
La musique en haute définition

Paris le 15 août 2020
Si vous faites partie de la génération X, vous avez sans doute commencer à écouter votre musique préférée sur des platines vinyle ou des lecteurs de cassettes audio. Et vous êtes d'ailleurs peut-être encore attaché à vos disques vinyles et CD.
La génération Y a écouté la musique numérique en téléchargement, le modèle le plus connu étant celui d'Apple, j'ai nommé iTunes et son fameux baladeur iPod. Dans ce modèle, on avait encore une notion de possession, comme avec le disque vinyle ou le CD. On achetait une chanson, qu'on téléchargeait ensuite sur son baladeur ou son ordinateur.
La génération Z, quant à elle, n'écoute plus que du streaming, que ce soit via Spotify, Deezer ou Amazon Music. On ne possède plus rien, si ce n'est un droit d'écoute d'une multitude de chansons. Et c'est là que les choses se compliquent. Car quand on veut comparer les différentes offres d'une même plateforme musicale ou entre plateformes (histoire de choisir une offre en connaissance de cause), on découvre vite des termes barbares (cf. l'infographie ci-dessous du Figaro qui est assez parlante) tels que "formats OGG Vorbis" (Spotify), "AAC 256 kbit/s" (Apple Music), ou encore "MP3 à 128 kbit/s" et "16-Bit / 44.1 kHz en qualité FLAC" (Deezer). Avec des prix qui augmentent aussi vite que la soi-disant qualité de la musique.
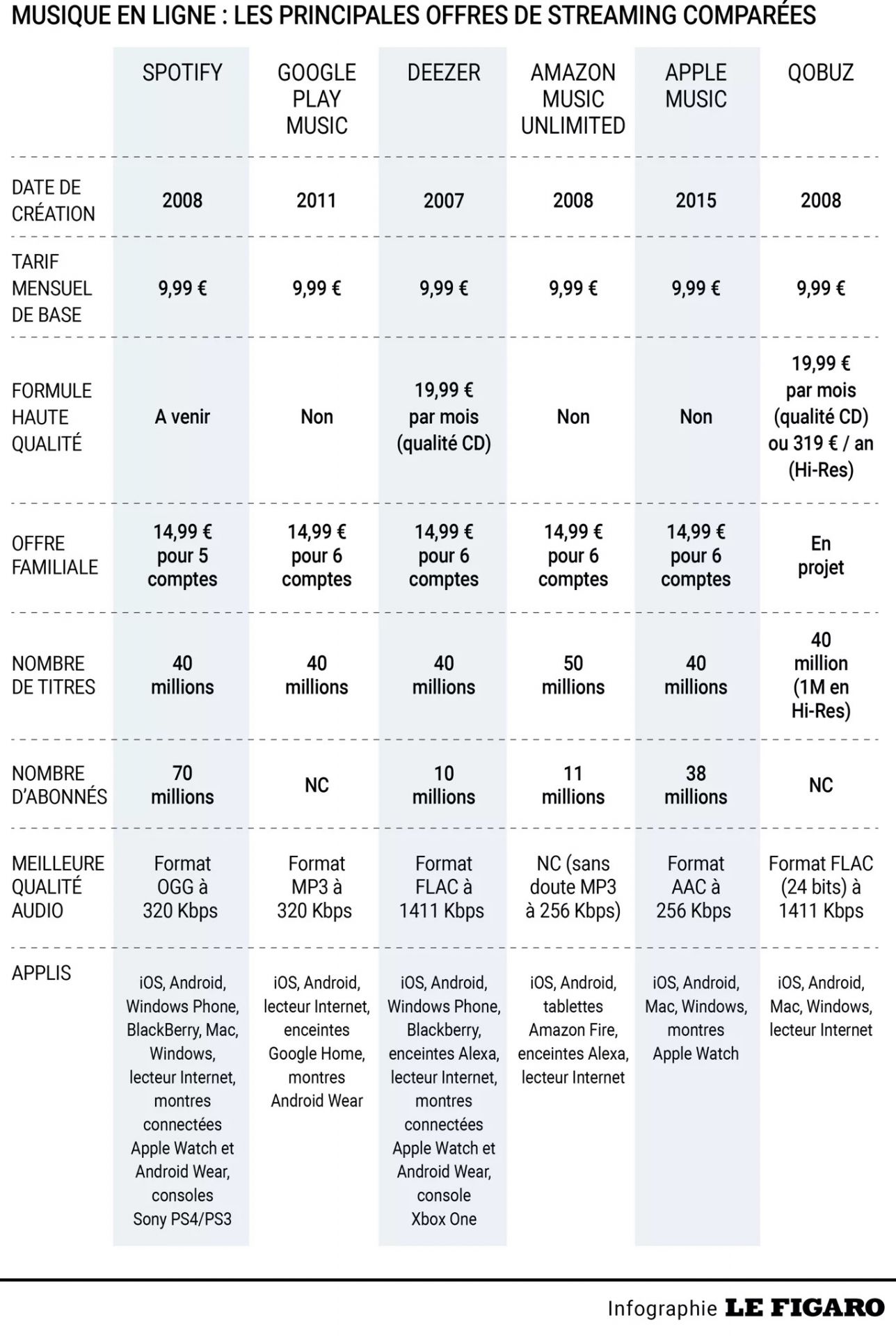
On est vite submergé de termes techniques plus obscurs les uns que les autres. Les journalistes eux-mêmes se mélangent les pinceaux, et confondent allègrement débit binaire (Bit Rate) à 320 Kbit/s et encodage 16 ou 24 bits, codec FLAC et fichiers OGG...
