
Comment gérer la transition vers le cloud computing

L'informatique traditionnelle a toujours été conçue et construite sous forme de silos technologiques : postes de travail, serveurs, réseaux, stockage, logiciels et applications. Pour construire et gérer un système d'information complet, il vous fallait généralement réunir des experts issus de tous ces corps de métier, chose qui était encore assez facile, et les faire travailler ensemble, ce qui était déjà plus dur.
Mais ça, c'était avant, comme dirait mon ami Chris. Car le "cloud computing", le "software-defined datacenter", la convergence des systèmes, les architectures orientées Web, Docker et DevOps sont depuis passés par là et ont rebattus les cartes. Toutes ces technologies, méthodes ou outils peuvent sembler complexes et sans lien particulier entre eux. Mais ils sont en fait souvent complémentaires et peuvent considérablement simplifier la vie des DSI dans la longue transformation de leur traditionnel système d'information vers un système agile, élastique et moins coûteux. Cet article vous aidera à tirer parti de ces nouvelles technologies et nouvelles pratiques.
| 1. Le Cloud Computing est l'avenir de l'informatique 2. Cloud Public ou Privé ? 3. A l'origine était la virtualisation 4. De la virtualisation au Cloud 1.0 5. Du Cloud au Software-Defined Data Center (SDDC) 6. L'hyperconvergence matériel au service du SDDC 7. L'OS du Cloud et du SDDC 8. Un Cloud pour Docker et DevOps |
1 - Le Cloud Computing est l'avenir de l'informatique
Ce titre peut sembler enfoncer des portes ouvertes pour certains. Mais il m'arrive encore de lire des phrases définitives de la part de gens très sérieux comme "le Cloud a été créé par les constructeurs pour relancer les ventes de serveurs dans un marché en berne". Diantre : moi qui pensais que le Cloud permettaient justement aux entreprises d'éviter de brûler leur capital dans l’achat d'infrastructures coûteuses de plus en plus complexes et dans l’embauche d’ingénieurs spécialisés pour les faire fonctionner, de passer de coûts fixes à des coûts plus variables, en rapport direct avec l'activité de l'entreprise. Manifestement, il y a encore en 2015 quelques sceptiques.
Pourtant, dans de nombreux secteurs comme l’automatisation des forces de vente, la gestion de la relation client (CRM), la gestion des ressources humaines, l’approvisionnement en ligne ou les e-achats, les logiciels sous licence existants sont désormais systématiquement remplacés par des solutions SaaS. En fait, le marché s'est retourné en 2012 (3 ans déjà !), suite au lancement en février 2011 par Vivek Kundra, directeur fédéral des systèmes d'information au sein de l'administration Obama, d'une nouvelle stratégie baptisée "cloud first", obligeant les agences fédérales à adopter des solutions de cloud computing par défaut. Ce qui a obligé les grands éditeurs américains à s'adapter, dans le sillage d'Amazon (EC2 a été lancé en 2006 après 4 ans de développement) et de Google. Microsoft, devenu un acteur principal du Cloud avec Office365 et Azure, a même nommé à sa tête Satya Nadella, anciennement responsable de l’offre cloud, c'est tout dire. Le marché européen a suivi dans la foulée. Le Cloud a ainsi généré, selon le Forrester, 58 milliards de $ de chiffre d’affaires en 2013 (dont 62% pour le SaaS), et la tendance devrait se poursuivre avec un CA qui devrait franchir les 191 milliards de $ d’ici à 2020.
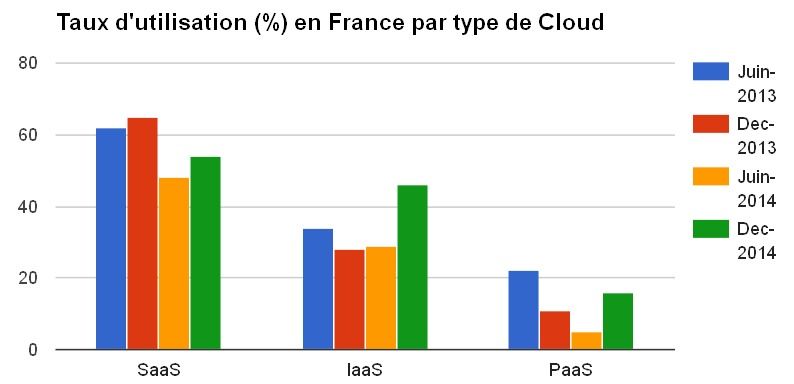
Les chiffres communiqués par PAC pour la France en décembre 2014 sont assez parlant : Les entreprises sont ainsi 55% à déclarer recourir à des solutions de cloud, contre 29% en juin 2014. Les entreprises utilisent en priorité des applications en mode SaaS (54%). Les offres IaaS sont utilisées par 46% des répondants à l'enquête du cabinet. D'après ce dernier, elles intéressent plus particulièrement les entreprises de moins de 500 salariés qui utilisent ces solutions pour de l’hébergement d’applications (54%), des tests (49%), et de l’hébergement de sites Web (46%). Le PaaS reste quant à lui en retrait car il s'agit d'une offre essentiellement destinée aux développeurs informatiques.
Les entreprises, en adoptant le cloud, recherchent bien sûr des baisses de coûts, mais avant tout la souplesse, la rapidité de déploiement et la facilité de mise à jour. Car le cloud se caractérise par :
-
Des services à la demande : mise à disposition de ressources informatiques ou plus généralement de services au moment où l'entreprise en a besoin.
-
Un accès réseau étendu permettant aux utilisateurs d'accéder aux services de n'importe où et depuis divers appareils (le fameux ATAWAD).
-
Une mutualisation des ressources : les ressources informatiques sont mise en commun et partagées par plusieurs entreprises, ce qui permet d'optimiser leur taux d'occupation et donc leurs coûts de revient.
-
Une élasticité et une réactivité : de nouvelles ressources sont mises à disposition rapidement, voire automatiquement.
-
Une utilisation du service mesuré permettant une facturation à l'usage.
Le cloud est l'avenir de l'informatique. Si l'on accepte donc ce fait comme une tendance lourde, il est alors du devoir des entreprises et plus particulièrement des DSI de faire évoluer leurs SI traditionnels pour adopter ces nouvelles technologies et en tirer parti. Encore faut-il bien comprendre comment ce marché évolue, et établir une stratégie adaptée à son entreprise. Faut-il opter pour le cloud public, privé, ou hybride, le mode SaaS, PaaS ou IaaS, être opérateur ou externaliser...les questions sont légions.
2 - Cloud Public, Privé, Hybride ?
