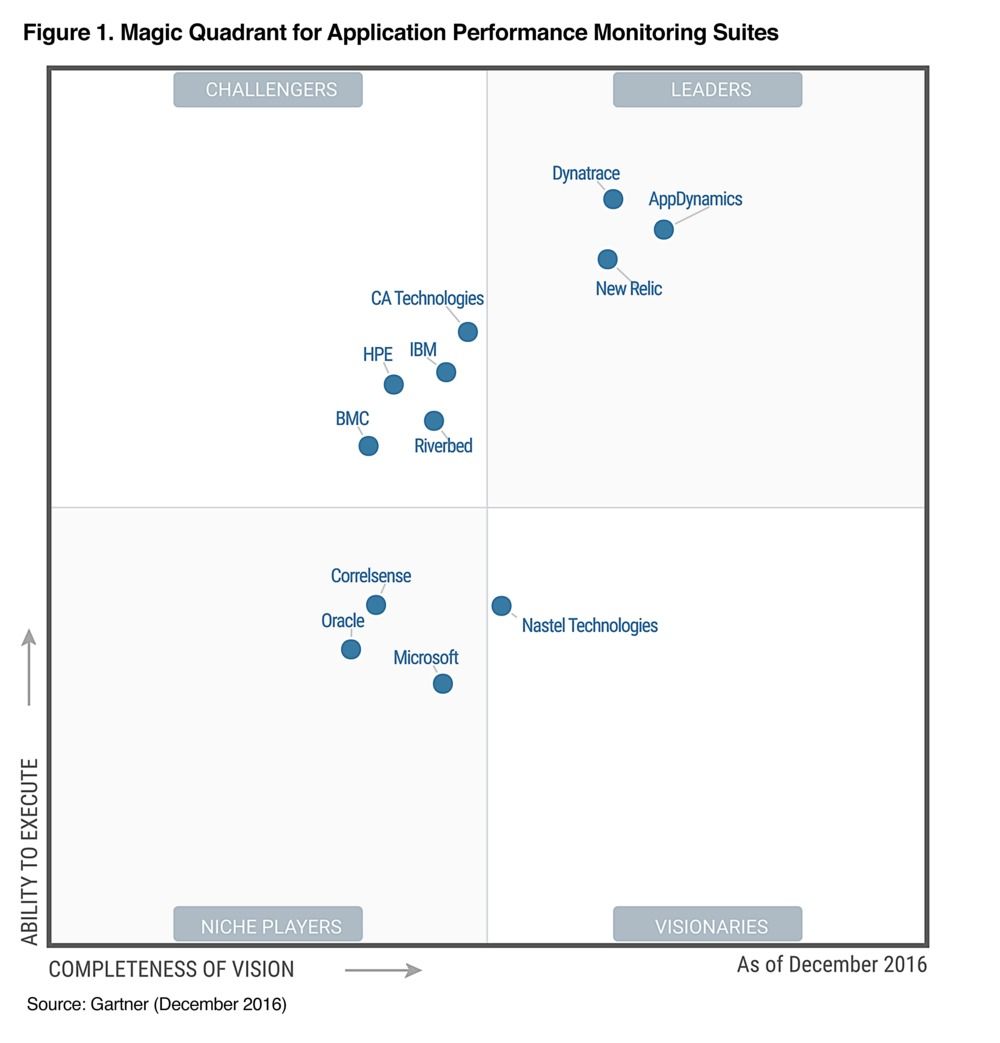
La figure suivante est issu du rapport de décembre 2016 du Gartner sur les outils de supervision des performances applicatives.
Conclusion
En résumé : pour construire votre pipeline, prenez un bon outil de planification agile comme Jira (si vous êtes familier avec les méthodes agiles), ou Wrike voire Trello pour démarrer, ajouter un bon gestionnaire de code source comme Git ou SVN (plus ancien), un bon serveur d'intégration continu comme Jenkins, assaisonnez d'outils complémentaires comme Maven ou Graddle, Junit SonaQube et Checkmarx pour les tests unitaires, la qualité et la sécurité. Mélangez ensuite avec Selenium ou UFT pour bien tester votre application et déployez le tout avec XL-Deploy. Il ne vous restera ensuite qu'à bien exploiter votre application et assurer sa disponibilité avec Docker Swarm et kubenetes et superviser ses performances avec Dynatrace et la sécurité avec Splunk ou ELK.