J'ai donc pris le taureau par les cornes en écrivant ce billet, histoire de clarifier les choses. Après tout, il vaut mieux savoir de quoi il retourne et si cela vaut la peine de payer aussi cher pour de la musique haute définition. Mais pour comprendre à quoi correspondent ces histoires de codage sur 24 bits, ou de format FLAC ou MP3, faisons d'abord quelques rappels sur la musique et le passage de l'analogique au numérique, car c'est là que se situe le nœud gordien du problème.
1 - La numérisation du signal
La musique, d'un point de vue scientifique, ce sont des ondes sonores qui se propagent à travers un milieu matériel "élastique" (c'est à dire qui se compresse et se décompresse) comme l'air, l'eau, les murs. Dans le vide, je vous le rappelle, personne ne vous entend crier.
Ces ondes acoustiques sont par nature des signaux analogiques (typiquement la variation de la pression acoustique de l'air). Ils sont continus et ne s'interrompent jamais ; ils changent simplement de valeurs, ces dernières étant infinies.
La musique numérique est donc un pur produit de l'électronique. Pour numériser un son, ll faut d'abord mesurer les variations de pression acoustique pour les convertir en variations de tension électrique (on fait çà avec un micro) que l'on va mesurer à intervalles réguliers pour les traduire en valeurs numériques que l'on va coder en binaire avec des 0 et 1. Ce qui nous amène à introduire 2 notions importantes : la Fréquence d'Echantillonnage (FE) et la Quantification, appelée aussi résolution binaire.
La fréquence d'échantillonnage (Fe) : c'est la vitesse à laquelle seront prélevés les échantillons pour que la reconstruction du signal de sortie (numérique) soit le plus fidèle possible au signal d'origine (analogique). La fréquence d'échantillonnage doit être suffisamment grande. En effet, si celle-ci est trop faible, comme sur la figure ci-dessous, les variations rapides du signal ne pourront être reconstituées. Si vous reliez les points de droite, vous serez loin d'obtenir la courbe rouge initiale de gauche (on rate notamment le 2ème creux).
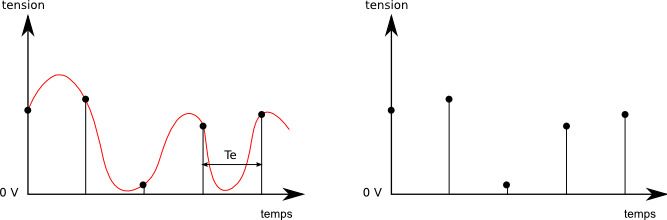
Alors qu'avec une fréquence d'échantillonnage plus élevée, comme sur la seconde figure, si vous reliez les points de droite, vous aurez déjà quelque chose de plus ressemblant à la courbe de gauche.
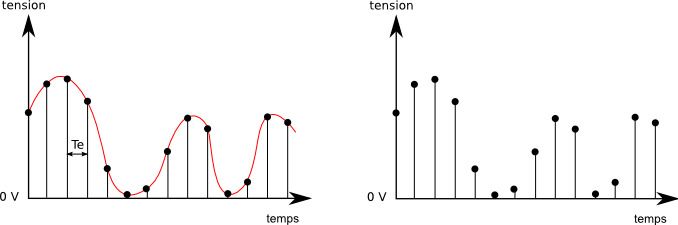
A contrario, si on utilise une fréquence d'échantillonnage trop élevée, on risque de se retrouver avec trop de mesures, une volumétrie trop importante, le tout pour un résultat qui n'en vaut pas la peine.