Une des premières questions que l'on se pose, lorsque l'on souhaite établir une stratégie Cloud, c'est la question du cloud public ou privé. Pour bien comprendre le problème, posons déjà quelques définitions (je ne reviens quand même pas sur ce qu'est le Cloud) :
-
Le Cloud public est géré par un fournisseur tiers et plusieurs entreprises peuvent y accéder via Internet, pourvu qu'elles y soient autorisées. Avec le Cloud public, de multiples entités (tenant) se partagent ainsi les mêmes ressources informatiques mises à disposition par le fournisseur. Le choix de ce dernier devient évidemment critique : fiabilité et pérennité du fournisseur, coût total sur l'ensemble du cycle de vie (transition, exécution et réversibilité du service), flexibilité et agilité du modèle (élasticité technique et opérationnelle, souplesse contractuelle) et portée géographique sont les principaux critères de choix. Pour certains, la nationalité du fournisseur joue aussi, mais ce n'est manifestement pas un critère prépondérant.
-
Le Cloud privé est dédié, comme son nom l'indique, à une seule entreprise, déployé en ses locaux, dont l'exploitation est assurée par ses propres équipes ou sous-traitée (on parle alors de Managed Private Cloud, le partage se fait sur les procédures, l’équipe d’exploitation et les outils de suivi) ou hébergé chez un prestataire (on parle alors de Hosted Private Cloud, le partage se fait également sur l'infrastructure du fournisseur). Dans ce dernier cas, il ne sera alors accessible que via des réseaux sécurisés (VPN) aux utilisateurs dûment habilités. Le cloud privé convient bien aux grandes entreprises qui disposent des moyens et des compétences pour construire ou gérer un cloud privé ou à celles dont les besoins en matière de criticité et sécurité des données sont importants. Même si la différence de niveau de sécurité entre un cloud public et un cloud privé hébergé est plus symbolique qu'autre chose.
-
Le Cloud hybride est une structure mixte qui permet de combiner les ressources internes du cloud privé à celles externes du cloud public. Une entreprise qui utilise un Cloud hybride peut par exemple avoir recours au Cloud public ponctuellement, pour son Plan de Reprise Informatique (PRI) ou lors de pics d’activité. Le reste du temps, elle se contentera de ses ressources internes. L’hybride permet en effet d’alterner entre les deux modèles en fonction de la conjoncture et des besoins ; On peut ainsi répartir chaque projet, environnement de développement, maquette ou campagne de tests entre privé et public. Ce mode mixte permet aussi de garder en interne les données confidentielles et de déporter le reste sur un cloud public. Cela diminue largement les charges d'exploitations d'infrastructure, cantonnées au minimum requis. Autre exemple, les couches applicatives d’une application peuvent être hébergées dans le cloud privé et la couche de présentation de cette même application stockée dans le cloud public, puisque celle-ci requiert une grande élasticité et ne gère pas de données critiques. On peut par là même répartir les serveurs frontaux dans le monde entier, au plus près des utilisateurs, et donc réduire le temps de latence.
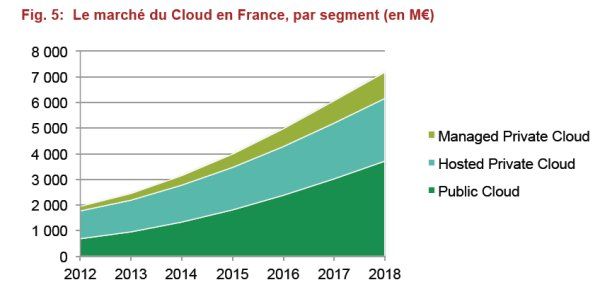
Comme le montre les chiffres de PAC de décembre 2014 sur le marché français, le cloud public rencontre moins de succès que le cloud privé, mais de peu. Il a surtout de belles perspectives de croissance devant lui. Le cloud privé devrait quant à lui croître modérément. Rien de très surprenant à cela : le cloud privé, surtout interne, reste évidemment plus coûteux que le cloud public, car dédié et non mutualisé. Même s'il est bien adapté aux besoins des grandes entreprises, qui ont des exigences importantes et/ou spécifiques auxquelles le cloud public a du mal à répondre. Certains oiseaux de mauvais augure prétendent même que le cloud privé est mort. La réponse la plus évidente serait donc d'opter aujourd'hui pour un cloud public. C'est sans doute répondre un peu vite. C'est en effet oublier le poids de l'informatique traditionnelle et les nombreux freins aux changements. On ne passe pas directement d'une infrastructure traditionnelle interne à un cloud public sans risques majeurs. Le changement est beaucoup trop important, la marche trop haute, pour les collaborateurs (et pas que ceux de la DSI) de l'entreprise. Il faut savoir gérer par pallier la transition pour éviter d'une part toute perte de contrôle et d'autre part un rejet complet des utilisateurs.
Les systèmes d'informations traditionnels ne sont en effet généralement pas conçus pour fonctionner correctement dans le cloud. Les applications ne sont pas toujours compatibles avec la virtualisation, la distribution et la standardisation des composants. De nombreuses applications reposent encore sur des composants logiciels, spécifiques ou standards, dont les versions ne sont plus maintenues ni supportés par les fournisseurs. Autant dire que ces applications ne seront pas éligibles au cloud public immédiatement. Il faut migrer ses composants, adapter ses applications mais surtout apprendre à gérer ses configurations dans le temps. Les composants de votre cloud public seront en effet mis à jour par votre hébergeur et à son rythme. Il vous faudra suivre et adapter vos applications. Pire encore, dans le cadre du mode SaaS, c'est l'hébergeur (en général l'éditeur du progiciel) qui décide de la date de mise en production d’une nouvelle version, et cela pour tous ses clients. Il vous faut alors gérer la formation de vos utilisateurs de pair avec la gestion des changements de votre cloud. Et le rythme des évolutions fonctionnelles peut vite devenir infernal pour vos utilisateurs. Le risque de rejet n'est pas négligeable.
Quant aux grands projets de migration, le recul aidant, les chiffres donnent des indications précieuses : 50% des migrations dépassent leur budget prévisionnel et deux tiers des projets dépassent leur durée prévisionnelle. Il y a manifestement une sous-estimation des difficultés inhérents à de tels projets.
Il n'est donc pas surprenant, dans ce contexte, que le cloud hybride soit le "buzz word" de cette fin d'année. Le cloud hybride constitue en effet une transition moins risquée vers le cloud public. Encore faut-il avoir constitué un cloud privé. Ce dernier n'est pas un concept inventé par les DSI pour contrecarrer les percées du cloud public, comme certains aimeraient le faire croire. Il permet à la DSI de pouvoir exercer pleinement son métier et de se roder à tous les sujets du cloud : catalogue de services, administration, élasticité des ressources, distribution des composants logiciels, facturation, réversibilité, etc. Selon l'adage qui veut que l'on n'externalise que ce que l'on maîtrise, la DSI doit savoir gérer un cloud privé, ce qui implique préparer son infrastructure et ses applications, avant de migrer vers un cloud hybride puis éventuellement vers un cloud 100% public.