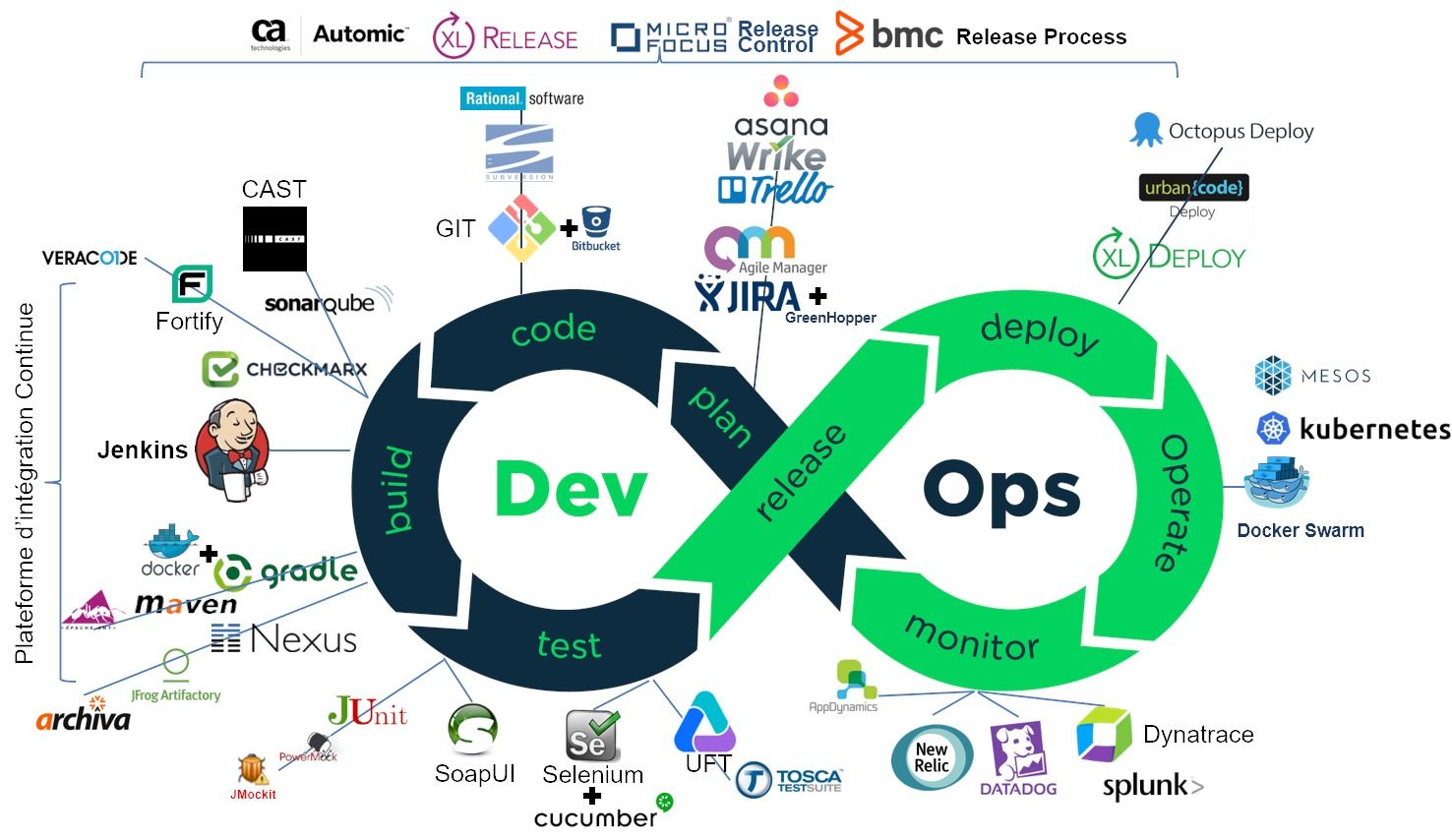
Bonne intégration et procédez par ordre, de l'intégration continue vers le déploiement continu : vous risqueriez sinon de finir comme sur la dernière image, ce serait dommage...
Windows Mobile est-il vraiment mort ?