Mais alors, quelle est la bonne fréquence d'échantillonnage pour reconstituer fidèlement un son audio ? La réponse tient en 2 points :
- Le premier est le théorème de Shannon (ou théorème de Nyquist-Shannon) qui démontre que la représentation discrète d'un signal exige des échantillons régulièrement espacés à une fréquence d'échantillonnage supérieure au double de la fréquence maximale présente dans ce signal. Euréka ! C'est simple, il suffit de connaître la fréquence maximale du signal audio pour en déduire la fréquence d'échantillonnage. Sauf que la fréquence maximale du signal audio n'est a priori pas connue. Car elle dépend de la source, de l'instrument de musique typiquement.
- C'est là qu'intervient le 2ème point : il ne faut pas oublier, que nous pauvres humains avons nos propres limitations. Une oreille humaine entend généralement sur une plage de fréquence allant de 20 Hz à 20 kHz (lisez bien Kilo Hertz) ; En deçà de 20 Hz (dans les infrasons, utilisés par exemple par les éléphants pour communiquer à grande distance) et au-delà de 20 kHz (dans les ultrasons, que nos meilleurs amis les chiens et les chats entendent parfaitement), nous ne percevons plus le son. Bien sûr, ces limites varient avec l'âge et l'individu, mais le commun des mortels reste dans cette plage.
Il est donc inutile, pour la grande majorité d'entre nous, de transmettre des sons à des fréquences supérieures à 20 kHz. On ne les entendra pas. Il suffit donc d'éliminer du signal d'origine - et c'est plus facile à dire qu'à faire en réalité - tout ce qui est supérieur à 20 kHz (sinon, le théorème de Shannon ne s'applique plus). Notre fréquence maximale sera alors fixe et égale à 20 kHz. Notre fréquence d'échantillonnage devra donc être supérieure au double, soit donc 40 kHz ;
En pratique, on échantillonne à 44,1 kHz ; 44 kHz permet d'avoir un peu de marge par rapport au 40 kHz. Mais pourquoi 44,1 me demanderez-vous et pas 44 tout rond ? Tout simplement parce que 44,1 kHz était la fréquence exacte permise par les enregistreurs sur bande U-Matic de l'époque. Il y a des choses qui ne tiennent que par l'histoire...
Est-il alors nécessaire d'augmenter la fréquence d'échantillonnage au-delà de ces fameux 44 kHz ? On voit en effet des formats de musique encodés avec une fréquence de 96 voire 192 kHz...En fait, le débat n'est pas tranché. Augmenter la fréquence d'échantillonnage permettrait selon certains de percevoir (et non d'entendre) un son plus riche, plus naturel. Mais c'est peut-être subjectif. C'est ce que tendrait à dire cet excellent article du Monde.
Ce qui est sûr, c'est qu'augmenter la fréquence d'échantillonnage permet de réduire le coût des convertisseurs analogiques/numériques (je vous passe les détails, c'est trop technique pour cet article mais n'oubliez pas qu'il faut éliminer du signal tous les sons supérieurs à 20 Khz) et de réduire le bruit de quantification (ah tiens une nouvelle notion). Il n'est donc pas inutile d'échantillonner la musique à très haute fréquence. Et ceci nous amène donc à notre seconde importante notion qu'est justement la quantification.
La quantification ou résolution en bit (ou encore profondeur de bit) : La quantification est la seconde étape de la numérisation. Après avoir découpé le signal continu en échantillons, il faut mesurer l'amplitude du signal de chaque échantillon et lui donner une valeur. Cette valeur sera codée sur 8, 16, 20 ou 24 bits. Soit donc un nombre fini de valeurs possibles, pour un nombre initial infini. Ce qui va nous amener à faire des arrondis.