Construire, gérer un cloud privé et transformer ses applications ? Vaste programme aurait dit le Général de Gaulle. Passons en revue les composants essentiels à cette transformation.
3 - A l'origine était la virtualisation des serveurs
Quand l'informatique dite distribuée, symbolisée par les mini-ordinateurs VAX de DEC, Unix d'HP et de SUN ou Windows de Microsoft (par opposition à l'informatique centralisée constituée de "mainframe" IBM) est apparue dans les années 90, il était souvent préférable d'installer une application par mini-ordinateur. Il était en effet impossible de garantir, contrairement au mainframe, une isolation et donc une allocation de ressources pour chaque application. Faire cohabiter deux applications sur un même serveur signifiait que l'une pouvait ralentir l'autre. Il fallait de plus s'assurer que la pile logicielle des applications (version d'OS, version des middlewares, etc.) restait compatible dans le temps : si une application requérait une nouvelle version de SGBD (Système de Gestion de Base de Données), il fallait vérifier que cette version n'entraînait pas de régression sur les "colocataires" utilisant ce même SGBD. Dédier un serveur à une application coûtait bien sûr assez cher : cela revenait à multiplier les serveurs, qu'il fallait bien ensuite maintenir et administrer, avec des ressources souvent largement inutilisées : la puissance de calcul du serveur était taillée pour absorber le pic de charge et restait sous-utilisée le reste du temps. Fort heureusement, la mini-informatique a vite adopté les technologies de virtualisation. Elle a autorisé le partitionnement des ressources, permettant sur un même serveur physique d'isoler les applications, et de dédier des ressources à chacune.
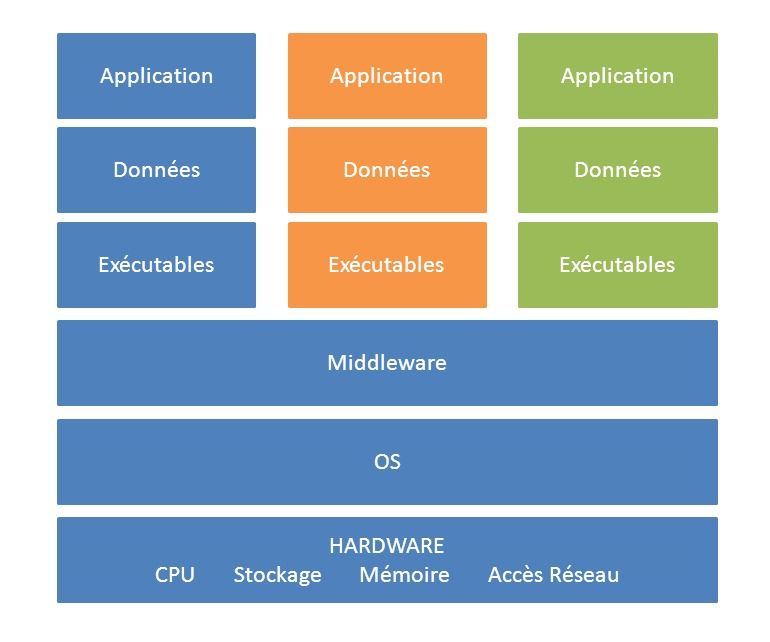
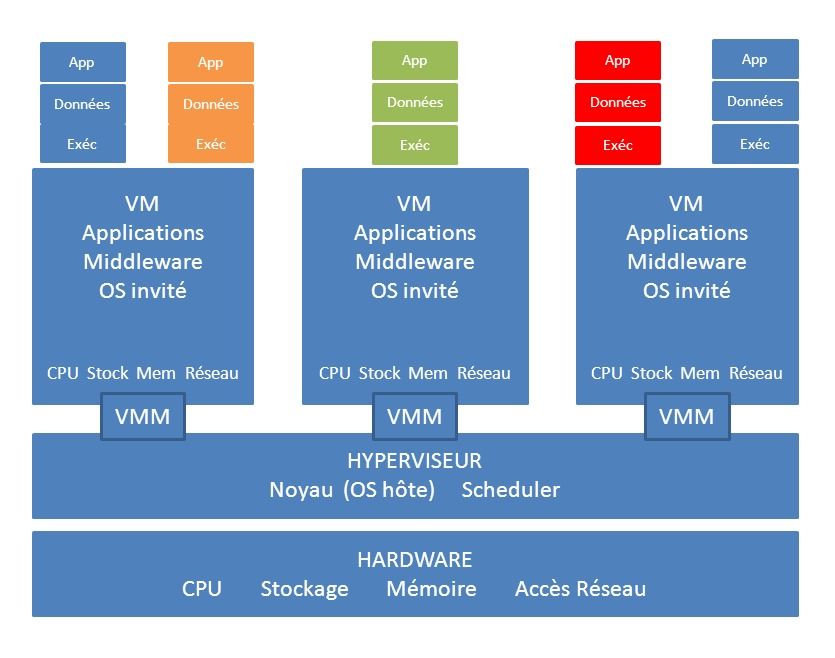
Dans un système de virtualisation, les ressources physiques informatiques d'un serveur (principalement les processeurs, la mémoire, le stockage, les accès réseau) sont découpées et affectées à des conteneurs. Ces conteneurs, plus communément appelées machines virtuelles (VM), ne sont rien de plus que des fichiers constituant les ressources virtuelles de la machine. L'hyperviseur (un OS réduit à son simple noyau - kernel) se charge de l'allocation des ressources physiques et de la bonne exécution des VM. Sur cette plate-forme virtuelle, on peut donc installer différents systèmes d'exploitation (Linux et Windows principalement), du middleware et des applications. Les serveurs ainsi virtualisés se composent donc au final du matériel sous-jacent, de l'hyperviseur, du moniteur de machine virtuelle (VMM), des machines virtuelles (VM), des systèmes d'exploitation, des applications et de leur pile logicielle installées sur chacune de ces machines virtuelles.