Microsoft Lumia 950
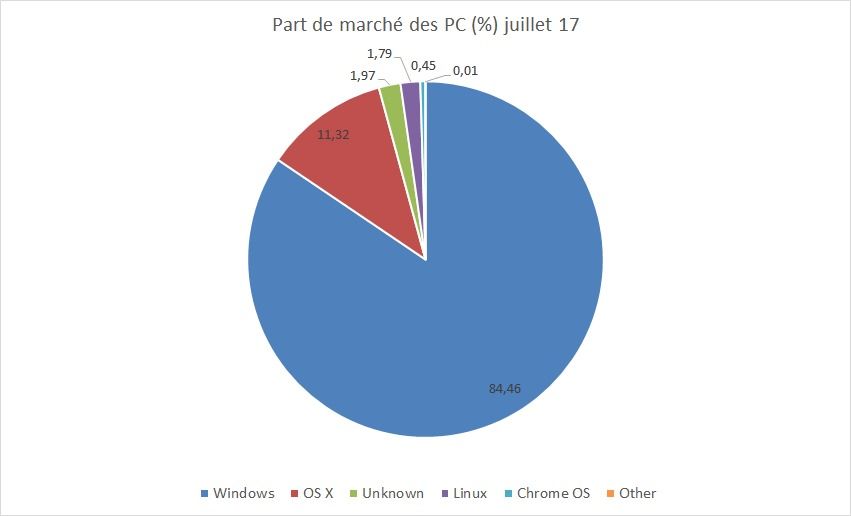
Si on examine les parts de marchés des OS mobiles, on s’aperçoit que Android se taille la part du lion avec 81,7% de part de marché, loin devant iOS avec 17,9% et Windows Mobile avec un ridicule 0,3%. D'aucuns diraient donc que Windows Mobile est mort et bientôt enterré. Surtout que Microsoft a fermé son activité Mobile rachetée à Nokia en 2014 et licencié les 9 650 salariés travaillant pour cette division, en deux vagues entre juillet 2015 et mai 2016, laissant ses partenaires poursuivre le combat. Mais le canard est-il déjà mort ? Pas si sûr...
La part de marché des smartphones
Si l'on en croit un récente étude du Gartner, Android se taille la part du lion avec 81,7% de parts de marché (en légère progression), loin devant iOS avec 17,9% (stable) et Windows Mobile avec 0,3% (en forte régression).
|
Operating System |
Unités vendues 4T16 (Milliers) |
Part de marché 4T16 (%) | Unités vendues 4T15 (Milliers) | Part de marché 4T15 (%) |
| Android | 352 670 | 81,7 | 325 394 | 80,7 |
| iOS |
77 039 |
17,9 |
71 526 |
17,7 |
| Windows |
1 092 |
0,3 |
4 395 |
1,1 |
| BlackBerry |
208 |
0,0 |
907 |
0,2 |
|
Other OS |
530 |
0,1 |
887 |
0,2 |
|
Total |
431 539 |
100,0 |
403 109 |
100,0 |
Source: Gartner (Février 2017)
Les fameux BlackBerry et leurs célèbres claviers ont quasiment disparus du radar avec une part de marché proche de 0 et 200 000 unités vendus seulement (tous pays confondus !). On peut donc légitimement se dire que Windows Mobile est en train de suivre le même chemin que les Blackberry. Sans même avoir connu d'heures de gloire, contrairement au constructeur canadien. La faute entre autres au catalogue d'applications qui peine toujours à se remplir face à celui d'Android et iOS, et à un OS qui est arrivé bien trop tard à maturité face à ses concurrents.
Ce qui nous conduirait à une sorte de duopole formé du couple Android – iOS, ce qui est toujours dommageable pour la concurrence et l’innovation. Quoique si l’on regarde de plus près, les constructeurs de smartphones sous Android (Samsung, et les chinois Huawei, Oppo et BBK en tête) se livrent une concurrence assez féroce.
| Constructeur |
Unités vendues 2016 (Milliers) |
Part de marché 2016 (%) |
Unités vendues 2015 (Milliers) |
Part de marché 2015 (%) |
| Samsung |
306 447 |
20,5 |
320 220 |
22,5 |
| Apple |
216 064 |
14,4 |
225 851 |
15,9 |
| Huawei |
132 825 |
8,9 |
104 095 |
7,3 |
| Oppo |
85 300 |
5,7 |
39 489 |
2.8 |
|
BBK Communication Equipment |
72 409 |
4,8 |
35 291 |
2.5 |
| Others |
682 314 |
45,6 |
698 955 |
49,1 |
| Total |
1 495 358 |
100,0 |
1 423 900 |
100,0 |
Source: Gartner (Février 2017)
A noter que le dernier trimestre 2016 a vu Apple repasser devant Samsung, une remontée sans doute liée à l’effet du Galaxy Note 7 et de ses batteries explosives. Mais cette lutte acharnée se joue sans le constructeur américain de Redmond. Microsoft a-t-il pour autant abandonné tout espoir de jouer un rôle dans le marché du smartphone ? Pas si sûr que cela, et voilà pourquoi.