Prenons par exemple une quantification codée sur 2 bits : soit 22 valeurs possibles donc 4. On va donc encoder notre signal avec 4 pas de valeurs. Supposons que notre signal varie entre 0 et 10. On prendra donc des pas de 2,5 (10/4) :
Toutes les valeurs comprises entre 0 et 2,5 seront codées 00
Toutes les valeurs comprises entre 2,5 et 5 seront codées 01
Toutes les valeurs comprises entre 5 et 7,5 seront codées 10
Toutes les valeurs comprises entre 7,5 et 10 seront codées 11
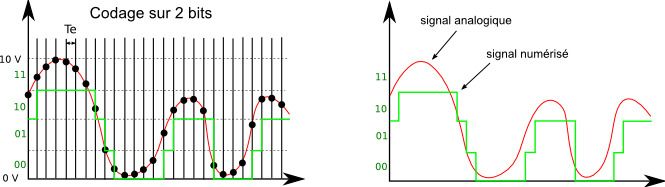
On voit donc le résultat de la quantification sur la courbe verte de droite, vs la courbe rouge d'origine. La différence entre la courbe réelle et la courbe verte s'appelle le bruit de quantification. Ce bruit résulte d'une perte définitive d'information, lié à l'arrondi qu'on fait entre la valeur réelle de l'échantillon et la valeur numérique que l'on est capable de coder. Il vaut donc mieux que ce bruit soit le plus petit possible.
Un codage sur 8 bits (28) donne 256 valeurs possibles, 16 (216) donne 65.536 valeurs, 20 bits donne 1.048.576 possibilités et 24 bits (224) autorise 16.777.216 valeurs. Ce qui permet de minimiser grandement l'arrondi vous le reconnaitrez.
En théorie donc, plus on a de bits (sans e messieurs s'il vous plait), mieux c'est. Comme le suggère l'image ci-dessous qui code le même signal que précédemment mais sur 4 bits au lieu de 2.
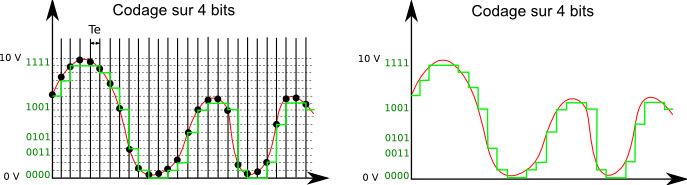
Notons aussi que plus on a de bits, plus la plage dynamique est importante. On mesure la dynamique comme la différence entre le volume maximal et le volume minimal perçu. La dynamique est importante surtout quand on numérise des sons émis par des instruments à impulsion unique, comme la cymbale typiquement.
Plus on a de bits, plus on peut encoder une valeur importante du signal. Là encore, rien que de très logique. Si notre signal variait de 0 à 100 et que l'on voulait le coder sur 2 bits, nous aurions des pas de 25 (au lieu des 2,5 de notre premier exemple), ce qui introduirait trop de "bruit" et rendrait la reconstruction du signal impossible. Le nombre de bit limite donc de facto l'amplitude du signal numérisé.
L'oreille humaine capte des niveaux d'intensité acoustique compris entre 0 et 120 dB (soit donc une dynamique de 120 db). Au-delà, les sons sont nocifs et peuvent détruire de manière irréversible les structures de l'oreille interne. Il faut donc un codage offrant donc une dynamique égale vorie supérieure, ce qui est possible à partir d'un codage sur 20 bits (la dynamique est grosso modo égale à 6 fois le nombre de bit).
Donc pour se résumer, une musique codée sur 24 bits c'est mieux que les bons vieux 16 bits du CD Audio. Car cela permet de réduire le bruit de quantification et d'augmenter la dynamique du signal. Mais une musique numérisée avec une fréquence supérieure à 44,1 kHz, dans les faits, c'est peu perceptible par l'oreille humaine. En tout cas, celle du commun des mortels. Reste que cela facilite la numérisation du signal (il faut éliminer tout signal supérieur à 20 Khz) et que cela diminue aussi le bruit de quantification, et c'est pour cela que les masters des studios sont toujours en 24 bits et 192 kHz.
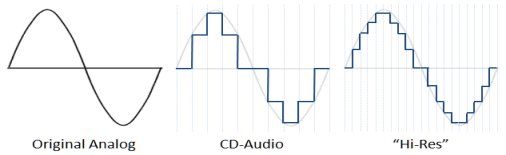
Pour simplifier, le 24 bits-96 kHz de l'audio haute résolution vs le 16 bits-44,1 kHz du CD audio, c'est à peu près cela :
Pour ceux qui achètent encore des supports physiques (CD, SACD, Vinyles), sachez que :
- Le CD Audio utilise une résolution de 16 bits et une fréquence d'échantillonnage de 44,1 kHz. Le tout est encodé selon la méthode PCM (Pulse Code Modulation). Je vous expliquerai ce qu'est l'encodage juste après.