4 - De la Virtualisation au Cloud Computing
Le Cloud Computing n'est pas une surcouche à la virtualisation, mais en tire grandement partie. L'élasticité (scalability) des infrastructures du Cloud repose en grande partie sur la virtualisation (et la parallélisation des traitements), en apportant une certaine indépendance entre matériel et applications. Mais le Cloud Computing a introduit deux autres composants essentiels sans lesquels le Cloud ne serait pas ce qu'il est et qui sont le catalogue des services qui permet à "l'utilisateur" du Cloud de commander en self-service de nouvelles ressources ou services, et l'automatisation de l'approvisionnement par un orchestrateur, qui permet ainsi de fournir en 2 heures un environnement complet là ou l'informatique traditionnelle met plusieurs semaines, et donc de gagner en agilité et réactivité. On peut rajouter un autre composant, qui est la facturation à l'usage, mais qui est surtout valable pour les opérateurs et qui est moins pertinent pour une DSI mono-client opérant un Cloud privé interne, qui ne peut que répartir ses coûts.
Pour autant, le Cloud Computing dans ses premières versions ne résolvait pas tout : les ressources étaient certes virtualisées pour la plupart, mais encore gérées en silos : réseaux, stockage, serveurs, sécurité...Mais c'était déjà un premier pas vers le Graal : une infrastructure élastique, agile, et sécurisée.
Les différentes offres de Cloud Computing vous sont sans doute assez familières. On représente souvent les formes les plus classiques de Cloud sous une matrice de responsabilité répartissant les rôles entre l'opérateur du cloud et la DSI sur IaaS, PaaS et SaaS.
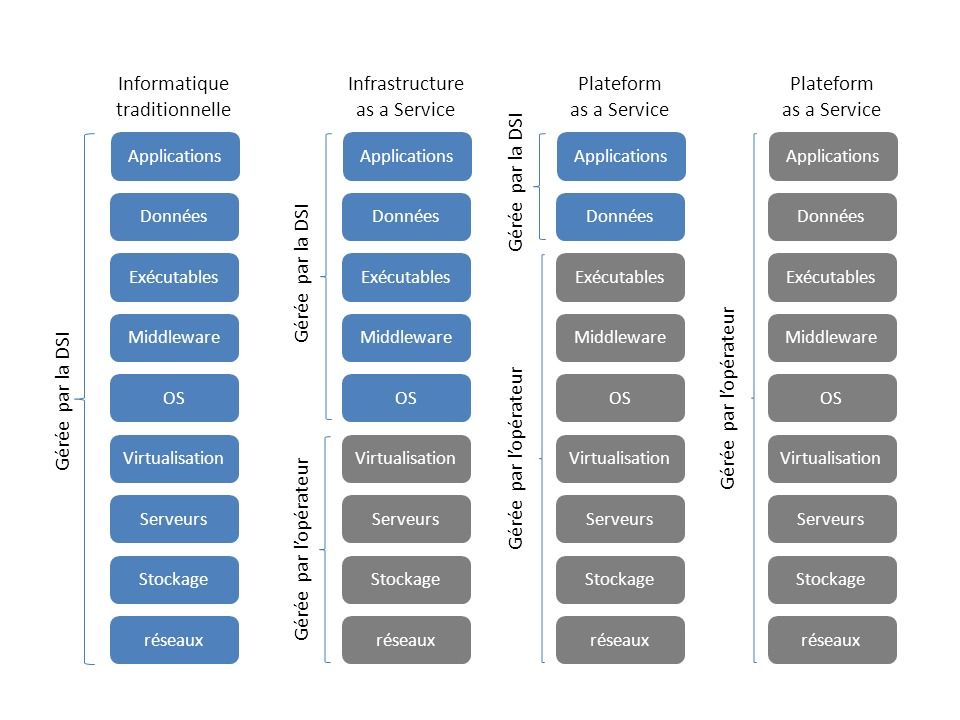
L’IaaS et le PaaS ont été pensés comme des services à destination des DSI, et plutôt pour des développeurs alors que le SaaS est directement accessible à tous les utilisateurs habituels du logiciel ou de l'application. Ce qui ne veut pas dire qu'il n'y a aucun travail d'intégration ou de paramétrage, bien au contraire.
En mode SaaS, l'application est souvent (mais pas toujours) gérée par l'éditeur du logiciel, qui au lieu de vendre de la "boîte" et de l'intégration, s'est mis à vendre des "services en ligne", éditeur qui sous-traite en général à un autre fournisseur la fourniture en mode PaaS ou IaaS de l'infrastructure. On retrouve ainsi en cascade les opérateurs de Data Center, fournissant les locaux, les fluides (eau, électricité, groupes électrogènes, batteries), la climatisation et les liens avec les opérateurs télécoms, les opérateurs de IaaS et PaaS, s'appuyant sur les premiers pour fournir une infrastructure informatique, et les opérateurs de SaaS, s'appuyant sur ces derniers pour fournir un service fonctionnel aux entreprises.
Le choix entre ces 3 services dépend de vos besoins et de vos utilisateurs. Vous ciblez vos développeurs, optez pour le PaaS. Vous souhaitez faire héberger vos applications maison sur une infrastructure élastique et réactive, optez pour le IaaS et déployez vos applications dans le cloud. Vous utilisez depuis longtemps des progiciels, passez directement vers le mode SaaS. L'intégration des applications n'est pas un problème, la plupart des éditeurs offrant des interfaces standardisés de type Web Services et supportant les ETL du marché, Talend en tête.
5 - Du Cloud Computing 1.0 au software-defined datacenter
Le Cloud Computing 1.0, basé sur la virtualisation des serveurs et l'automatisation, aurait probablement fait long feu s'il en était resté là. Car l'informatique ne se limite pas à la simple puissance de calcul d'un serveur. Il faut aussi pouvoir allouer du stockage, ouvrir ou fermer des accès réseaux rapidement, augmenter les débits à la demande. Les utilisateurs du Cloud ne se sont donc pas contentés de commander des machines virtuelles. Ils ont aussi commandé le stockage et les débits réseaux qui allaient avec, avec les mêmes attentes en matière d'élasticité et de rapidité. Il fallait donc pouvoir approvisionner de manière dynamique non seulement les machines virtuelles mais aussi la quantité de mémoire, le nombre de processeurs alloués à chaque VM, leur espace de stockage, les réseaux hauts débits associés, l'ouverture des flux à travers les systèmes de sécurité...
Il a donc fallu aussi virtualiser le stockage et l'infrastructure réseau, rendant là encore le service plus indépendant du matériel sous-jacent. Mais pour pouvoir gérer l'hétérogénéité du matériel, la virtualisation ne suffisait évidemment pas : il fallait un logiciel capable d'approvisionner les ressources et de les administrer uniformément, quel que soit finalement leurs différences. L'équivalent d'un hyperviseur pour une machine virtuelle, mais adapté au stockage et au réseau. C'est ainsi que sont nés le Software-Defined Network (réseaux définis par logiciels), le Software-Defined Storage (stockage définis par logiciels) et le Cloud Computing 2.0 (allocation de VM à la mémoire et à la CPU près).