Le smartphone est le terminal informatique de demain
En 2013, les internautes français passaient 1h45 par jour sur Internet en version desktop (ordinateur de bureau ou ordinateur portable). Cette durée est restée stable (1h44 en 2016) et les projections sont donc sans surprises (1h41 en 2018).
Et pendant ce temps, le temps passé sur l’Internet mobile explose. En 2013, eMarketer estimait que les internautes passaient 42 minutes par jour sur leur mobile pour consulter Internet, et 1h41 en 2016. L’an prochain, le temps passé sur l’Internet mobile aura dépassé le desktop. En 2018, on passera sans doute plus de 2 heures par jour sur notre mobile à naviguer sur Internet.
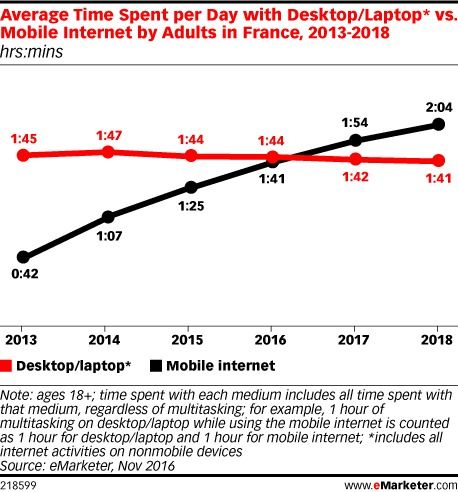
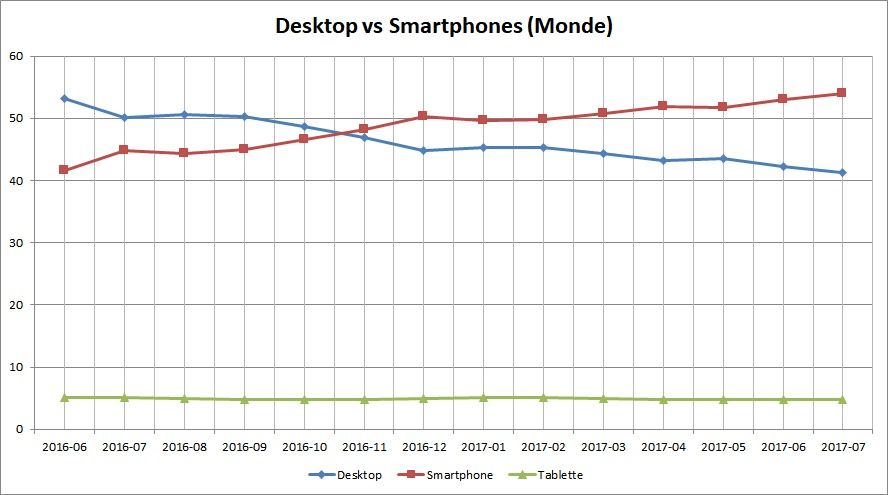
Des chiffres corroborés par les statistiques mondiales de StatCounter : ces dernières comptent simplement le nombre d’équipements et les classent par catégorie (Desktop, Tablette, Smartphone) indépendamment du taux d’usage dudit équipement. On peut donc se servir une fois par semaine de son PC portable et tous les jours de son smartphone, StatCounter comptera 1 Desktop et 1 mobile.
On voir donc qu’au niveau monde, le nombre de smartphones a doublé celui de Desktop en novembre 2016 et qu’il continue de croître (tandis que le nombre de tablettes stagne).