- Le DVD Audio a fait monter la barre en permettant d'enregistrer de la musique en 24 bits avec une Fe de 96 kHz selon un codage PCM accompagné d'une méthode propriétaire de compression sans perte MLP ou « Meridian Lossless Packing ». Si le DVD-A a été déclaré hors marché en 2007, le PCM est encore aujourd’hui utilisé pour les fichiers Hi-Res Audio (Musique Haute résolution).
- Le SACD est un cas un peu particulier : il utilise un processus connu comme Direct Stream Digital (DSD) pour encoder l'audio. Le processus DSD a un taux d’échantillonnage de 2.822,4 kHz (ce n'est pas une erreur de frappe, c'est bien 64 fois plus que celle du CD) mais sa résolution est de 1 bit.
Quoi !?! Un seul et unique bit !?! Mais c'est tout le contraire de ce que je viens de vous expliquer... Oui mais n'oubliez pas qu'on sur-échantillonne le signal à une fréquence de 2.822,4 kHz, soit 64 fois plus que pour le CD. La valeur du signal entre 2 échantillons consécutifs ne va donc pas varier énormément. Elle n'aura pas le temps. Et on peut donc coder la variation sur 1 bit. Car avec le DSD, on ne stocke que la variation par rapport à l'instant d'avant, et non plus la valeur absolue comme dans le PCM. On stocke donc plus fort (1) ou moins fort qu'avant (0). C'est la méthode Delta Sigma.
Maintenant que vous maitrisez (ou du moins que vous savez à quoi correspondent) les 2 principaux concepts de la numérisation d'un signal audio, la fréquence d'échantillonnage et la quantification, passons maintenant aux algorithmes d'encodage.
2 - L'encodage d'un signal numérique
Reprenons depuis le début. Nous enregistrons un son, une onde sonore analogique, via un microphone. Ce dernier convertit les ondes sonores en impulsions électriques. Puis nous convertissons ce signal électrique en signal numérique. Pour cela, nous échantillonnons le signal puis le quantifions via un convertisseur analogique numérique (ADC). C'est le début de l'encodage. Reste généralement à compresser la donnée, mais ce n'est pas obligatoire.
On encode un signal numérique grâce à des codecs (nom qui vient de COdeur - DECodeur et non pas COmpresser-DECompresser comme j'ai pu le lire). C'est un procédé logiciel et/ou matériel permettant de coder et de décoder un signal numérique en vue d'une transmission (diffusion) ou d'un stockage. Certains codecs peuvent compresser ou chiffrer la donnée en sus (c'est notamment important dans le cadre de la vidéo qui est très volumineuse), mais ce n'est pas leur fonction première qui est simplement d'encoder le signal en vue de le stocker (la base première de tout enregistrement).
D'un côté, nous avons donc un codec qui code pour émettre (ou écrire sur un disque), et de l'autre, un codec qui décode pour recevoir (ou lire un disque). Pour que cela marche, il faut que les codecs se comprennent, donc que le codec soit du même constructeur/éditeur (ce qui n'est pas souhaitable d'un point de vue concurrentiel), ou qu'ils respectent tous les 2 la même norme. Evidemment, c'est la 2ème solution qui a été adoptée.
Nous avons donc des normes qui régissent les règles d'encodage, de compression ou de chiffrement de ces fameux codecs. Ce qui n'empêche évidemment pas certains éditeurs/constructeurs d'essayer d'imposer leurs codec propriétaires (je pense notamment à Microsoft et Apple, coutumiers du fait).
L'encodage audio utilisé détermine au final :
- Le nombre de canaux : mono, stéréo (2) ou multi-canaux (5.1, 7.2, etc.)
- La fréquence d'échantillonnage ; On vient d'en parler. Elle est de 22,05 kHz, 44,1 kHz, 48 kHz, 88,2 kHz, 96 kHz, 176,4 kHz, 192 kHz ;
- La résolution de chaque échantillon en nombre de bit (8, 16, 20 ou 24 bits); On vient aussi d'en parler. Cela permet de quantifier l'amplitude du signal.
- Le débit binaire : Le débit binaire correspond à l'ensemble de données consommées pour transmettre un flux audio par unité de temps. Par exemple, un débit binaire de 128 kbps signifie qu'une seconde de son est codée avec 128 00 bits (soit 16 Ko).
Chaque encodage possède une limite de débit. Prenons par exemple le "Morse", qui utilise un système d'encodage binaire constitué d'un signal court et d'un signal long. Si on transmet trop vite les signaux, l'oreille humaine ne saura plus distinguer les sons courts des sons longs. On est donc obligé de limiter la vitesse à laquelle on transmet le morse, soit un débit binaire de 40 bits/s environ.