Prenez une baie de stockage : si vous souhaitiez répliquer les données de cette baie de stockage (pour de besoin de PRI ou de haute disponibilité), il vous fallait traditionnellement utiliser les logiciels fournis par le constructeur et "embarqués" dans le matériel du constructeur. Dans le cas du SDS, l'intelligence n'est plus dans l'équipement et liée au matériel mais est remontée dans un logiciel de gestion et d'automatisation. Vous pouvez alors gérer vos baies de stockage hétérogènes comme un seul pool de stockage et allouer des espaces ou répliquer des données depuis ce dernier, et ceci de manière programmable et donc dynamique et automatisée, à travers des interfaces de programmation (API) fournis par les constructeurs. Tant qu'à faire, vous pouvez également gérer la déduplication, le thin provisioning (allocation dynamique des espaces de stockage selon l'usage), les sauvegardes depuis ce même logiciel...
Il en va de même pour les services réseau : traditionnellement, il vous fallait connecter vos routeurs, commutateurs et autres load-balancers, puis les configurer. Avec un software-defined network, vous définissez vos pools de prises réseau (les commutateurs) et vos pools de connectivité (commutateurs cœurs de réseau et routeurs). Vous pourrez alors définir des commutateurs virtuels auxquels seront rattachés des serveurs virtuels, communiquant par des réseaux là encore virtuels.
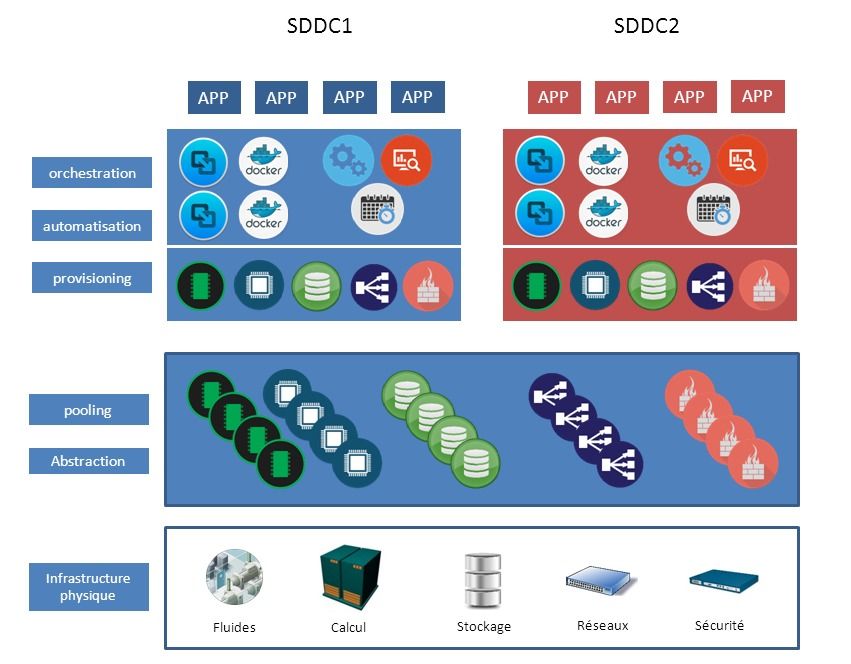
Le software-defined DataCenter (SDDC) est donc un centre de calcul dans lequel on a étendu les concepts de la virtualisation (l'abstraction, la mise en commun des ressources (pooling) et l'automatisation des traitements) à l'ensemble des ressources et des services du datacenter. Dans un SDDC, tous les éléments de l'infrastructure (routeurs et commutateurs réseaux, équilibreurs de charge, stockage, déduplicateurs, postes de travail, serveurs et composants de sécurité) sont virtualisés et délivrés comme un service, avec un niveau d'abstraction poussé à son maximum. Les services sont pilotés à partir d'un ou plusieurs logiciels de gestion et d'automatisation, permettant à un administrateur de manager tous les composants du centre de calcul, de sa configuration, son approvisionnement à son administration. Cette administration centralisée et cette automatisation sont rendues possibles par la normalisation des API mis à disposition par les composants matériels.
La promesse du SDDC, c'est d'accélérer la mise en œuvre de tous les services informatiques pour les utilisateurs et les propriétaires d'applications, et de réduire les coûts et de simplifier l'environnement pour les DSI. Encore faut-il, pour tenir cette promesse, que tous les composants du SDDC soient compatibles et interopérables entre eux, me direz-vous. Si votre logiciel de contrôle ne peut pas communiquer avec votre système de stockage faute d'API ouvertes, ou si votre commutateur ne dispose pas d'API permettant de gérer la qualité de service, vous risquez d'avoir du mal à mettre en œuvre et gérer votre datacenter correctement. Le plus simple est donc de préserver une certaine homogénéité dans l'infrastructure, sans pour autant devenir dépendant d'un seul constructeur. Ce qui nous amène naturellement à la question du matériel.
6 - Quel matériel pour le software-defined datacenter ?
Construire son datacenter en silo restait encore relativement simple : Le réseau était jusqu'à présent un élément peu lié au reste de l'infrastructure : il suffisait de prendre des composants interopérables (Cisco, Juniper, Huaweï, etc...) et de choisir son protocole de routage associé à sa topologie. Le stockage demandait un peu plus d'intégration avec les serveurs mais les réseaux SAN et NAS ont permis un découplage important et l'émergence de systèmes de stockage virtualisés (EMC, HDS, HP, IBM, NetApp...). Enfin les serveurs x86, en dehors des mainframes, ont mis tout le monde d'accord sur la base d'OS Linux ou Windows.
Cela demandait quand même de savoir gérer les relations commerciales avec ces différents fournisseurs, qui souvent n’ont pas les mêmes politiques de "licensing", de trouver les compétences nécessaires pour tester l’intégration entre les systèmes et administrer les équipements, et de gérer leur maintenance (gestion des patchs, des versions, des changements). Pas si simple au final...
Mais s'assurer que tous ces matériels sont interopérables et de plus compatibles avec la pile logicielle de votre datacenter demeure une gageure : les matrices de compatibilité des constructeurs ne vous donnent qu'une simple indication et non une garantie sur le niveau de compatibilité de leurs matériels. Seul un test peut vous le dire. Alternativement, on peut reporter cette exigence sur le fournisseur, en optant pour des systèmes déjà intégrés par le constructeur et embarquant nativement une ou plusieurs piles logicielles de gestion.