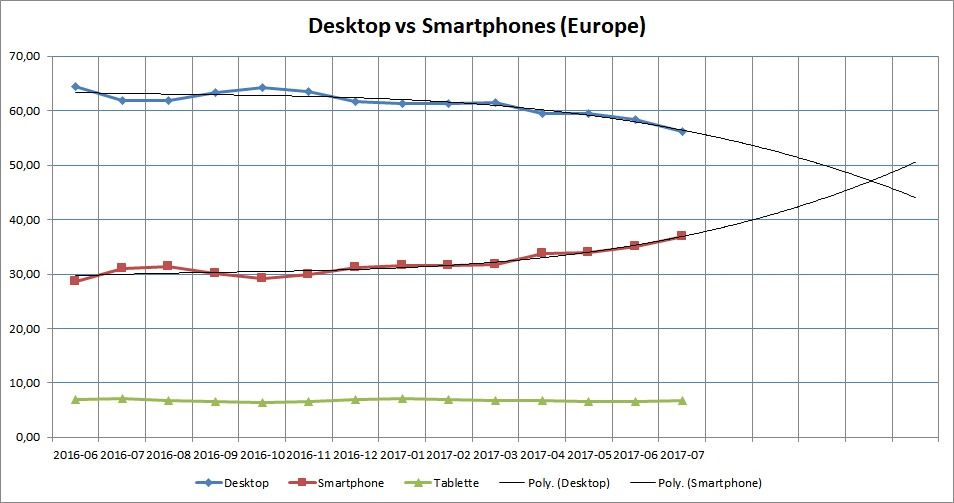
Ces chiffres sont à moduler au niveau de l’Europe. Globalement, le desktop reste majoritaire avec 56,17% des équipements recensés (en décroissance) contre 37% pour les mobiles (en croissance). Les courbes ne se croiseront donc a priori que fin 2017 – début 2018, avec un an de retard par rapport à la majorité de la planète.
Tous ces chiffres montrent simplement une chose : le smartphone est en train de supplanter le PC comme terminal informatique. Or Microsoft est ultra majoritaire dans le monde des PC avec plus de 84% de part de marché (stable). Si le PC disparait, et si Microsoft ne change pas, alors Microsoft disparaitra avec lui.
Dit autrement, Android est en train de supplanter Windows dans nos usages. Microsoft a donc le choix entre abandonner le PC qui reste à ce jour sa vache à lait, et changer de métier (car c’est en maîtrisant l’OS que Microsoft peut se permettre de dominer largement le monde du logiciel) ou se battre pour exister sur ce marché, mais avec une nouvelle offre vraiment différenciatrice et pas simplement similaire à celle d’Apple et de Samsung.
Des entreprises ayant radicalement changé de métier, on en connait : Hewlett Packard a bien commencé par fabriquer des instruments électroniques (oscilloscopes, calculatrices) avant de devenir un constructeur informatique. Ou encore Nokia, qui fabriquait à l’origine (en 1865-1871) du papier, avant de se développer dans le caoutchouc, le câble et l’électronique, bien avant de connaitre le numéro 1 mondial de la téléphonie mobile, de 1992 à 2011.
Mais tout porte à croire que Microsoft n’a pas lâché la partie. Le succès qu’il a rencontré avec sa surface, concept hybride entre l’ordinateur et la tablette, ayant donné naissance au PC 2-en-1, le pousse à chercher une autre voie dans le domaine des smartphones. D’aucuns auront ainsi annoncé un surface phone, pour surfer sur le succès de la surface. Mais rebaptiser un produit d’un nouveau nom n’est pas en soi révolutionnaire ni disruptif pour employer un nom à la mode. Microsoft cherche de nouveaux usages.
Et Microsoft pense en avoir trouvé un avec son concept « Continuum », qui permet à l’utilisateur de continuer à travailler avec son téléphone portable comme s’il avait un PC. Il suffit de pouvoir connecter un écran, un clavier et une souris à son téléphone pour bénéficier d’un grand écran et d’une saisie plus rapide. Ceci vous permet d’accéder rapidement à vos e-mails, vos photos, votre navigateur et des applications comme les réseaux sociaux ou Office.
Le produit le plus avancé matérialisant ce concept reste le HP Elite X3, qui propose un Desk Dock (station d’accueil qui permet de brancher clavier, souris et écran au smartphone) et un Lap Dock (une sorte d’ultrabook, mais sans RAM, sans CPU et sans disque ; juste un clavier et un écran). Un trio qui promet d'obtenir un smartphone, un PC de bureau et un ordinateur portable. Un 3-en-1 prometteur mais encore plombé par les manques de Windows 10 Mobile et des limites de continuum.
HPE Elite X3 Pro
L’usage de Continuum reste en effet limité à la navigation Internet, aux e-mails et à l'utilisation d’Office (documents Word, tableaux Excel, présentations Powerpoint). Mais ce n’est déjà pas si mal car ce sont les principales applications utilisées sur PC. Mais le minimum serait d’avoir un niveau de performance aussi proche possible que celui d’un PC.