Plus le débit binaire d'une piste audio est élevé, plus elle prendra d'espace sur le disque dur de votre ordinateur et plus elle nécessitera de bande passante pour être transmise via Internet (ce qui peut être un problème quand on fait du streaming). Et plus le débit binaire est élevé (pour un même codec), meilleure est la qualité audio de l'enregistrement.
Il peut être constant (Constant Bit Rate ou CBR), ou variable (VBR). Un débit binaire constant signifie que le codage de chaque segment sonore consomme une quantité constante de bits. Y compris le codage d'un segment silencieux qui nécessite pourtant beaucoup moins de bits que le codage d'un segment sonore intense. À la différence du débit constant, le débit variable ajuste donc automatiquement la qualité du codage à différents intervalles. Dès lors, les intervalles simples en termes de codage utiliseront un débit binaire inférieur, tandis que les intervalles plus complexes seront codés avec le débit binaire supérieur. L'utilisation du débit variable permet d'obtenir une qualité audio supérieure tout en gardant une taille de fichier raisonnable.
C'est ce fameux chiffre qui accompagne les MP3, MP3 128 ou 320 Kbps. À 320 Kbps, la qualité s'approche (mais n'est pas ausis bonne) de celle d’un CD audio dont le débit est de 1.411 Kbps. Le débit binaire du SACD est quant à lui de 2.822,4 Kbps. - Le taux de compression des données. Les Codecs sont en effet souvent utilisés pour compresser les données, histoire d'optimiser le stockage (mais ça, c'était surtout avant) et pour pouvoir diffuser ces mêmes données sur Internet. N'oublions pas que la 4G de votre smartphone, ce n'est pas toujours que du haut débit.

Les principaux codecs audios utilisés dans la musique sont :
- Le LPCM (Linear Pulse Code Modulation). Notamment utilisée dans les CD audio, avec un codage 16 bits et une fréquence de 44 kHz. C'est un Codec sans compression (et donc sans perte de données).
- Le DSD (Direct Stream Digital). C'est le standard utilisé pour les Super Audio CD ; C'est un codec sans compression (et donc sans perte). C'est aussi le seul, avec le LPCM du DVD-Audio, à supporter le son multicanal (en sus des codecs utilisés avec la vidéo comme le DTS-HD et autres).
- Le FLAC (Free Lossless Audio Codec). Comme son nom l'indique, son usage est libre de droit. Le FLAC permet d'aller en théorie jusqu'à une qualité de codage de 32 bits et 655 kHz, soit bien au-delà des capacités de l'oreille humaine. Par contre, la taille des fichiers est logiquement très importante, une musique de 4 min encodé en FLAC haute définition pouvant ainsi dépasser les 50 Mo. C'est un codec avec compression mais sans perte.
- Le ALAC (Apple Lossless Audio Codec) : c'est l'équivalent du FLAC mais propriété d'Apple bien que finalement libre de droit. Réservé aux afficionados de la marque à la pomme, car le FLAC est bien plus universel. Légèrement moins performant que le FLAC, l'ALAC opère tout de même une compression de l'ordre de 40 à 50%. Il permet d'atteindre en théorie un codage 32 bits avec une fréquence de 384 kHz (contre 655 kHz pour le FLAC, mais qui entendra la différence ?).
- Le Monkey’s Audio : Ce codec possède un meilleur taux de compression que le FLAC, mais le décodage nécessite autant de ressources (processeur) que l'encodage, ce qui est un peu ennuyeux. Oui car les ressources dont on parle pour le décodage, c'est le processeur de votre baladeur ou de votre smartphone... C'est un codec avec compression mais sans perte.
- Le WMAL (Windows Media Audio Lossless) : c'est le cousin du WMA (cf. ci-après). C'est un codec avec compression mais sans perte.
- Les fameux MPEG-1 Audio et MPEG-2 Audio layer I (MP1), layer II (MP2) et layer III appelé MP3 (de MPEG-1/2 Audio layer 3). Ce sont des codecs avec compression mais aussi avec perte de données et donc de qualité ; Le MP3 est l'un des codecs les plus répandus malgré l'apparition du FLAC, car hautement paramétrable (on peut faire varier le débit binaire, choisir un débit constant ou variable, etc.). La perte de qualité due à la compression est masquée par la qualité moyenne du matériel d’écoute : baladeurs, écouteurs à oreillettes, smartphones, ou haut-parleurs bas de gamme des ordinateurs.