C'est ainsi que nous avons eu d'abord les systèmes intégrés réunissant dans une même armoire ressources de calcul, stockage et réseau (un bon exemple est Cisco Unified Computing System, qui intégrait le calcul, le réseau et les unités de stockage dans un rack unique de 19 pouces, le tout avec un hyperviseur de type VMware). Puis, par simple innovation incrémentale, les constructeurs ont conçu les systèmes convergés, intégrés et pré-paramétrés en usine (typiquement VCE VBlock, Cisco/NetApp FlexPod, Lenovo PureFlex, Oracle Exadata Database Machine). Les composants d'un système convergé sont intégrés grâce à une pile logicielle unique. C'est le grand "plus" de ce dernier, car sinon, il faut bien l'admettre, cela ressemble encore fortement à un assemblage de technologies existantes classiques dans un seul rack, éventuellement extensible. Ainsi, les vBlock de VCE intègrent les serveurs lames UCS de Cisco, les commutateurs réseaux Ethernet et SAN du même constructeur et des systèmes de stockage EMC. Le tout fonctionnant avec les piles logicielles de VMware (réseaux et serveurs) et d'EMC (stockage). Autant dire que la complexité de ce genre de système reste encore importante puisqu'il faut savoir maîtriser l'ensemble de ces technologies. Mais il permet en même temps de gérer chaque composant séparément. Ainsi, le stockage peut être attaché directement à un serveur mais peut aussi être utilisé comme un système de stockage disjoint, de type SAN ou NAS. L'intérêt des systèmes convergés est de pouvoir augmenter les capacités de son infrastructure en rajoutant simplement un nouveau "bloc" aux blocs existants. On peut ainsi étendre la capacité de son datacenter quasiment à l'infini...
 Enfin, les systèmes hyperconvergés (Nutanix, SimpliVity et Scale Computing sont les sociétés les plus en pointe), poussent le concept d'intégration au maximum, supprimant typiquement les besoins d'un réseau SAN dédié au stockage. Les systèmes hyperconvergés consolident sur une seule pile logicielle tous les composants d’infrastructure, comme pour les systèmes convergés, et toutes les technologies intégrées sont administrées d'un point central, sur une console unique, offrant ainsi un service proche de celui d'une "appliance", l'automatisation et la virtualisation en plus. La grosse différence avec les systèmes convergés ? Le logiciel. Par exemple, le contrôleur de stockage n'est plus embarqué dans la baie au niveau matériel mais est assuré par le logiciel, généralement réparti sur plusieurs noeuds d'un cluster, pour assurer la haute disponibilité de la fonction. Typiquement, chez Nutanix, le logiciel centralise la capacité de stockage local de chaque serveur et le configure comme un seul pool de stockage. Les données qui doivent être accédées rapidement seront stockées localement sur disque flash, tandis que les données moins fréquemment utilisées pourront être déplacées sur des disques durs magnétiques classiques ou sur un des serveurs ayant de la capacité en réserve. Un petit film valant mieux qu'un long discours :
Enfin, les systèmes hyperconvergés (Nutanix, SimpliVity et Scale Computing sont les sociétés les plus en pointe), poussent le concept d'intégration au maximum, supprimant typiquement les besoins d'un réseau SAN dédié au stockage. Les systèmes hyperconvergés consolident sur une seule pile logicielle tous les composants d’infrastructure, comme pour les systèmes convergés, et toutes les technologies intégrées sont administrées d'un point central, sur une console unique, offrant ainsi un service proche de celui d'une "appliance", l'automatisation et la virtualisation en plus. La grosse différence avec les systèmes convergés ? Le logiciel. Par exemple, le contrôleur de stockage n'est plus embarqué dans la baie au niveau matériel mais est assuré par le logiciel, généralement réparti sur plusieurs noeuds d'un cluster, pour assurer la haute disponibilité de la fonction. Typiquement, chez Nutanix, le logiciel centralise la capacité de stockage local de chaque serveur et le configure comme un seul pool de stockage. Les données qui doivent être accédées rapidement seront stockées localement sur disque flash, tandis que les données moins fréquemment utilisées pourront être déplacées sur des disques durs magnétiques classiques ou sur un des serveurs ayant de la capacité en réserve. Un petit film valant mieux qu'un long discours :
Les systèmes hyperconvergés représentent probablement l'avenir des software-defined data center. Ils permettent d'optimiser leur fonctionnement en faisant passer le matériel au rang de commodités. Car ce qui compte dans un système hyperconvergé, c'est le logiciel et notamment le choix de l'hyperviseur global. Même VMware, jusqu'alors partie prenante des systèmes convergés avec VCE, a sorti son propre matériel (une première pour l'éditeur de logiciels) avec "EVO:RAIL" et "EVO:RACK". L'éditeur package ainsi sa suite de logiciels : vSphere (virtualisation des serveurs et gestion du stockage), virtualSAN (virtualisation du stockage), vCenter (gestion des déploiements et administration centralisée, équilibrage des ressources de manière dynamique, etc.), vRealize Log Insight (gestion des logs)...avec du matériel issu d'alliances avec ses partenaires (Dell, HP, et Hitachi pour ne citer qu'eux). Il est bien sûr possible de choisir des systèmes plus agnostiques en matière d'hyperviseurs, comme Nutanix ou d'autres, qui supportent différents hyperviseurs dont KVM, Microsoft Hyper-V, Citrix Xen et VMware vSphere.
Le choix du matériel, convergé ou hyperconvergé, n'est finalement pas si innocent que cela. Il peut vous amener à choisir de facto une suite logicielle ou au contraire vous laisser libre de votre choix. Mais au fait, avons-nous vraiment le choix ?
7 - Quelle "pile logicielle" pour le software-defined datacenter ?
Avec des systèmes convergés ou hyperconvergés agnostiques en matière d'hyperviseur, le choix du matériel importe peu au final. Mais le choix de la pile logicielle gérant ces systèmes est lui crucial. Il existe à ce jour plusieurs grandes alternatives :
Les solutions OpenSource :
-
Apache CloudStack : Ce jeu de composants logiciels est issu du rachat en 2011 de Cloud.com par Citrix, qui cédera un an plus tard les sources à la fondation Apache mais continuera à commercialiser une version payante de CloudStack. CloudStack supporte les hyperviseurs KVM, vSphere et Citrix XenServer mais n'a pas réussi à rallier autant de soutien des constructeurs qu'OpenStack. Il lui manque ainsi de nombreux connecteurs, ou leurs supports sont annoncés en décalage par rapport à son concurrent. Mais contrairement à OpenStack qui peut être vu comme une collection de projets OpenSource et une boite à outil, CloudStack a été conçu d'abord par Cloud.com comme un framework intégré.