Or Windows 10 Mobile ne fonctionne à ce jour que sur des processeurs spécifiques aux smartphones. Les puces des constructeurs, comme les Exynos de Samsung, intègrent toutes généralement un processeur Cortex, d’ARM, le concepteur de l’architecture. Il existe aussi des constructeurs qui conçoivent leurs propres processeurs et puces comme Qualcomm avec ses Snapdragon, basés sur une architecture ARM, Intel et ses puces Atom basés sur une architecture x86 (mais Intel vient de jeter l’éponge), Apple et ses puces A8, A10, etc, tous basés eux aussi sur ARM.
Pour faire tourner correctement une application sous Windows 10 Mobile, il faut donc faire un effort particulier d’adaptation pour coller à l’architecture ARM et à Windows 10 Mobile. Sans doute un de trop pour la plupart des développeurs, déjà bien occupés avec Android et iOS. Ce qui fait que la plupart des applications sous Windows 10 Mobile affichent des performances lamentables alors que sur PC, elles sont tout à fait au point.
Mais Microsoft continue à travailler sur son concept en essayant de gommer les principaux défauts de son concept actuel. Voici trois raisons qui nous poussent à dire qe Microsoft persiste :
-
Windows 10 (la version desktop et non la version Mobile) revient sur processeurs ARM et relance la course à l’ARMement. On se souvient du cuisant échec de la Surface RT, fonctionnant sous un Windows 8 (trop) spécifique pour ARM. Microsoft en a tiré les leçons et reviendra en 2018 avec un Windows 10 compatible supportant ARM et faisant tourner toutes les applications universelles ainsi que les applications historiques propres à l’architecture x86. Microsoft a beau expliquer que cette version ne sera homologuée que pour PC, et non pour smartphones, le seul intérêt de rendre Windows compatible avec ARM est de pouvoir attaquer le marché des mobiles. On peut donc espérer qu’une fois cette version de Windows 10 sortie, de nouveaux smartphones sortent, avec l’ensemble du catalogue Windows…Voilà le problème de la pauvreté du catalogue des applications réglé, ainsi que le problème des performances sous Windows Mobile : il n’y a plus d’adaptations à faire, c’est l’OS qui s’est adapté.
-
La prochaine mise à jour majeure de Windows 10, qui arrivera cet automne - proposera la fonction « Phone » aux possesseurs de smartphones Android et autres iPhone (soit 99,9% du marché). Cette application permettra de continuer à naviguer sur Internet depuis son PC, après avoir commencé sur son smartphone. Il suffira de partager la page que l’on consulte sur smartphone et de choisir l’app « Continuer sur PC » pour que celle-ci se retrouve sur son PC. Il s’agit d’une sorte de Continuum lite sur iOS et Android en somme et une façon d’habituer les utilisateurs à des liens renforcés entre smartphone et PC.
-
Le concept de Continuum est aussi copiée par la société chinoise Jide, qui annonce Remix Singularity, une application qui permettrait de transformer son smartphone Android en PC (similaire à Chrome OS) avec toutes les applications Android dessus. Comme Continuum, on pourra brancher un clavier, un écran et une souris sur son smartphone. Le concept semble donc avoir du bon.
Conclusion
Si le smartphone est bien le terminal informatique de demain, et si Microsoft veut encore espérer y jouer un rôle, il est indispensable pour ce dernier de revenir sur le marché avec un concept innovant (même s’il ne sera pas aussi disruptif que Microsoft aimerait le faire croire). Le fait que Microsoft travaille à rendre Windows 10 totalement opérationnel sur ARM dessine une stratégie assez claire :
-
Disposer d’un OS universel fonctionnant sous les 2 architectures du marché : Intel x86 (architecture CISC, omniprésente sur le marché du PC) et ARM Cortex (architecture RISC, omniprésente sur le marché des smartphones).
-
Réinvestir le marché des smartphones avec de nouveaux produits, qui pour perturber le mastodonte Android, doivent apporter un gros plus.
-
Ce plus serait un 2 ou 3 en 1, à l’image de la Surface qui propose à la fois une tablette et un PC. Microsoft pourrait ainsi proposer un smartphone qui serait aussi un PC (et éventuellement un portable) grâce à un Continuum enfin débarrassé des limites de Windows Mobile et de sa pauvreté d’applications.
Si malgré tout cela, les clients ne reviennent pas, Microsoft n'aura plus qu'à jeter l'éponger et changer de métier. Comme devenir le premier acteur dans le Cloud Computing par exemple.