- Le MPEG-2 partie 7 : codec connu sous le nom de AAC (Advanced Audio Coding) qui se basait dessus avant d'utiliser le MPEG-4 partie 3. C'est un codec avec compression et avec perte.
- Le MPEG-4 Partie 3 sous-partie 3 : codec plus connu sous le nom de AAC et principalement utilisé par Apple sur iTunes. Ce Codec est un peu le « MP3 de chez Apple ». Il a les mêmes qualités et défauts que le MP3 à quelques détails près ; il est légèrement meilleur à débit égal. En AAC, on obtient l’équivalent d’une qualité CD audio avec un débit de seulement 96 Kbps au lieu des 320 du MP3. À cela s’ajoute la possibilité de gérer des sons sur 48 canaux différents, ce qui le rend apte à encoder des DVD audio ou vidéo. C'est un codec avec compression et avec perte.
- Le Vorbis : un chouïa meilleur que le MP3. Sa structure en paquets le rend par ailleurs bien adapté à une utilisation en diffusion continue (streaming) sur l'internet, notamment pour les radios en ligne. C'est pourquoi Spotify l'utilise. C'est un codec avec compression et avec perte.
- Le WMA : Codec développé par Microsoft ; Il fut à l'origine présenté pour remplacer le MP3 grâce à ses taux de compression plus élevées. C'est un codec avec compression et avec perte. Son équivalent sans perte est le WMAL.
Il existe aussi des Codecs audio que l'on trouve souvent associés à la vidéo, sans perte : DTS-HD, Dolby TrueHD, MLP (Meridian Lossless Packing) utilisé dans les DVD, MPEG-4 ALS ou SLS, RealAudio Lossless... ou avec perte comme le Dolby Digital (AC3), DTS, etc.
3 - Les formats audio

En audio, on ne parle pas de conteneur (contrairement à la vidéo) mais de format. Mais c'est la même chose. Le conteneur est l'enveloppe qui contient l'audio qui a été encodé avec un codec (les données brut) ; Le conteneur permet de diviser puis ranger les données en blocs ordonnées, pour qu'on puisse ensuite chercher une piste, éditer une donnée, etc.
Le format qui définit la structure du fichier permet ainsi de :
- Commencer à jouer le fichier alors qu'on n'en connaît pas encore la fin,
- Jouer un fichier à partir du milieu sans connaître le début,
- Sauter sur un emplacement déterminé,
- Enregistrer des métadonnées (image de pochette, auteur, année, genre, etc.)
- Gérer les droits de reproduction numérique (DRM),
- Adapter automatiquement le niveau au local d'écoute.
Un conteneur donné n'est pas compatible avec tous les codecs. Et c'est pourquoi on associe souvent codec et format audio et qu'on a tendance à mélanger les 2. Ce qui ne facilite pas la tâche quand on veut comprendre quelque chose et ceci explique la confusion qui règne entre codec et format.
Les principaux format audios sont :
- Le WAVE (extension .wav) : initialement développé par Microsoft et IBM et associé au codec LPCM la plupart du temps, même s'il peut contenir d'autres codecs ; Il ne gère pas les métadonnées (artiste, album, pochettes…), contrairement à ses concurrents.
- Le DSF (DSD Stream File, extension .dsf) & DFF (DSD Interchange File Format, extension .dff) : format associé au DSD.
- Le FLAC (extension .flac). Ce sont des containers minimalistes comparés aux containers OGG. Mais ce sont les plus courants.
- Le ALAC (extension .alac) : format associé au codec du même nom.
- Le APE (qui veut dire grand singe en anglais, extension. .ape) : format associé au codec Monkey's audio.
- Le OGG (extension .ogg) : ce format peut contenir du FLAC, mais est surtout utilisé avec le codec Vorbis. Ce container autorise le mixage de pistes de nature différentes (audio, données, métadonnées), contrairement au conteneur FLAC.
- Le MP3 (extension .mp3) : format utilisant le codec du même nom ((MPEG-1 Audio Layer-3).
- Le AAC (Advanced Audio Coding, extensions .aac, .mp4, .m4a pour MPEG-4 audio, ou m4p pour protégé, ou .m4b pour les books/livres audio) : C'est le format associé au codec MPEG-4 Partie 3. Il offre également des propriétés de gestion des droits d’auteur (DRM).