-
HP Eucalyptus : un logiciel OpenSource peu connu, racheté en septembre 2014 par HP et sur lequel il a construit une partie de son Cloud Helion privé (cloud bientôt arrêté) et hybride. Il est surtout connu comme compatible avec les API du Cloud d'Amazon AWS. Le projet est né dans le département des sciences informatiques de l'Université de Santa Barbara (Californie). Eucalyptus est ensuite devenu une entreprise commerciale en 2009. En 2012, Eucalyptus Systems a passé un accord avec Amazon Web Services (AWS) permettant aux DSI de créer des clouds hybrides entre un cloud privé Eucalyptus et un cloud public Amazon Elastic Compute Cloud (EC2).
-
OpenStack (porté par la fondation du même nom) : OpenStack est LA référence OpenSource en matière de cloud privé, car elle a réussi à réunir autour d'elle le support de nombreux constructeurs et acteurs, ce qui garantit une compatibilité maximale avec la plupart des équipements. Elle est très complète mais elle nécessite des développements complémentaires pour offrir une solution clé en main. Il faut aussi pouvoir évoluer au fil des mises à jour OpenStack. Pour ne rien gâcher, il existe de multiples distributions sur le marché, et toutes ne sont pas compatibles entre elles.
Pour vous donner un ordre d'idée du caractère "boîte à outils" d'OpenStack, cette suite d'outils comprend les modules intégrés suivants :
-
Service de calcul (gestion des VM) : Nova ; compatible avec la plupart des hyperviseurs comme HyperV, KVM, VMware vCenter et Citrix XenServer
-
Service de stockage d'objets : Swift
-
Service d'images (images permettant d'initialiser les VM) : Glance
-
Interface Web de paramétrage et gestion (tableaux de bord) : Horizon
-
Gestion des identités : Keystone
-
Gestion des réseaux à la demande (on-demand networks) : Neutron (auparavant nommé Quantum). Neutron dispose d'un connecteur permettant d'intégrer OpenFlow qui prend en charge la partie "abstraction". Il fonctionne aussi avec OpenDaylight, Open vSwitch, Cisco OpFlex et ACI, Juniper Contrail...
-
Service de stockage (service de disques persistants pour les machines virtuelles) : Cinder
-
Orchestration (service d'orchestration à base de template) : Heat
-
Service de télémétrie (service de métrologie notamment pour la facturation) : Ceilometer
-
Service de base de données à la demande : Trove
-
Service de Big data grâce à Hadoop : Sahara
-
Service de "Bare Metal provisioning" : Ironic
-
Service de gestion des systèmes de fichier partagés : Manila
-
Service de Middleware à la demande : Zaqar
-
Service de gestion des DNS : Designate
-
Service de gestion des clés et secrets : Barbican
Notez que l'on peut construire des clouds publics avec OpenStack, comme Numergy (qui s'est mis sous protection judiciaire il y a peu) et CloudWatt, nos deux clouds "souverains", ou encore OVH, Softlayer et Rackspace.
Les solutions propriétaires standard de facto :
-
Amazon Elastic Compute Cloud (EC2) : le modèle d'Amazon est un cloud complètement public, contrairement à celui de VMware. Il s'appuie sur une technologie propre à Amazon (mais basé sur des composants OpenSource) et offre une multitude de services permettant de construire son centre de calcul. Amazon a d'ailleurs renoué avec les bénéfices grâce au cloud. Amazon est maintenant rentable pour le deuxième trimestre consécutif. Le géant américain a dégagé un bénéfice de 79 millions de dollars au troisième trimestre, à comparer à une perte de 437 millions il y a seulement un an. Amazon Web Services compte désormais plus d'un million de clients actifs dans 190 pays et ses ventes ne cessent de progresser. Après avoir grimpé de 81% au deuxième trimestre, elles ont encore bondi de 78% au dernier trimestre, à 2,1 milliards de dollars. Au troisième trimestre, le cloud est même devenu la première source de profits d’Amazon, rapportant 472 millions de dollars, soit 52% du résultat opérationnel de l’entreprise.
-
Google Cloud Plateform : Le plus gros concurrent d'Amazon sur le secteur du cloud public, même si Google dispose de moins de services qu'AWS et est plus orienté IaaS et PaaS. Google est aussi probablement meilleur sur le BigData que son concurrent, ce qui ne vous surprendra pas. De la même manière, Google utilise de nombreux composants OpenSource pour bâtir son cloud public.
-
Microsoft Azure Pack : il s'agit d'une offre packagée par Microsoft qui permet de construire rapidement un cloud privé, compatible avec le cloud public Azure du même éditeur. Ce qui permet de passer au cloud hybride voir au cloud public (Microsoft) presque sans s'en rendre compte...
-
VMware vCloud suite : VMware dispose de tous les modules pour gérer un SDDC : vCenter, vSphere pour virtualiser les serveurs, vRealized (Automation, Operations et Business pour la facturation), virtualSAN pour la gestion du stockage, etc. C'est sans conteste le leader dans la gestion des clouds privés. Et cela a donc forcément un prix...VMware a l'avantage d'être le pionnier de la virtualisation et dispose d'une importante base installée en terme d'hyperviseur. Ce qui facilite bien évidemment le déploiement du reste de la suite. Certaines entreprises, comme voyages-sncf.com, font néanmoins le saut vers OpenStack pour challenger VMware dans sa politique de tarification.
Nous avons donc le matériel, des systèmes convergés ou hyperconvergés et la pile logicielle (open source ou propriétaire) pilotant ce matériel. Ce qui nous permet de construire et gérer notre centre de calcul (software-defined data center) comme un cloud privé. Mais il faut pouvoir adapter ses applications à ce mode. Et il y a probablement autant de cas particulier que d'applications, même si nous avons déjà pu identifier quelques écueils majeurs, comme la compatibilité des composants. Il est donc difficile de traiter ce sujet en quelques lignes ou même en quelques paragraphes. Il existe cependant des solutions, des architectures et des pratiques bien adaptées au cloud : les Architectures Orientée Web (WOA) basées sur des interfaces de type REST, les architectures micro-services, Docker et DevOps.
8 - Un Cloud privé pour Docker et DevOps
J'ai expliqué pourquoi le cloud privé était une étape à privilégier dans la transition de son SI vers le cloud. Il y aussi une autre raison de vouloir construire un cloud privé. Il ne faut pas oublier les besoins des développeurs de la DSI, eux-mêmes en prise avec les besoins des directions métiers. Ces derniers demandent à la fois des livraisons plus fréquentes de nouvelles fonctions et une plus grande fiabilité dans les déploiements. Mais à quoi bon pouvoir livrer plus rapidement si l'infrastructure ne suit pas ; imaginez (sans trop d'efforts) un projet retardé par la livraison d'un nouvel environnement qui prendrait 6 semaines...Il faut donc être à la fois en mesure de faire evoluer son infrastructure et ses applications rapidement. Tout va finalement de pair, applications et infrastructure.