- Le AIFF (Audio Interchange File Format, extensions .aif ou .aiff) : C'est l'équivalent du WAVE sur Apple. Il contient principalement du PCM donc, mais gère les métadonnées contrairement au WAVE (artiste, album, pochettes…).
- Le CAF (Core Audio Format, extension .caf) : développé par Apple en successeur de l'AIFF.
- Le WMA (extension .wma) : Format associé au codec du même nom...Il a les mêmes qualités et défauts que le mp3, mais contrairement au AAC, il n'a pas bénéficié de l'effet iTunes ou d'une autre plateforme musicale et est donc mort-né...Le WMA offre pourtant une gestion pointue des droits d’auteur (DRM ou Digital Right Management).
Dans la pratique, mélanger codec et format n'est pas bien grave. Souvent le format et le codec se confondent. Mais savoir que les 2 concepts existent permet de comprendre pourquoi on peut parler de fichier OGG FLAC et de fichier OGG Vorbis, ou pourquoi certains parlent de format en parlant de FLAC (qui veut dire Free Lossless Audio Codec je le rappelle).
Tout ce laïus juste pour comprendre la différence entre codec et format ? Mais non, rassurez-vous...Tout cela permet de mieux comprendre le sabir utilisé par les plateformes musicales dans leurs offres et de choisir enfin en connaissance de cause.
4 - En conclusion
Si vous avez à choisir le codec et format, privilégiez plutôt le codec FLAC, certes plus gourmand en stockage que le codec MP3 (mais le stockage ne vaut plus grand chose de nos jours), mais qui vous garantira une meilleure qualité (pour autant que ce ne soit pas un vulgaire MP3 réencodé/converti en FLAC).
Le codec FLAC vous permet de disposer a minima d'une qualité audio CD (soit un codage sur 16 bits et une fréquence d'échantillonnage de 44,1 kHz). On trouvera aussi des masters audios codés sur 24 bits/192 kHz, mais vous n'entendrez probablement pas de différence avec le 24/96 qui suffira amplement à votre bonheur, pourvu que vous soyez équipé de lecteurs et écouteurs certifiés Hi-Res Audio.
Si vos FLAC ne sont destinés qu'au stockage de votre musique (sans mixage ou autre), alors privilégiez les conteneurs FLAC natifs. Sinon, orientez-vous vers les conteneurs OGG qui permettent de mixer différentes pistes.
Si pour vous, la qualité compte, voici parmi tous les fournisseurs de musique, une sélection classée par ordre de qualité croissante.
Les plateformes de musique de qualité équivalent au CD :
- Spotify : toute la musique que j'aime, elle vient de là, de Spotify, au format ogg/vorbis
- Apple Music : que du format acc à 256 Kbps ; le ALAC ce n'est pas pour tout de suite hélas.
- Deezer : du mp3 128 ou 320 Kbps au FLAC 16 bits/44.1 kHz selon l'abonnement.
- Amazon Music : à l'heure où j'écris, la musique HD d'Amazon n'est disponible qu'aux Etats-Unis mais devrait arriver en Europe d'ici peu. En attendant, il faut se contenter d'un vulgaire MP3 à 320 Kbps.
- Idagio : Musique classique au format AAC 160/192 kHz, MP3 320 Kbps et FLAC 16 bits 44.1 kHz
On trouvera aussi des plateformes de musique haute définition :
- Tidal : des formats AAC 320 kbps, FLAC 16 bits/44.1 kHz et MQA 24 bits/96 kHz (!?!) - un format FLAC avec un encodage avec perte propriétaire qui devrait signer son arrêt de mort. Et c'est pour cela que je ne vous en ai pas parlé.
- Qobuz : des formats MP3 320 kbps et FLAC jusqu'à 24 bits/192 kHz, selon l'abonnement.
- 7digital : des formats MP3 320 kbps et FLAC 24 bits
- Hd-tracks : WMA/WAV, AIFF, FLAC, ALAC encodés jusqu'à 24-bit/192kHz
- Primephonic : musique classique en haute résolution : du MP3 320 Kbps au FLAC 24 bits selon l'abonnement.
Les sites proposant de la qualité SACD/DSD (mais évidemment pas en streaming contenu du volume des fichiers) :
- Native DSD : comme son nom l'indique, ce site propose en téléchargement des albums au format natif DSD.
- Pro Studio Masters : là encore, le nom est assez parlant. Le site propose au téléchargement des formats 24-bit AIFF, FLAC, MQA et DSD / DSF.
Allez, bonne écoute...et portez-vous bien.