Et la philosophie de DevOps, qui vise justement à accélérer le rythme des livraisons et à améliorer la qualité des déploiements en production, colle bien à ce besoin. Quand on parle de DevOps, on parle bien sûr de méthodes agiles, d'intégration continue, de tests d'acceptation automatisés et de déploiements continus en production. Mais on parle aussi beaucoup de Docker, cette technologie qui permet d'embarquer tout l'environnement dont a besoin l'application pour s'exécuter, dans des conteneurs. Ce qui facilite grandement le déploiement continu, vous en conviendrez, puisque le développeur n'a plus à se soucier des compatibilités des composants déployés en production, mais dispose des mêmes environnements du développement à la production. Finis les célèbres excuses du développeur du type "c'est bizarre, çà marche pourtant chez moi...". Docker favorise aussi l'indépendance vis à vis de l'opérateur du Cloud, ce qui n'est pas à négliger quand on souhaite passer du cloud privé au public, gérer à son rythme les changements des composants ou faire jouer la réversibilité. Votre application a juste besoin d'un OS hôte et de son conteneur, qu'on peut déployer sur un serveur ou un autre...
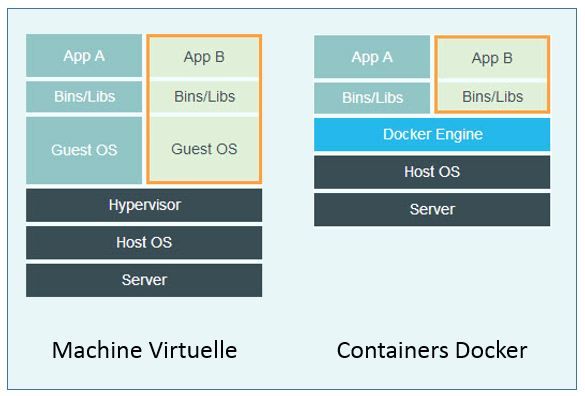
Quel rapport entre Docker, OpenStack et le Cloud privé me demanderez-vous ? Et bien parce que les développeurs peuvent s'appuyer sur OpenStack (ou tout autre plate-forme Cloud compatible) pour demander un "hôte Docker", puis utiliser Docker dans leur "hôte Docker" pour exécuter leurs containers. Vous remarquerez au passage qu'il n'est plus nécessaire d'utiliser une technologie de virtualisation, l'hyperviseur étant remplacé par le "Docker Engine", ce qui n'arrange évidemment pas certains fournisseurs. A l'exception de Microsoft qui a besoin de créer une machine virtuelle Linux sous Hyper-V afin de pouvoir lancer Docker derrière.
Bien sûr, utiliser OpenStack, Nova et son plugin Docker pour créer simplement des "hôtes Docker", c'est un peu le marteau-pilon pour écraser la mouche. On pourrait simplement s'appuyer sur les services fournis par Google Container Engine ou Amazon EC2 Container Service. Mais ce sont là deux services de Cloud public, et non privé. Si votre objectif reste la construction d'un Cloud privé, OpenStack prend tout son sens.
Attention, Docker n'est pas forcément adaptée à toutes les applications (et vice-versa). Ni à tous les niveaux de service. Docker est bien adapté aux applications basées sur des micro-services. Chaque micro-service constitue un composant discret de l'application. Les conteneurs Docker sont un bon moyen d'exécuter le code des micro-services sans attendre le lancement d'un système d'exploitation complet, ni subir la gestion qu'induit une machine virtuelle pour chaque copie. Pour s'adapter aux variations de charge, il suffit de dupliquer "à la volée" les conteneurs et les micro-services qui s'y exécutent : le nombre de copies en exécution augmentera donc avec la charge et diminuera en période creuse. Une application basée sur les micro-services sera également plus facile à maintenir si vous avez adopté DevOps. Les changements seront limités à certains micro-services, sans impact sur les autres services de l'application. On peut donc procéder à des centaines de livraisons par semaine, comme le font déjà les GAFA (Google Amazon, Facebook, Apple).
Par contraste, les applications conçues antérieurement à Docker fonctionnent sur un petit nombre de VM, voire une seule. Tout composant de l'application (front-end, serveur d'application, back-end) s'exécute au sein de cette ou ces VM. La machine virtuelle est donc toujours taillée en fonction du pic de charge et seul l'hyperviseur pourra récupérer des ressources lorsque l'application est en attente.
Notez que la haute disponibilité n'est pas encore assurée par Docker. Il faut donc utiliser des solutions externes comme les clusters systèmes, solutions traditionnelles mais éprouvées, ou plus innovantes telles que Google Kubernetes ou Mesosphere. Ces solutions permettront aux équipes informatiques des grandes organisations d’utiliser Docker pour les applications les plus exigeantes en termes de disponibilité.
Autre solution innovante : Nanocloud. Cette start-up française peut transformer une application classique en solution web, que l’éditeur pourra administrer comme une solution SaaS native. NanoCloud vise les éditeurs de logiciels principalement, mais aussi les grandes entreprises, propriétaires de patrimoines applicatifs importants. Nanocloud dispose aussi d'une offre "Community", solution fonctionnant sur le modèle open-source, et offrant aux développeurs une boîte à outils DevOps.
J'ai donc finalement mis en évidence dans cet article quatre axes majeurs dans la transformation des systèmes d'information, permettant de gérer la transition d'un système traditionnel vers un système dans le cloud :
-
Le premier est de construire un cloud privé. Il n'a pas besoin d'être complet ni d'embarquer tout le SI, bien au contraire. Cette étape a deux intérêts majeurs : elle permet de se préparer à migrer vers un cloud hybride ou public, et l'entreprise peut bénéficier de tous les avantages du Cloud et notamment son élasticité et son automatisation.
-
Le second est d'utiliser les services de son cloud pour mettre en oeuvre Docker. Cet outil vous permettra de vous affranchir des dépendances logicielles qui gênent la migration de vos applications. Docker supportera par ailleurs vos applications bâties sur des micro-services.
-
Le troisième est de développer ou migrer en parallèle ses applications en utilisant des micro-services basés sur une architecture WOA et sur Docker.
-
Enfin, profiter du déploiement de Docker pour faciliter l'éclosion des pratiques DevOps au sein de sa DSI, et ainsi accélérer les mises en production des nouvelles fonctions et fiabiliser les déploiements.
Le Cloud Computing, Docker, DevOps et les micros-services, probablement le quarté gagnant des prochaines années en matière de SI...

